伪分布式安装Hadoop
Hadoop简单介绍
Hadoop:适合大数据分布式存储与计算的平台。
Hadoop两大核心项目:
1、HDFS:Hadoop分布式文件系统
HDFS的架构: 主从结构:
主节点,只有一个:namenode
1、接收用户操作请求
2、维护文件系统的目录结构
3、管理文件与block之间关系,block与datanode之间关系
从节点,有很多个:datanodes
1、存储文件
2、文件被分成block存储在磁盘上
3、为保证数据安全,文件会有多个副本
2、MapReduce:并行计算框架
MapReducede的架构:主从结构:
主节点,只有一个:JobTracker
1、接收客户端提交的计算任务
2、把计算任务分给TaskTrackers执行
3、监控TaskTracker的执行情况
从节点,有很多个:TaskTrackers
执行JobTracker分配的计算任务
Hadoop的特点:
1、扩容能力
2、成本低
3、高效率
4、可靠性
Hadoop部署方式:
1、本地模式
2、伪分布模式
3、集群模式
安装前准备软件:
1、Vitual Box/VMWare
2、centOS
3、jdk-6u24-linux-xxx.bin
4、hadoop-1.1.2.tar.gz
1.hadoop的伪分布安装
1.1 设置ip地址
执行命令 service network restart
验证: ifconfig
1.2 关闭防火墙
执行命令 service iptables stop
验证: service iptables status
1.3 关闭防火墙的自动运行
执行命令 chkconfig iptables off
验证: chkconfig --list | grep iptables //过滤出iptables
1.4 设置主机名(按下面这两步进行)
执行命令 (1)hostname chaoren //设置当前主机名为chaoren,但是重启系统后会失效
(2)vi /etc/sysconfig/network //编辑文件设置主机名,重启后不会失效
1.5 ip与hostname绑定
执行命令 vi /etc/hosts //在文件下面增加一行 192.168.80.100 chaoren
验证: ping chaoren
1.6 设置ssh免密码登陆
执行命令 (1)ssh-keygen -t rsa //一直回车即可
(2)cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
验证: ssh chaoren
**************
windows与Linux之间传输文件工具: WinSCP
安装好,打开设置: 主机名:192.168.56.100 用户名:root 密码:hadoop
然后点击保存,勾选上保存密码,然后双击连接登录。
将左侧Windows下的文件,拖动复制到右侧Linux下的目录/usr/local下。
**************
1.7 安装jdk
执行命令 (1)cd /usr/local
(2)chmod u+x jdk-6u24-linux-i586.bin //增加执行的权限
(3)./jdk-6u24-linux-i586.bin //解压
(4)mv jdk-1.6.0_24 jdk //重命名
(5)vi /etc/profile 增加内容如下:
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
(6)source /etc/profile //刷新环境变量
验证: java -version (改变后,OpenJdk就变成了oracle下的jdk了)
1.8 安装hadoop
执行命令 (1)tar -zxvf hadoop-1.1.2.tar.gz //解压
(2)mv hadoop-1.1.2 hadoop //重命名
(3)vi /etc/profile 修改环境变量,增加内容如下:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
(4)source /etc/profile
(5)修改conf目录下的配置文件(直接在WinSCP中编辑修改保存)
hadoop-env.sh:
export JAVA_HOME=/usr/local/jdk/
core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://主机名:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>主机名:9001</value>
</property>
</configuration>
(6)hadoop namenode -format //存储之前,要对文件系统进行格式化
(7)start-all.sh
验证: (1)执行命令jps 如果看到5个新的java进程,分别是NameNode、SecondaryNameNode、DataNode、JobTracker、TaskTracker
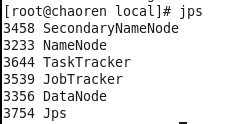
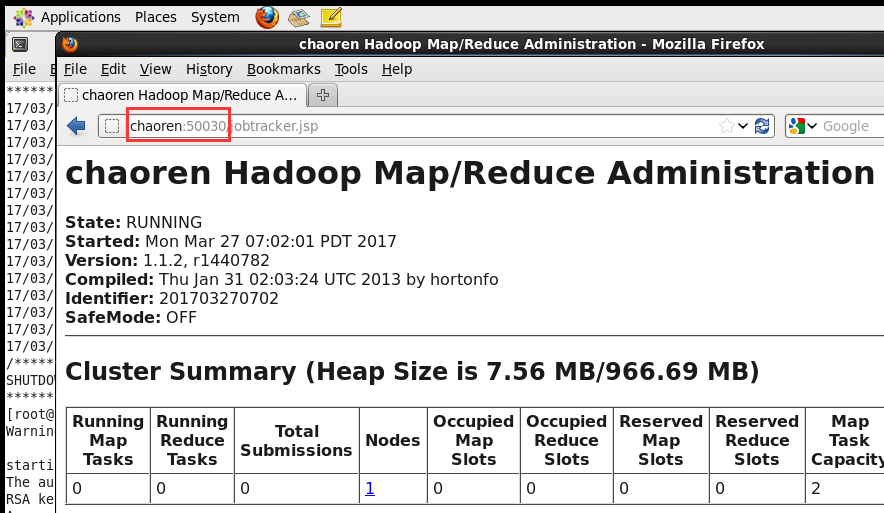
(2)在浏览器查看,http://chaoren:50070 http://chaoren:50030

1.9 启动时没有NameNode的可能原因:
(1)没有格式化
(2)环境变量设置错误
(3)ip与hostname绑定失败
伪分布式安装Hadoop的更多相关文章
- 指导手册02:伪分布式安装Hadoop(ubuntuLinux)
指导手册02:伪分布式安装Hadoop(ubuntuLinux) Part 1:安装及配置虚拟机 1.安装Linux. 1.安装Ubuntu1604 64位系统 2.设置语言,能输入中文 3.创建 ...
- 第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试.所以我们讲下伪分布式安装hadoop. 我们继续上一章继续讲解,安装完先试试SSH装 ...
- CentOS 6.5 伪分布式 安装 hadoop 2.6.0
安装 jdk -openjdk* 检查安装:java -version 创建Hadoop用户,设置Hadoop用户使之可以免密码ssh到localhost su - hadoop ssh-keygen ...
- Hadoop单机和伪分布式安装
本教程为单机版+伪分布式的Hadoop,安装过程写的有些简单,只作为笔记方便自己研究Hadoop用. 环境 操作系统 Centos 6.5_64bit 本机名称 hadoop001 本机IP ...
- hadoop 2.7.3伪分布式安装
hadoop 2.7.3伪分布式安装 hadoop集群的伪分布式部署由于只需要一台服务器,在测试,开发过程中还是很方便实用的,有必要将搭建伪分布式的过程记录下来,好记性不如烂笔头. hadoop 2. ...
- Hadoop入门进阶课程1--Hadoop1.X伪分布式安装
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
- hadoop 0.20.2伪分布式安装详解
adoop 0.20.2伪分布式安装详解 hadoop有三种运行模式: 伪分布式不需要安装虚拟机,在同一台机器上同时启动5个进程,模拟分布式. 完全分布式至少有3个节点,其中一个做master,运行名 ...
- Hadoop大数据初入门----haddop伪分布式安装
一.hadoop解决了什么问题 hdfs 解决了海量数据的分布式存储,高可靠,易扩展,高吞吐量mapreduce 解决了海量数据的分析处理,通用性强,易开发,健壮性 yarn 解决了资源管理调度 二. ...
随机推荐
- Redis集群部署(redis + cluster + sentinel)
概述说明 说明:本次实验采用c1.c2.c3三台虚拟机完成,每台服务器上都部署一个master.一个slave和一个sentinel.当某主节点的挂了,相应的从节点替位:当某主节点及主节点对应的从节点 ...
- Jdbc druid数据库连接池
//测试类package druid; import util.JdbcUtilsDruid; import java.sql.Connection; import java.sql.Date; im ...
- Java解决LeetCode72题 Edit Distance
题目描述 地址 : https://leetcode.com/problems/edit-distance/description/ 思路 使用dp[i][j]用来表示word1的0~i-1.word ...
- 悲催的IE6 七宗罪大吐槽(带解决方法)第三部分
五:文字溢出bug(注释bug) 1.在以下情况下将会引起文字溢出bug 一个容器包含2两个具有“float”样式的子容器. 第二个容器的宽度大于父容器的宽度,或者父容器宽度减去第二个容器宽度的值小于 ...
- 20155301 2016-2017-2 《Java程序设计》第5周学习总结
20155301 2016-2017-2 <Java程序设计>第5周学习总结 教材学习内容总结 1.1try.catch关键词,在用户不小心输入错误的时候,程序会出现错误信息,将代表错误的 ...
- HDU 1686 Oulipo (KMP 可重叠)
题目链接 Problem Description The French author Georges Perec (1936–1982) once wrote a book, La dispariti ...
- Python练习-猜年龄的LowB游戏
Alex大神今天让我做一个猜年龄的游戏: 第一个游戏是你只能猜三次:真的很LowB啊~ # 编辑者:闫龙 #猜年龄游戏,3次后程序自动退出! ages = 29; #for循环3次 for i in ...
- UNIX网络编程 第6章 I/O复用:select和poll函数
UNIX网络编程 第6章 I/O复用:select和poll函数
- Python Webdriver 重新使用已经打开的浏览器实例
因为Webdriver每次实例化都会新开一个全新的浏览器会话,在有些情况下需要复用之前打开未关闭的会话.比如爬虫,希望结束脚本时,让浏览器处于空闲状态.当脚本重新运行时,它将继续使用这个会话工作.还就 ...
- Flip Bits
Determine the number of bits required to flip if you want to convert integer n to integer m. Notice ...