大数据小白系列——MR(1)
一部编程发展史就是一部程序员偷懒史,MapReduce(下称MR)同样是程序员们用来偷懒的工具。
来了一份大数据,我们写了一个程序准备分析它,需要怎么做?
老式的处理方法不行,数据量太大时,所需的时间无法忍受,所以,必须并行计算。好比1000块砖,1个人搬需要1小时,10个人同时搬,只需要6分钟。
不过进行并行计算,面临几个细思头大问题:
- 如何切分数据
- 如何处理部分任务失败
- 如何对多路计算的结果进行汇总

不过不用担心,世界就是这样的,少部分人发明创造工具,大部分人使用工具。总有聪明人在合适的时候出来解决问题。
Google在2004年出了个paper,《MapReduce: Simplifed Data Processing on Large Clusters》,提出来一种针对大数据的并行处理模型、并基于此理论做了一个计算框架。
所以,你可以说MR是一种计算模型、也可以叫它一个计算框架。广义的MR甚至还包括一套资源管理(JobTracker、TaskTracker),后面这个我们不讲,因为,过,时,了。
Q 框架是什么?
A 就是套路。内部会帮你处理那些让你头大的问题。
作为小白系列,我们先来看看MR简单的流程图:
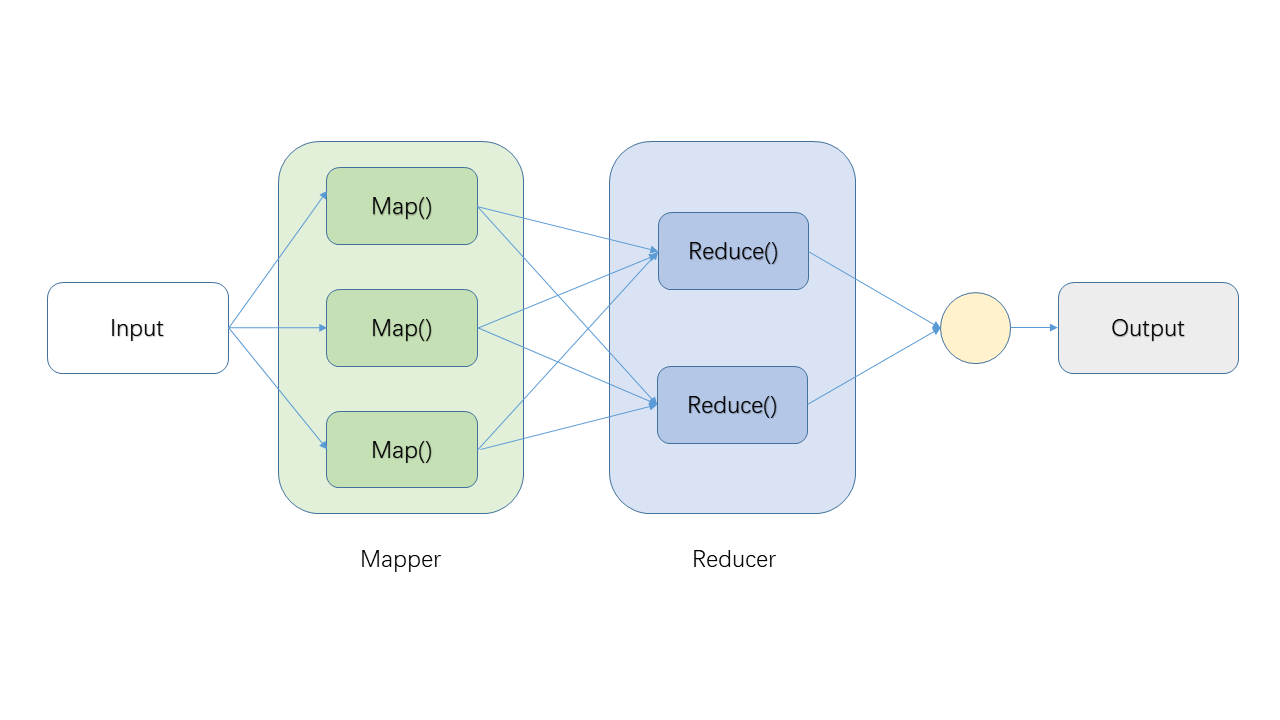
为方便理解,来一个WorkCount示例(WordCount就好比大数据的HelloWorld,总要来一个的)。假设我们有一个文件包含内容:
Live for nothing, die for something
统计每一个单词出现的次数:

Q Splitting是怎么做的,分成几份?
A 框架决定(通常是文件有多少个数据块,就分成几份,数据块不懂的回去看HDFS系列)。
Q k1,v1是什么?
A 一般来说,k1是行号(在WordCount示例中用不到),v1是文件的某一行。本例只是概念示例,不用纠结。
Q Mapping产生的结果存储在哪里?
A 所在机器的本地文件系统,非HDFS,以避免产生多余的副本(HDFS默认多个副本)。
Q Shuffling是做什么的?
A 负责将Mapping产生的中间结果发给Reducer,哪些数据发个哪个Reducer,有框架决定。
Q Reducer有几个,运行在哪些机器上?
A 框架决定。
Q 哪些是需要程序员进行代码实现的?
A Mapping及Reducing,即图中两个红框部分。
好了,这期就先说到这,下期将稍微深入了解一下MR中的Shuffling、Sorting等概念。Cheers!
—END—
欢迎关注“程序员杂书馆”公众号,领取大数据经典纸质书。

大数据小白系列——MR(1)的更多相关文章
- 大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation. 首先,我们先要来个直观的印象,这是你以为的Hadoop集群: ...
- 大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念. 上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机 ...
- 大数据小白系列——HDFS(2)
这里是大数据小白系列,这是本系列的第二篇,介绍一下HDFS中SecondaryNameNode.单点失败(SPOF).以及高可用(HA)等概念. 上一篇我们说到了大数据.分布式存储,以及HDFS中的一 ...
- 大数据小白系列——HDFS(1)
[注1:结尾有大福利!] [注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对.] 大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
随机推荐
- Java编程的分期步骤(一)
日期:2018.8.12 星期一 博客期:005 不知不觉来到第五期了,先简单说一下Java环境!(虽然Java都自学完了才说....)首先,就是在网站上下载一个java包,之后把它下载到全英文的一个 ...
- Ubuntu shutdown now 关机后 开机黑屏
一重装gdm3 失败 sudo apt-get remove --purge nvidia-* # 卸载nvidia相关组件 sudo apt purge gdm gdm3 # 卸载gdm和 ...
- Intenet 地址
java.net.InetAddress类是java对Ip地址(包括ipv4和ipv6)的高层表示,大多数其他网络类都要用到这个类,包括Socket, ServerSocket, URL, Datag ...
- hdu1213并查集
板子题不多说,上代码 #include<iostream> #include<cstdio> #include<cstring> using namespace s ...
- Django中各目录文件的作用
一般的项目结构如下(大同小异) my_site是一个项目,blog是项目下的应用之一,可以使用创建命令创建更多的应用. 最上层的django文件夹: 自己手动创建,名字随意. 第二层my_site文件 ...
- vue指令问题
挂载点:最外层标签就是vue实例的挂载点,即id或者类对应的 dom节点 模板:指挂载点内部的内容,在实例里使用template标签来构 建 h1标签放在body里面不使用 “template”是一样 ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- 学习REST
REST:Representational State Transfer,资源的表现状态转换.可以理解为对资源的操作. 1. 资源 资源就是业务对象,如图片.文本.歌曲或者客户.交易等.这些是用户 ...
- HTML CSS JavaScript 工作笔记
1. onclick方法如何传递多个参数 "<a href='#' onclick=\"applied_status('" + ids + "', '&q ...
- Lua中assert( )函数的使用
当Lua遇到不期望的情况时就会抛出错误,比如:两个非数字进行相加:调用一个非函数的变量:访问表中不存在的值等.你也可以通过调用error函数显示的抛出错误,error的参数是要抛出的错误信息. ass ...