大数据小白系列——HDFS(2)
这里是大数据小白系列,这是本系列的第二篇,介绍一下HDFS中SecondaryNameNode、单点失败(SPOF)、以及高可用(HA)等概念。
上一篇我们说到了大数据、分布式存储,以及HDFS中的一些基本概念,为了能更好的理解后续介绍的内容,这里先补充介绍一下NameNode到底是怎么存储元数据的。

首先,在启动的时候,将磁盘中的元数据文件读取到内存,后续所有变化将被直接写入内存,同时被写入一个叫Edit Log的磁盘文件。(如果你熟悉关系型数据库,这个Edit Log有点像Oracle Redo Log,这是题外话)。
Q: 为什么不把这些变化直接写到磁盘上的元数据中,使磁盘上的元数据保持最新呢?Edit Log是不是多此一举?
A: 这个主要是基于性能考虑,由于对Edit Log的写是“顺序写”(追加),对元数据的写是“随机写”,两者在磁盘上表现出来的性能有相当大的差异。有兴趣的同学可以搜索学习一下磁盘相关原理哦。
上面这个方案,带来了一些明显的副作用。
- NameNode长期运行,不停地向Edit Log追加内容,导致它变得巨大无比。
- NameNode在重启时,需要使用Edit Log更新元数据文件,当Edit Log太大时,这一步骤就会耗费很长的时间。
为了消除这些副作用,HDFS中引入了另外一个角色,SecondaryNameNode。
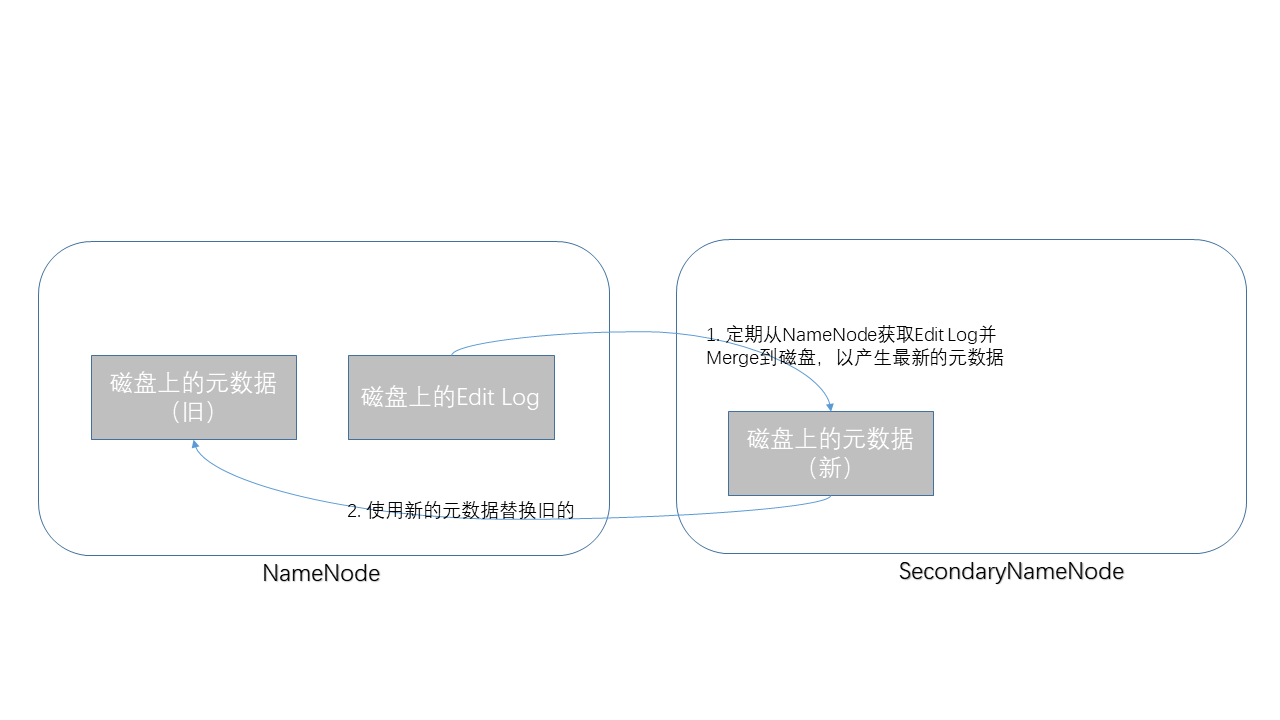
它定期(比如每小时)从NameNode上抓取Edit Log,使用它更新元数据文件,并把最新的元数据文件写回到NameNode。
说完了SecondaryNameNode的职责之后,大家应该明白,它并不是一个“备用NameNode”,其实这是典型的命名不当,它应该被命名成“Checkpoint NameNode”才比较恰当。
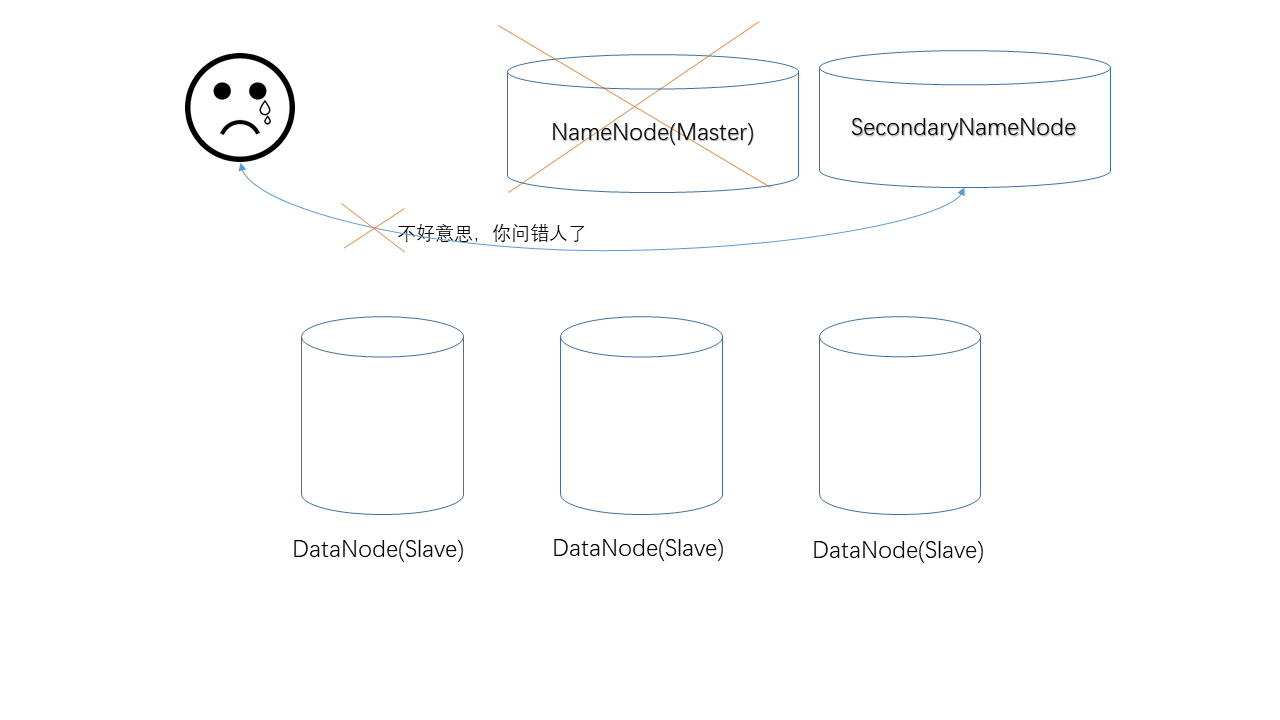
接下来我们来说说HDFS中的单点失败问题(SPOF, Single Point Of Failure),即,当NameNode掉线之后,整个HDFS集群就变得不可用了。为解决这个问题,Hadoop 2.0中真正引入了一个“备用NameNode”。
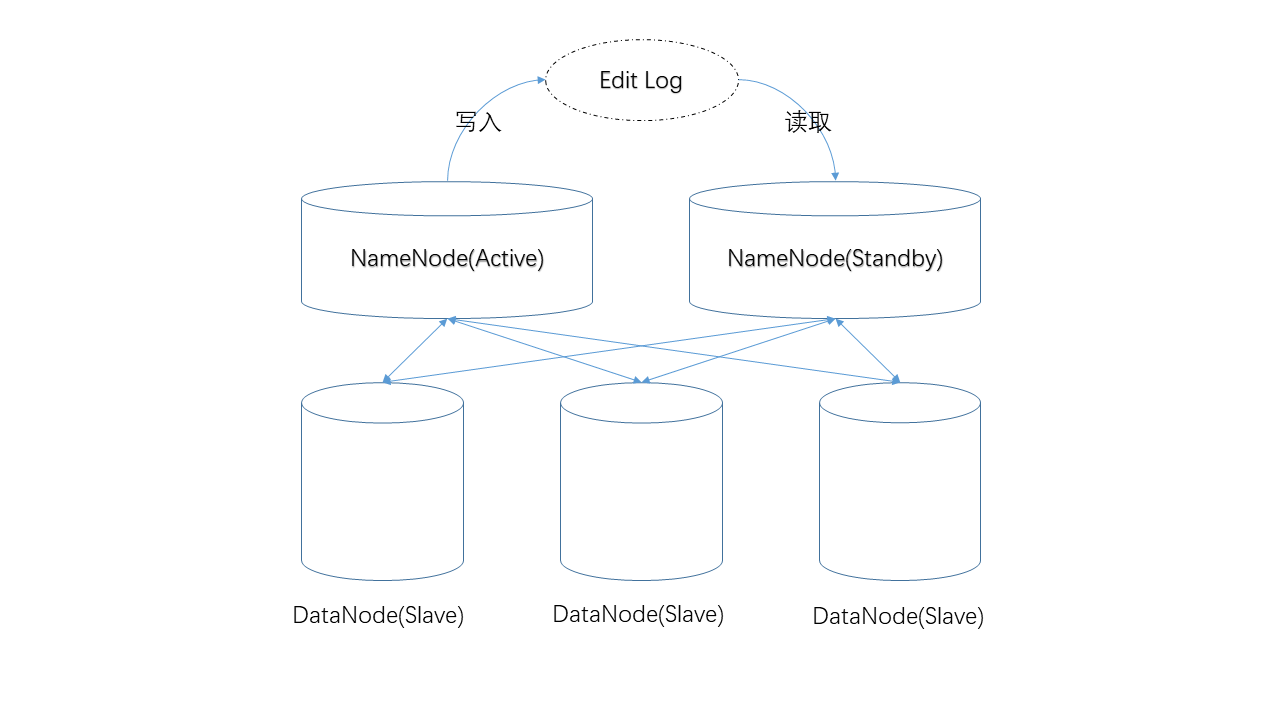
- 对元数据的修改首先发生在NameNode,并被写入某个“共享位置”,备用NameNode将从该位置获取Edit Log。
- DataNode节点们同时向两台NameNode汇报状态。
由于这两点,两台NameNode上的元数据将一直保持同步。这将保证当NameNode掉线后,用户可以立即切换到备用NameNode,系统将保持可用。
由于备用NameNode比较空闲(不用处理用户请求),系统又给它安排了另外一份工作——定期使用Edit Log更新元数据文件,也就是说它接手了SecondaryNameNode的工作。
所以,在HA环境中,我们就不再需要SecondaryNameNode了。
今天就到这里,下一篇准备介绍JournalNode、NameNode选举等概念,Cheers!
公众号“程序员杂书馆”,专注大数据,欢迎关注,每位关注者将获赠《Spark快速大数据分析》纸质书一本!


大数据小白系列——HDFS(2)的更多相关文章
- 大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation. 首先,我们先要来个直观的印象,这是你以为的Hadoop集群: ...
- 大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念. 上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机 ...
- 大数据小白系列——HDFS(1)
[注1:结尾有大福利!] [注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对.] 大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件 ...
- 大数据小白系列——MR(1)
一部编程发展史就是一部程序员偷懒史,MapReduce(下称MR)同样是程序员们用来偷懒的工具. 来了一份大数据,我们写了一个程序准备分析它,需要怎么做? 老式的处理方法不行,数据量太大时,所需的时间 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- Confluence 6 后台中为站点添加应用导航
Confluence 6 后台中为站点添加应用导航的连界面和方法. https://www.cwiki.us/display/CONFLUENCEWIKI/Configuring+the+Site+H ...
- django模板导入外部js和css等文件
1.新建文件夹templates(存放模板文件),新建文件夹media(存放js.css.images文件夹),并把两个文件夹放到了项目的根目录下 2.设定模板路径 设置模板路径比较简单,只要在set ...
- LeetCode(92):反转链表 II
Medium! 题目描述: 反转从位置 m 到 n 的链表.请使用一趟扫描完成反转. 说明:1 ≤ m ≤ n ≤ 链表长度. 示例: 输入: 1->2->3->4->5-&g ...
- Python基础之继承与派生
一.什么是继承: 继承是一种创建新的类的方式,新建的类可以继承一个或过个父类,原始类成为基类或超类,新建的类则称为派生类 或子类. 其中,继承又分为:单继承和多继承. class parent_cla ...
- java爬虫笔记
一.URl解释 1.URl统一资源定位符, Uniform Resource Location 也就是说是Internet上信息资源的字符串,所谓的网页抓取就是把URl地址中指定的网络资源从网络中读取 ...
- JavaScript实现的抛物线运动效果
css88 技术文档地址: http://www.css88.com/archives/5355 张鑫旭 技术文档地址: https://www.zhangxinxu.com 使用示例: 使用时直接引 ...
- const 和 const_cast
对于const变量,我们不能修改它的值,这是这个限定符最直接的表现.但是我们就是想违背它的限定希望修改其内容怎么办呢?下边的代码显然是达不到目的的: ; int modifier = constant ...
- Nginx限制下载速度
http { limit_conn_zone $binary_remote_addr zone=one:10m; #容器共使用10M的内存来对于IP传输开销 server { lis ...
- python---自己来打通节点,链表,栈,应用
但,, 没有调试通过. 思路是对的,立此存照. 关键就是用链表完全实现列表的功能, 替换了就应该OK的. # coding = utf-8 # 节点初始化 class Node: def __init ...
- org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for /eclipse20171118
1:如果有一天,你有幸看到了这个错误,也许你像我一样low,因为此时,你已经准备开发Zookeeper程序了,却还没有把Zookeeper的服务启动起来. org.apache.zookeeper.K ...