[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
一、前言
之前使用原生的 Python 库去爬取网页信息,经常要使用正则表达式,笔者记性不是很好,经常经常忘记相关符号及其作用。
后来使用著名的 Scrapy 框架去爬取信息,感觉太笨重了,特别是一个项目开发到一半,要引入爬虫功能,再使用 Scrapy,就不是那么友好了,其本身就是一个 Web Project。
近来使用一个和之前 Java 爬虫特别简单好使的 Jsoup 框架极其类似的 Beautiful Soup
引入也很简单:
# Python 2+
pip install beautifulsoup4
# Python 3+
pip3 install beautifulsoup4- 1
- 2
- 3
- 4
- 5
使用 Python 爬虫体验当然是比 Java 要好,java开发有点 “做作” —— 每一步都极其格式化(面向对象),Python 则运用自如。
二、需求
现在要爬取 CSDN首页 的今日推荐的 文章 标题 及其 链接,
2.1.这是网页目标内容
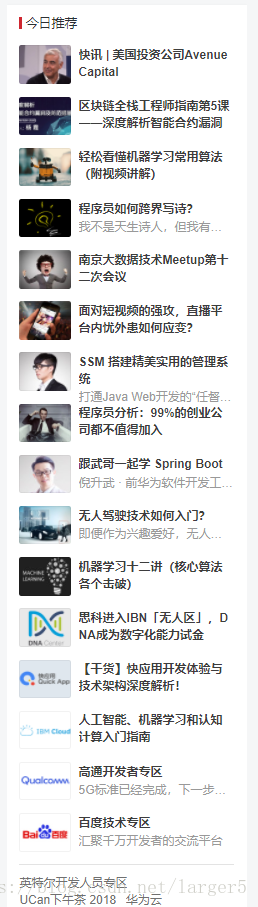
2.2.这是网页目标内容对应的源码

三、实践
你猜需要多少行代码,没错,就这几行,就是这么牛逼。
因力求精简,笔者为此费了几个小时通读官方 API 文档数遍。
3.1.代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://www.csdn.net/").read().decode('utf-8')
soup = BeautifulSoup(html,"html.parser")
titles=soup.select("h3[class='company_name'] a") # CSS 选择器
for title in titles:
print(title.get_text(),title.get('href'))# 标签体、标签属性- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2.效果

四、小结
参考文献:
Beautiful Soup 中文文档
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息的更多相关文章
- python爬虫之Beautiful Soup基础知识+实例
python爬虫之Beautiful Soup基础知识 Beautiful Soup是一个可以从HTML或XML文件中提取数据的python库.它能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档 ...
- Python爬虫之Beautiful Soup解析库的使用(五)
Python爬虫之Beautiful Soup解析库的使用 Beautiful Soup-介绍 Python第三方库,用于从HTML或XML中提取数据官方:http://www.crummv.com/ ...
- python 爬虫利器 Beautiful Soup
python 爬虫利器 Beautiful Soup Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文 ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python爬虫库-Beautiful Soup的使用
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,简单来说,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性. 如在上一篇文章通过爬虫 ...
- python爬虫之Beautiful Soup的基本使用
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- python标准库Beautiful Soup与MongoDb爬喜马拉雅电台的总结
Beautiful Soup标准库是一个可以从HTML/XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup将会节省数小 ...
- python 爬虫5 Beautiful Soup的用法
1.创建 Beautiful Soup 对象 from bs4 import BeautifulSoup html = """ <html><head& ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
随机推荐
- Java 面向对象(三)
封装 什么是封装 面向对象三大特征之一 1. 把对象的状态和行为看成一个统一的整体,将字段和方法放到一个类中. 2. 信息隐藏:把不需要让外界知道的信息隐藏起来.尽可能隐藏对象功能实现细节,向外界暴露 ...
- sklearn.GridSearchCV选择超参
from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.model ...
- 【MyEclipse初级】Web项目的访问路径更改
背景:MyEclipse 开发的Web项目,发布Web项目到Tomcat,从浏览器访问路径配置和工程名称一致,思考是否可以自定义访问虚拟路径. 目标:修改访问Web项目的虚拟路径 步骤:工程名右键-& ...
- 分享调试SI4432的一些小经验(转)
分享调试SI4432的一些小经验 最近使用 STM8F103 + SI4432 调无线,遇到问题不少,此处有参考过前辈的经验: 1.硬件把板给到我时USB烧录线带供电(5V),此供电接到LDO输出,就 ...
- 自定义ObjectAnimator属性实现
package com.loaderman.customviewdemo; import android.animation.ObjectAnimator; import android.graphi ...
- 重装GUI前备份GUI配置
sap系统要重装, gui配置 想要保存,这个要怎么弄? SAP菜单 选项-> 本地数据 -> 历史记录 里的地址 C:\Users\Administrator\AppData\Roam ...
- c#子线程执行完怎么通知主线程(转)
定义一个委托实现回调函数 public delegate void CallBackDelegate(string message); 程序开始的时候 //把回调的方法给委托变量 CallBackDe ...
- easyui-datagrid配置宽度高度自适应
在style属性中,去除之前添加的width和height属性(如果有的话),然后添加"fit:false"即可.
- Ubuntu LVS DR模式生产环境部署
1.环境说明 系统版本:ubuntu14.04 LVS服务器:14.17.64.3 真实服务器:14.17.64.4-12 VIP:14.17.64.13 部署目的:用户请求14.17.64.13的报 ...
- 【ARM-Linux开发】Wi-Fi 应用工具wpa_supplicant
wpa_supplicant是一个跨平台的无线安全管理软件,这里需要用它来对无线网络进行配置,wpa_supplicant相关工具已经移植好,包含在我们提供的文件系统中. 配置无线网络 wpa_sup ...