python爬虫3之去哪儿网
学习任务
获取去哪儿网的出发地列表
获取旅游景点列表
获取景点产品列表
存储数据
1 获取出发地站点
(1)访问touch.qunar.com
(2)按F12,单击自由行,在自由行页面点击搜索框


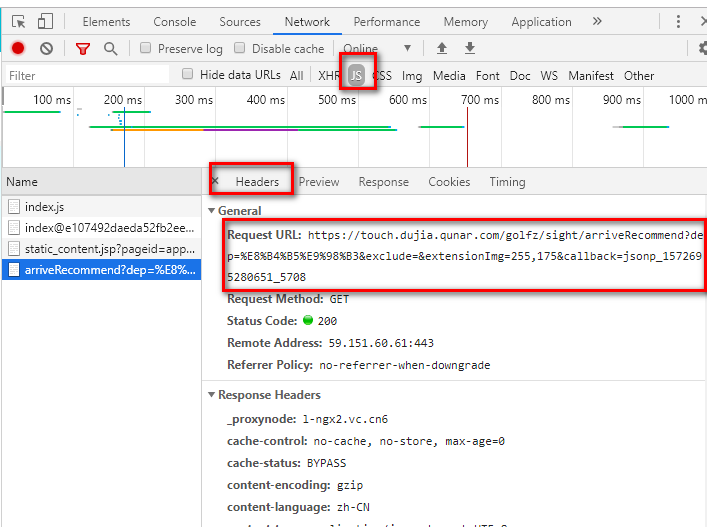
(3)单击任意一个城市,切换到headers,查看request URL如下所示。但是需要工具还原编码咋们才能知道这是啥(dep参数表示出发地,query表示目的地)。推荐网站http://www.jsons.cn/urlencode/,解码效果下面图2
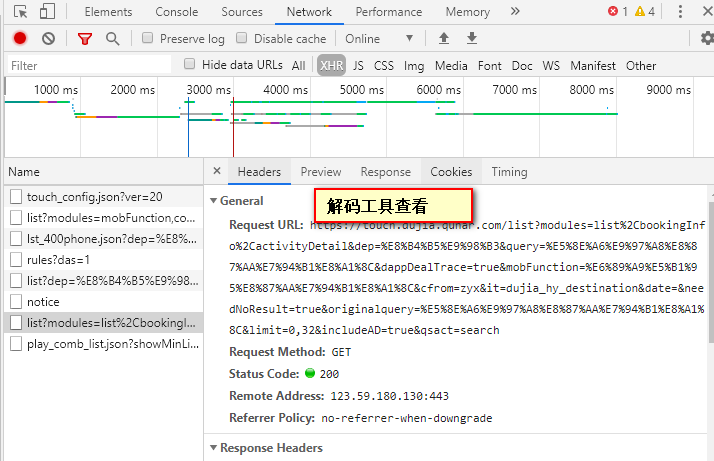

3 实现
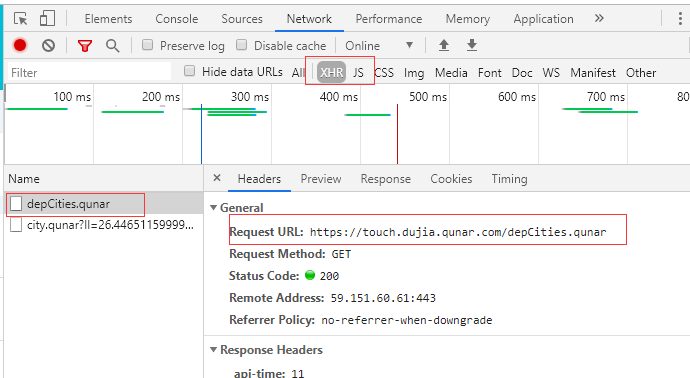
(1)首先获得出发地站点,因为最终需要获得整个自由行的产品列表。
自由行首页中点击左侧的出发点站点,然后获取目标URL如图二

import requests
url="https://touch.dujia.qunar.com/depCities.qunar" strhtml=requests.get(url)
print(strhtml)
dep_dict=strhtml.json()
print(dep_dict)
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
print(dep)
(2)获得目的地。根据上面的分析,json工具解码以后通过拼接可得URL。
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
(3)总源码
import requests
import urllib
import time
#import pymongo # client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# sheet_qunar_zyx=book_qunar['qunar_zyx'] #获取产品列表
def get_list(dep,item):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit=0,20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item), urllib.request.quote(item))
strhtml = get_json(url)
try:
routeCount = int(strhtml['data']['limit']['routeCount'])
except:
return
for limit in range(0, routeCount, 20):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit={},20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item),
urllib.request.quote(item), limit)
strhtml = get_json(url)
result = {
'date': time.strftime('%Y-%m-%d', time.localtime(time.time())),
'dep': dep,
'arrive': item,
'limit': limit,
'result': strhtml
}
#sheet_qunar_zyx.insert_one(result)
print(result) # def connect_mongo():
# client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# return book_qunar['qunar_zyx'] def get_json(url):
strhtml=requests.get(url)
time.sleep(1)
return strhtml.json() if __name__ == "__main__": url='https://touch.dujia.qunar.com/depCities.qunar'
dep_dict=get_json(url)
#这里是json格式 dep_dict中内嵌勒一层
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
a = []#目的地去重
#经过解码工具可以得到dep表示出发地 query和originalquery表示目的地
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
arrive_dict = get_json(url)
for arr_item in arrive_dict['data']:
for arr_item_1 in arr_item['subModules']:
for query in arr_item_1['items']:
if query['query'] not in a:
a.append(query['query'])
for item in a:
get_list(dep,item)
python爬虫3之去哪儿网的更多相关文章
- 用python爬虫爬取去哪儿4500个热门景点,看看国庆不能去哪儿
前言:本文建议有一定Python基础和前端(html,js)基础的盆友阅读. 金秋九月,丹桂飘香,在这秋高气爽,阳光灿烂的收获季节里,我们送走了一个个暑假余额耗尽哭着走向校园的孩籽们,又即将迎来一年一 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- Python爬虫入门教程 34-100 掘金网全站用户爬虫 scrapy
爬前叨叨 已经编写了33篇爬虫文章了,如果你按着一个个的实现,你的爬虫技术已经入门,从今天开始慢慢的就要写一些有分析价值的数据了,今天我选了一个<掘金网>,我们去爬取一下他的全站用户数据. ...
- Python爬虫入门教程 11-100 行行网电子书多线程爬取
行行网电子书多线程爬取-写在前面 最近想找几本电子书看看,就翻啊翻,然后呢,找到了一个 叫做 周读的网站 ,网站特别好,简单清爽,书籍很多,而且打开都是百度网盘可以直接下载,更新速度也还可以,于是乎, ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- Python爬虫入门教程 20-100 慕课网免费课程抓取
写在前面 美好的一天又开始了,今天咱继续爬取IT在线教育类网站,慕课网,这个平台的数据量并不是很多,所以爬取起来还是比较简单的 准备爬取 打开我们要爬取的页面,寻找分页点和查看是否是异步加载的数据. ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
随机推荐
- 解决Android8.0系统应用打开webView报错
由于webView存在安全漏洞,谷歌从5.1开始全面禁止系统应用使用webview,使用会导致应用崩溃错误提示:Caused by: java.lang.UnsupportedOperationExc ...
- siblings,next,prev
同胞拥有相同的父元素. 通过 jQuery,您能够在 DOM 树中遍历元素的同胞元素. 在 DOM 树中水平遍历 siblings() next() nextAll() nextUntil() pre ...
- Centos 6.5出现yum安装慢的情况
最近在用Centos 6.5 的时候出现了这种情况, Loaded plugins: fastestmirror, refresh-packagekit, security Loading mirro ...
- 51Node1228序列求和 ——自然数幂和模板&&伯努利数
伯努利数法 伯努利数原本就是处理等幂和的问题,可以推出 $$ \sum_{i=1}^{n}i^k={1\over{k+1}}\sum_{i=1}^{k+1}C_{k+1}^i*B_{k+1-i}*(n ...
- Thread线程框架学习
原文:https://www.cnblogs.com/wangkeqin/p/9351299.html Thread线程框架 线程定义:线程可以理解为一个特立独行的函数.其存在的意义,就是并行,避免了 ...
- 洛谷P3534 [POI2012] STU
题目 二分好题 首先用二分找最小的绝对值差,对于每个a[i]都两个方向扫一遍,先都改成差满足的形式,然后再找a[k]等于0的情况,发现如果a[k]要变成0,则从他到左右两个方向上必会有两个连续的区间也 ...
- Java int 与 Integer 区别
学习借鉴(其实搬了别人的好多)和自己的理解,可能会有较多错误,如有疑问联系我呀. int 是基本数据类型, Integer 是引用类型,也就是一个对象. int 储存的是数值,Integer 储存的 ...
- 「PKUSC2018」PKUSC
传送门 Solution 考虑求每个点的贡献 等价于一个以OA长为半径的圆心为原点的圆在多边形内的弧对应的角度/\(2\pi\) 求弧度可以利用三角剖分 在原点的点要特判,采用射线法就可以了 Cod ...
- webpack系列之安装(Mac OS)
1. webpack介绍,可参考Webpack中文文档 2. 安装webpack之前先需要安装npm,可参看NPM的使用介绍 3. 安装webpack,可参考Webpack入门教程 ========= ...
- fluent运行过程中转换边界
我们以一个简单的VOF算例来说明,算例模型如下: 算例中空气为主相,水为次相.开始时刻,inlet_one设置为速度入口边界,速度为1m/s,且水的体积分数为100%,inlet_two设置为速度入口 ...