python网络爬虫与信息提取 学习笔记day1
Day1:
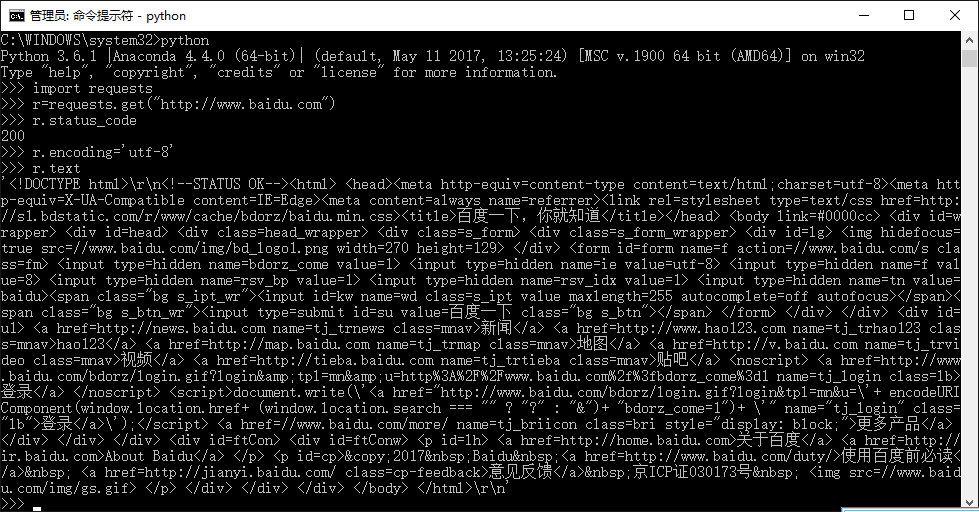
安装python之后,为其配置requests第三方库,并爬取百度主页内容。
语句解释:
r.status_code检测请求的状态码,如果状态码为200,则说明访问成功,否则,则说明访问失败。
注意Response对象的五个属性:
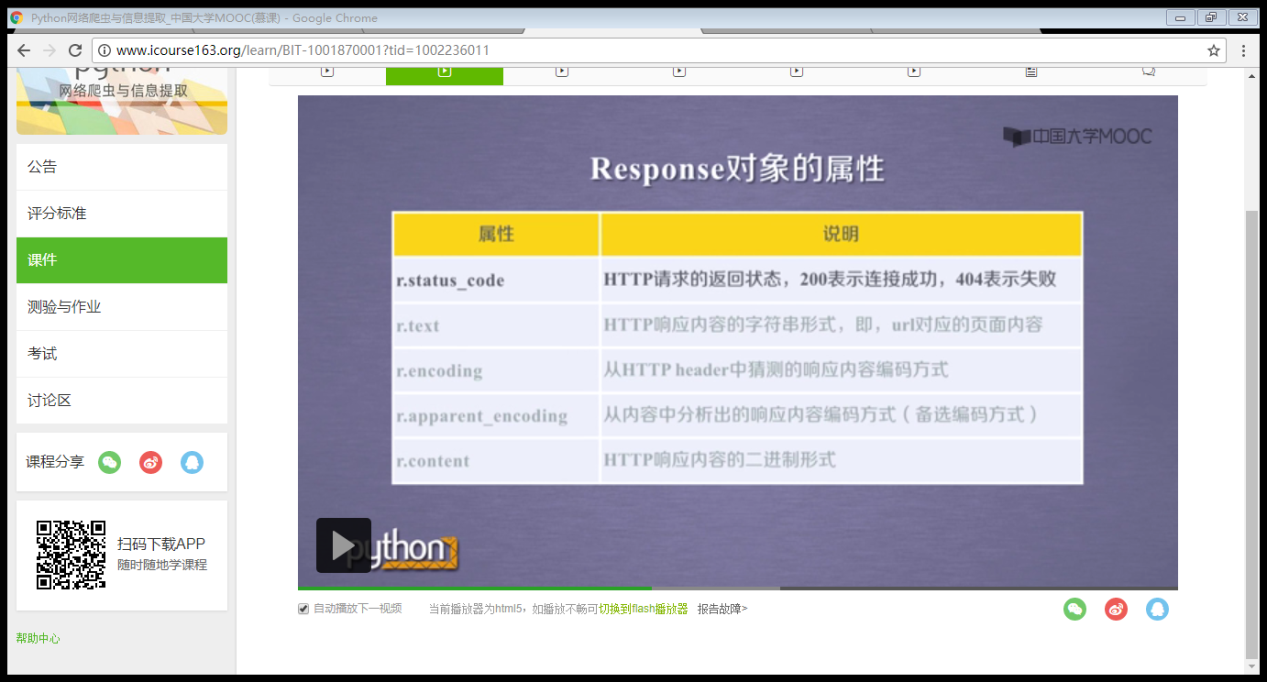
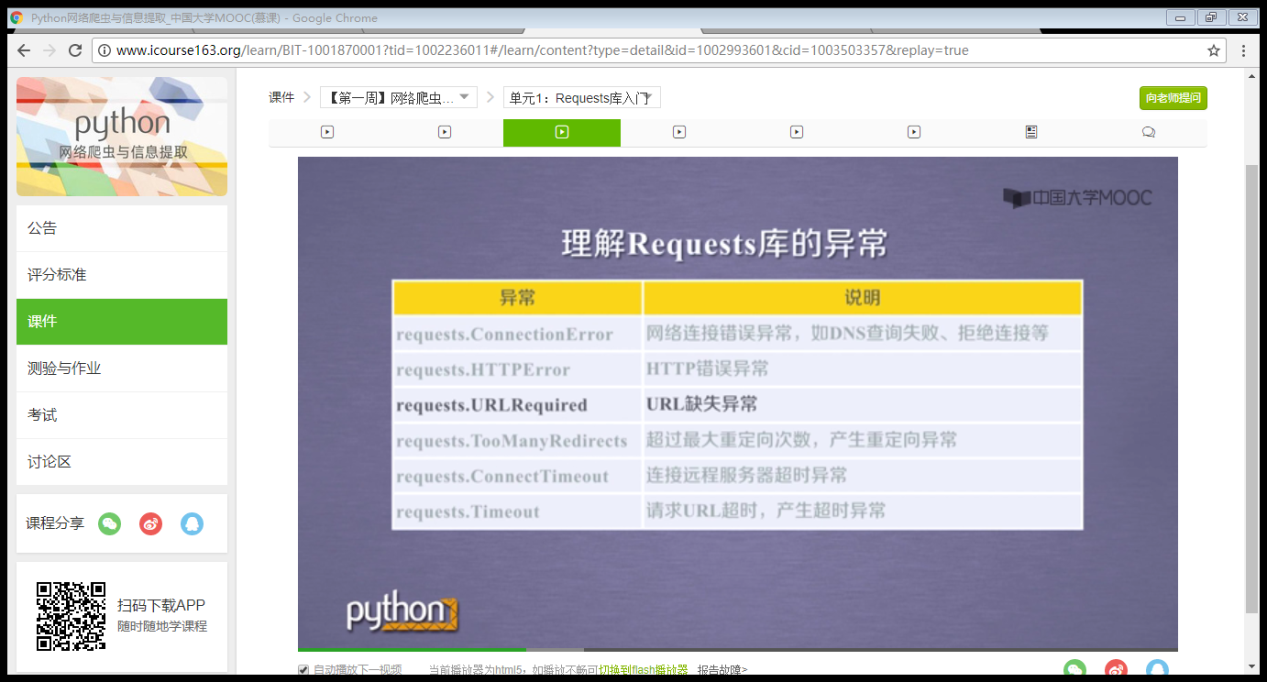
爬取网页的通用代码框架:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
HTTP URL的理解
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
http协议对资源的操作对应requests库的六个操作
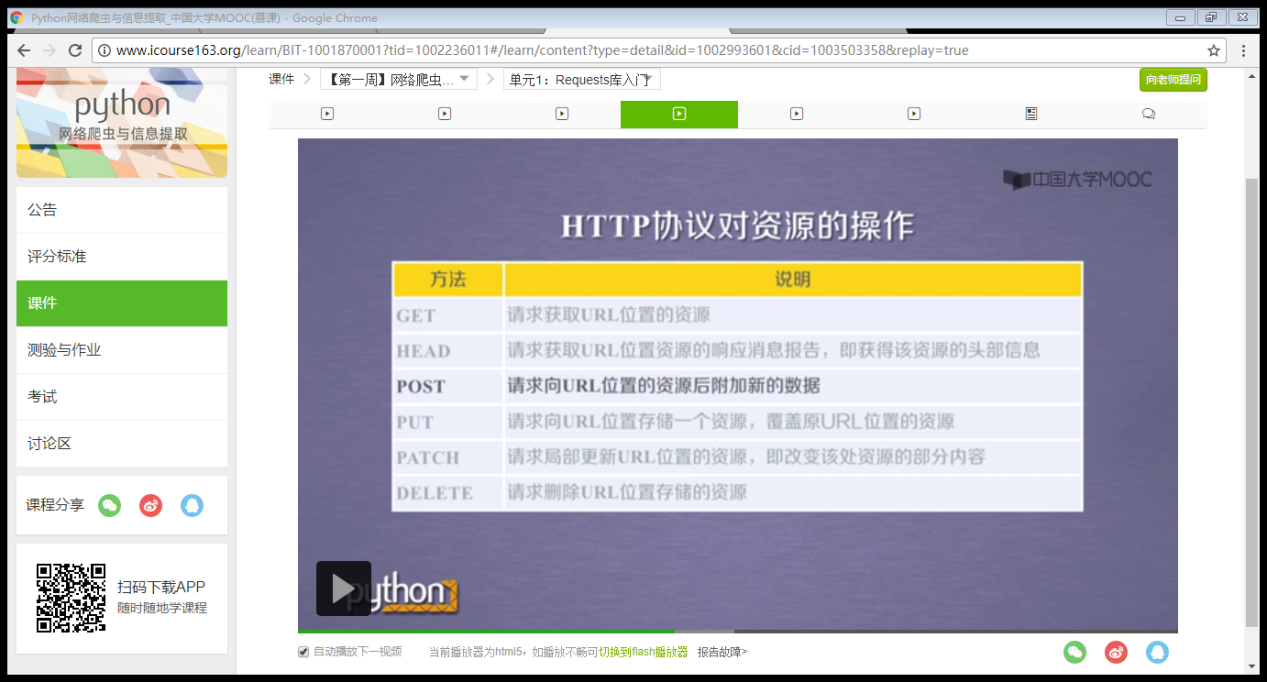
post:向URL POST一个字典,自动编码为form(表单);想URL POST一个字符串,自动编码为data
python网络爬虫与信息提取 学习笔记day1的更多相关文章
- python网络爬虫与信息提取 学习笔记day2
Day2: 查看robots协议: 查看京东的robots协议 查看百度的robots协议,可以看到百度拒绝了搜狗的爬虫233 爬取京东商品页面相关信息: import requests url = ...
- python网络爬虫与信息提取 学习笔记day3
Day3: 只需两行代码解析html或xml信息 具体代码实现:day3_1 注意BeautifulSoup的B和S需要大写,因为python大小写敏感 import requests r ...
- python 网络爬虫与信息提取 学习笔记day4
正则表达式简介: 简洁表示一组字符串的特征或者模式,在文本处理中十分常用,主要应用于字符串匹配中 1. 通用的字符串表达框架 2. 简洁表达一组字符串的表达式 3. 针对字符串表达简洁和特征思想 ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
随机推荐
- 【Unity与23种设计模式】抽象工厂模式(Abstract Factory)
GoF中定义: "提供一个能够建立整个类群组或有关联的对象,而不必指明它们的具体类." 意思就是 根据不同的执行环境产生不同的抽象类子类 抽象工厂模式经常在面试中会涉及到 下面的例 ...
- 在Jenkins中配置执行远程shell命令
1.想要 远程登录到linux服务器并执行相应的shell脚本,需要在jenkins上安装插件enkins SSH plugin 2. 安装了这个插件后,进入系统的配置管理中配置 SSH remote ...
- 谁能用通俗的语言解释一下什么是 RPC 框架?
转载自知乎:https://www.zhihu.com/question/25536695 知乎上很多问题的答案还是很好的,R大就经常在上面回答问题 关于RPC你的题目是RPC框架,首先了解什么叫RP ...
- js--DOM&BOM总结思维导图---2017-03-24
- fail2ban防止SSH暴力破解
[root@kazihuo /srv]# wget https://github.com/fail2ban/fail2ban/archive/0.8.14.tar.gz [root@kazihuo / ...
- java 获取文件内所有文件名
package com.xinwen.user.controller; import java.io.File;import java.util.ArrayList;import java.util. ...
- [POJ1050] To the Max 及最大子段和与最大矩阵和的求解方法
最大子段和 Ο(n) 的时间求出价值最大的子段 #include<cstdio> #include<iostream> using namespace std; int n,m ...
- 第六届蓝桥杯B组java最后一题
10.压缩变换(程序设计) 小明最近在研究压缩算法. 他知道,压缩的时候如果能够使得数值很小,就能通过熵编码得到较高的压缩比. 然而,要使数值很小是一个挑战. 最近,小明需要压缩一些正整数的序列,这些 ...
- svn打分支
http://www.07net01.com/linux/Eclipsexiasvndechuangjianfenzhi_hebing_qiehuanshiyong_548928_1374750252 ...
- servlet的执行过程
第一次访问servlet的过程: 服务器启动:在服务器启动的时候,加载项目,就扫描web.xml文件,获得应用有哪些servlet,url-pattern, 客户端通过URl访问服务器[向服务器发送一 ...