KMeans聚类
常用的聚类方法:
①分裂方法:
K-Means算法(K-平均)、K-MEDOIDS算法(K-中心点)、CLARANS算法(基于选择的算法)
②层次分析方法:
BIRCH算法(平衡迭代规约和聚类)、CURE算法(代表点聚类)、CHAMELEON算法(动态模型)
③基于密度的方法:
DBSCAN(基于高密度连接区域)、DENCLUE算法(密度分布函数)、OPTICS算法(对象排序识别)
④基于网格的方法:
STING算法(统计信息网络)、CLIOUE算法(聚类高维空间)、WAVE-CLUSTRE(小波变换)
⑤基于模型的方法:
统计学方法、神经网络方法
其中Kmeans、K中心点、系统聚类比较常用。
KMeans:K-均值聚类也叫快速聚类法,在最小化误差函数的基础上将数据划分为预定的类数K。该算法原理简单并便于处理大量的数据。
K中心点:K-均值算法对孤立点的敏感性,K-中心点算法不采用簇中对象的平均值作为簇中心,而选用簇中离平均值最近的对象作为簇中心。
系统聚类:系统聚类也叫多层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其所包含的对象就越少,但这些对象间的共同特征越多。该聚类方法只适合在小数据量的时候使用,数据量大的时候处理速度会非常慢。
KMeans聚类
K-Means:在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
算法描述
①从N个样本数据中随机选取K个对象作为初始的聚类中心。
②分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中。
③所有对象分配完成后,重新计算K个聚类的中心。
④与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转第②步。
⑤当质心不发生变化时停止并输出聚类结果。
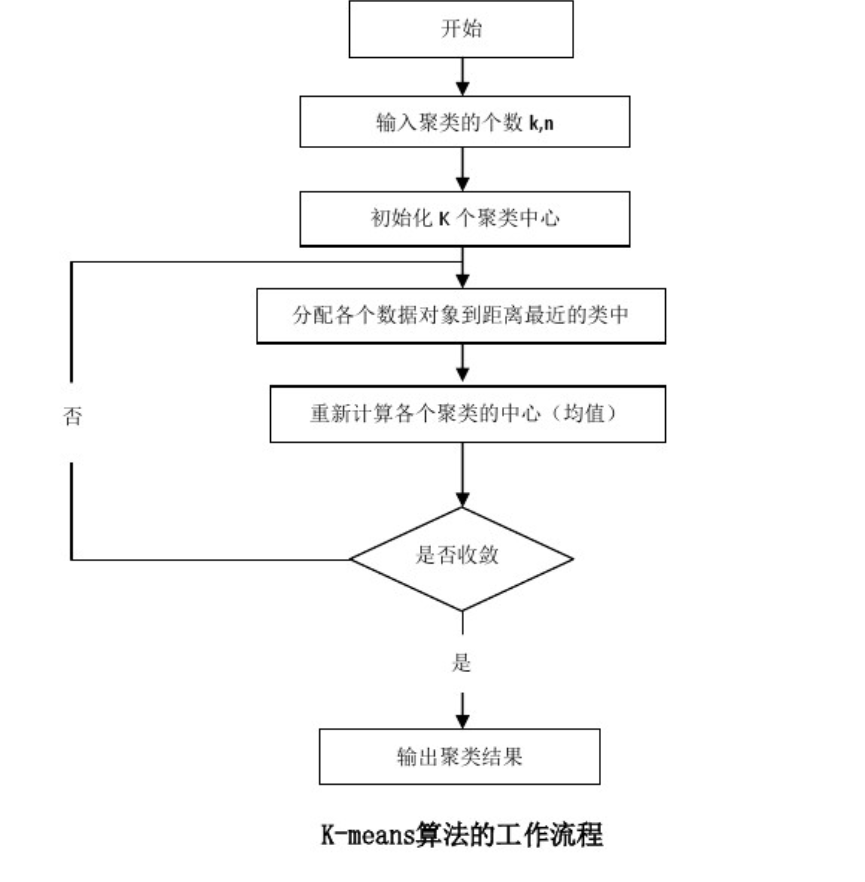
聚类的结果可能依赖于初始聚类中心的随机选择,可能使得结果严重偏离全局最优分类。在实践中为了得到较好的结果,通常以不同的初始聚类中心,多次运行K-Means算法。在所有对象分配完成后,重新计算K个聚类的中心时,对于连续数据聚类中心取该簇的均值。
数据类型与属性度量
对于连续属性,要先对各属性值进行0-均值规范,再进行距离的计算。K-Means 聚类算法中,一般需要度量样本之间的距离、样本与簇之间的距离以及簇与簇之间的距离。
样本之间的相似性最常用的是欧几里得距离、曼哈顿距离和闵可夫斯基距离。
样本与簇之间的距离可以用样本到簇中心的距离$d\left(e_{i,}, x\right)$
簇与簇之间的距离可以用簇中心的距离$d\left(e_{i}, e_{j}\right)$
用p个属性来表示n个样本的数据矩阵:$$\left[\begin{array}{ccc}{x_{11}} & {\cdots} & {x_{1 p}} \\ {\vdots} & {} & {\vdots} \\ {x_{n 1}} & {\cdots} & {x_{n p}}\end{array}\right]$$
欧几里得距离的计算公式为:$$d(i, j)=\sqrt{\left(x_{i 1}-x_{j 1}\right)^{2}+\left(x_{i 2}-x_{j 2}\right)^{2}+\cdots+\left(x_{i p}-x_{j p}\right)^{2}}$$
曼哈顿距离的计算公式为:$$d(i, j)=\left|x_{i+}-x_{j 1}\right|+\left|x_{2}-x_{j 2}\right|+\cdots+\left|x_{i p}-x_{i p}\right|$$
闵可夫斯基距离的计算公式为:$$d(i, j)=\sqrt[q]{\left|\left(x_{i 1}-x_{j 1} |\right)^{q}+\left(\left|x_{i 2}-x_{j 2}\right|\right)^{q}+\cdots+\left(\left|x_{i p}-x_{j p}\right|\right)^{q}\right.}$$
q为正整数,q=1时为曼哈顿距离;q=2时为欧几里得距离。
对于文档数据,使用余弦相似性度量,先将文档数据整理成文档一词矩阵格式。
两个文档之间的相似度的计算公式为:$d(i, j)=\cos (i, j)=\frac{\vec{i} g \vec{j}}{|\vec{i}| g|\vec{j}|}$
目标函数
使用误差平方和SSE(残差平方和)作为度量聚类质量的目标函数,对于两种不同的聚类结果,可选择误差平方和较小的分类结果。
连续属性的SSE计算公式为:$$S S E=\sum_{i=1}^{K} \sum_{x \in E_{i}} \operatorname{dist}\left(e_{i,} x\right)^{2}$$
文档数据的SSE计算公式为:$$S S E=\sum_{i=1}^{K} \sum_{x \in E_{i}} \cos i n e\left(e_{i}, x\right)^{2}$$
簇$E_{i}$的聚类中心$e_{i}$的计算公式为:$$e_{i}=\frac{1}{n_{i}} \sum_{\dot{x} \in E_{i}} x$$
$K$表示聚类簇的个数,$E_{i}$表示第$i$个簇,$x$表示样本,$e_{i}$表示聚类中心,$n$表示数据集中样本的个数,$n_{i}$表示第$i$个簇中样本的个数。
例子
根据顾客的一些消费行为特性数据,将顾客进行聚类,并评价不同顾客群体的价值。
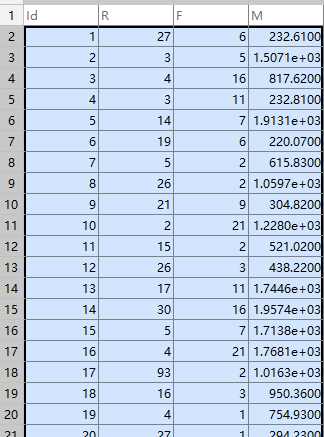
采用K-Means聚类算法,设定聚类个数K为3,最大迭代次数为500次,距离函数取欧氏距离。
%% 使用K-Means算法聚类消费行为特征数据
clear ;
% 参数初始化
inputfile = '../data/consumption_data.xls'; % 销量及其他属性数据
k = ; % 聚类的类别
iteration = ; % 聚类最大循环次数
distance = 'sqEuclidean'; % 距离函数
%% 读取数据
[num,txt]=xlsread(inputfile);
data = num(:,:end);
%% 数据标准化
data = zscore(data);
%% 调用kmeans算法
opts = statset('MaxIter',iteration);
[IDX,C,~,D] = kmeans(data,k,'distance',distance,'Options',opts);
%% 打印结果
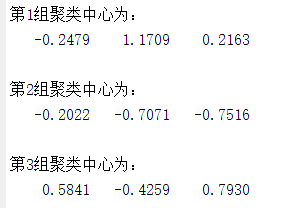
for i=:k
disp(['第' num2str(i) '组聚类中心为:']);
disp(C(i,:));
end
disp('K-Means聚类算法完成!');
计算得到聚类中心为:
KMeans聚类的更多相关文章
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- 用scikit-learn学习K-Means聚类
在K-Means聚类算法原理中,我们对K-Means的原理做了总结,本文我们就来讨论用scikit-learn来学习K-Means聚类.重点讲述如何选择合适的k值. 1. K-Means类概述 在sc ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- K-means聚类算法
聚类分析(英语:Cluster analysis,亦称为群集分析) K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般.最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中, ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 利用KMeans聚类进行航空公司客户价值分析
准确的客户分类的结果是企业优化营销资源的重要依据,本文利用了航空公司的部分数据,利用Kmeans聚类方法,对航空公司的客户进行了分类,来识别出不同的客户群体,从来发现有用的客户,从而对不同价值的客户类 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
随机推荐
- 45、[源码]-Spring容器创建-执行BeanFactoryPostProcessor
45.[源码]-Spring容器创建-执行BeanFactoryPostProcessor 5.invokeBeanFactoryPostProcessors(beanFactory);执行BeanF ...
- ASCII和Unicode编码的区别
归纳: 编码 大小 支持语言 ASCII 1个字节 英文 Unicode 2个字节(生僻字4个) 所有语言 UTF-8 1-6个字节,英文字母1个字节,汉字3个字节,生僻字4-6个字节 所有语言 具体 ...
- 爬虫与seo优化
爬虫及爬行方式 爬虫有很多名字,比如web机器人.spider等,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序.web爬虫是一种机器人,它们会递归地对各种信息性的web站点 ...
- qml 3d 纪念那些曾经爬过的坑
1.使用多position画图时,图形不受控制的问题? 在变量属性设置时Attribute中的attributeBaseType 数据类型一定要和 Buffer中data 数据类型一定要相同. 例如 ...
- 配置Spring Data Redis
事前准备 1.下载redis https://github.com/MicrosoftArchive/redis/releases/tag/win-3.2.100 2.下载redis可视化工具 htt ...
- codeforces425C
http://codeforces.com/contest/425/problem/C 题意:两数列a[],b[],进行若干轮操作,每次操作花费e, 将a的一个前缀和b的一个前缀(两前缀的最后一个数字 ...
- 对C#中事件的简单理解
对于C#中的事件,我举了个简单的例子来理解事件及其处理. 这个例子中母亲是事件的发布者,事件是吃饭了.儿子和父亲是事件的订阅者,各自的Eat方法是处理事件的方法. 下面是详细的加注的例子: using ...
- python3 系统监控脚本(CPU,memory,网络,disk等)
#!/usr/bin/env python3 #create at 2018-11-30 'this is a system monitor scripts' __author__="yjt ...
- checkbox后台传个list显示和回显的页面代码C标签
<c:forEach items="${listtest}" var="provinces"> <input type= ...
- LeetCode 第 149 场周赛
成绩 一.一年中的第几天(LeetCode-1154) 1.1 题目描述 1.2 解题思路 比较容易的一题,搞清楚平年.闰年的判定规则,就很容易做出来. 1.3 解题代码 class Solution ...