scrapy 增量采集
在做新闻或者其它文章采集到时候,只想采集最新发布的信息,之前采集过得就不要再采集了,从而达到增量采集到需求
scrapy-deltafetch,是一个用于解决爬虫去重问题的第三方插件。
scrapy-deltafetch通过Berkeley DB来记录爬虫每次爬取收集的request和item,当重复执行爬虫时只爬取新的item,从而实现爬虫的增量爬取。
安装 scrapy-deltafetch需要安装Berkeley DB ,scrapy-deltafetch 会对每个采集源单独建立一个数据库文件来记录已采集过的记录,如下图,会在爬虫项目下建立一个.scrapy的文件夹

安装 Berkeley DB
# cd /opt
# wget http://download.oracle.com/berkeley-db/db-4.7.25.NC.tar.gz
# tar zxvf db-4.7.25.NC.tar.gz # cd build_unix
# ../dist/configure
# make&&make install
安装 pip install bsddb3 用来连接 Berkeley DB
pip install scrapy-deltafetch
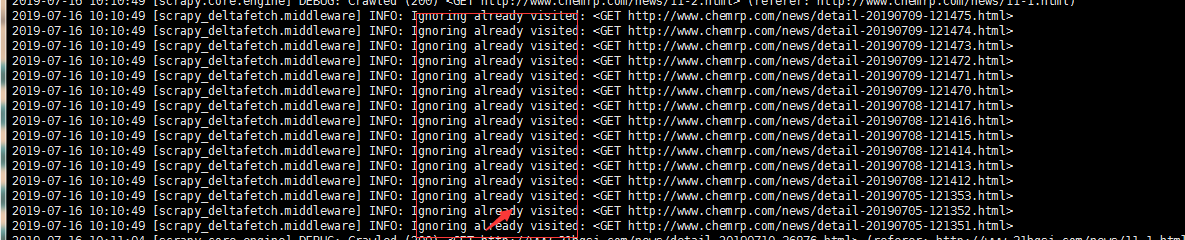
运行爬虫后如果已经采集过的数据会提示,如下图
scrapy 增量采集的更多相关文章
- Scrapy 增量式爬虫
Scrapy 增量式爬虫 https://blog.csdn.net/mygodit/article/details/83931009 https://blog.csdn.net/mygodit/ar ...
- 36.scrapy框架采集全球玻璃网数据
1.采集目标地址 https://www.glass.cn/gongying/sellindex.aspx 网站比较简单,没什么大的需要注意的问题.2.通过分析测试 https://www.glass ...
- scrapy增量爬取
开始接触爬虫的时候还是初学Python的那会,用的还是request.bs4.pandas,再后面接触scrapy做个一两个爬虫,觉得还是框架好,可惜都没有记录都忘记了,现在做推荐系统需要爬取一定的 ...
- scrapy新浪天气
一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: LX终端(LXTermin ...
- flume日志采集
1. Log4j Appender 1.1. 使用说明 1.1.2. Client端Log4j配置文件 (黄色文字为需要配置的内容) log4j.rootLogger=INFO,A1,R # C ...
- python3 scrapy+Crontab部署过程
背景 最近有时间想学习下python3+scrapy,于是决定写一个小程序来练练手. 开发环境:MacOS High Sierra(10.13.1)+python3+scrapy. 开发工具:PyCh ...
- Scrapy实战篇(五)之爬取历史天气数据
本篇文章我们以抓取历史天气数据为例,简单说明数据抓取的两种方式: 1.一般简单或者较小量的数据需求,我们以requests(selenum)+beautiful的方式抓取数据 2.当我们需要的数据量较 ...
- 42.scrapy爬取数据入库mongodb
scrapy爬虫采集数据存入mongodb采集效果如图: 1.首先开启服务切换到mongodb的bin目录下 命令:mongod --dbpath e:\data\db 另开黑窗口 命令:mongo. ...
- Scrapy使用示例
很多网站都提供了浏览者本地的天气信息,这些信息是如何获取到的呢,方法有很多种,大多是利用某些网站提供的天气api获取的,也有利用爬虫采集的.本文就介绍如何用Scrapy来采集天气信息(从新浪天气频道采 ...
随机推荐
- Spark2.4源码阅读1-Shuffle机制概述
本文参考: a. https://www.jianshu.com/p/c46bfaa5dd15 1. shuffle及历史简介 shuffle,即"洗牌",所有采用map-redu ...
- 码云配置WebHook自动更新
配置项目提交到git的时候自动同步服务器代码 一.在服务器项目跟目录新建文件hook.php 代码如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 <?php $json = ...
- Unity Shader基础:编译指令
UntiyShader中,编译指令分为两种: 1.顶点片元着色器(Vetex & Fragment Shader)使用的编译指令 2.表面着色器(Surface Shader)使用的编译指令 ...
- KVM虚拟机的热迁移---Live Migration
KVM虚拟机的热迁移---Live Migration: 服务器虚拟化技术是当前的热点,而虚拟机的“热迁移(Live Migration)”技术则是虚拟机的运行状态完整保存下来,同时可以快速的回复到原 ...
- manjaro-VM虚拟机vmmon错误
1.安装AUR : vmware-systemd-serverices 2.启动服务: systemctl enable vmware.service systemctl start vmware.s ...
- pytest.mark.parametrize()参数化应用二,读取json文件
class TestEnorll(): def get_data(self): """ 读取json文件 :return: """ data ...
- 【计算机视觉】Opencv中的Face Detection using Haar Cascades
[计算机视觉]Opencv中的Face Detection using Haar Cascades 标签(空格分隔): [图像处理] 声明:引用请注明出处http://blog.csdn.net/lg ...
- IO阻塞模型、IO非阻塞模型、多路复用IO模型
IO操作主要包括两类: 本地IO 网络IO 本地IO:本地IO是指本地的文件读取等操作,本地IO的优化主要是在操作系统中进行,我们对于本地IO的优化作用十分有限 网络IO:网络IO指的是在进行网络操作 ...
- 提示ORA-28000 the account is locked
1.启动项目的时候提示ORA-28000 the account is locked. 2. 这是因为用户被锁定了. 查询FAILED_LOGIN_ATTEMPTS参数默认值,这个参数限制了从第一次登 ...
- Redis 数据结构 & 原理 & 持久化
一 概述 redis是一种高级的key-value数据库,它跟memcached类似,不过数据可以持久化,而且支持的数据类型也很丰富. Redis支持五种数据类型:string(字符串),hash(哈 ...