python网络爬虫与信息提取 学习笔记day3
Day3:
只需两行代码解析html或xml信息 具体代码实现:day3_1 注意BeautifulSoup的B和S需要大写,因为python大小写敏感
import requests
r= requests.get("http://python123.io/ws/demo.html")
r.text
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo , "html.parser")
print(soup.prettify())
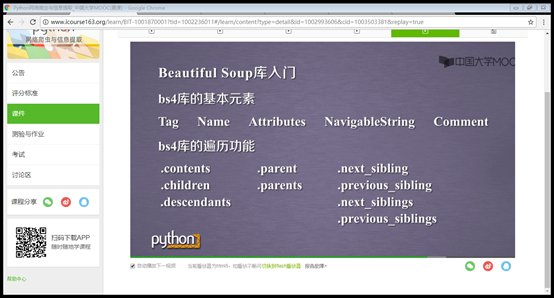
BeautifulSoup库的基本元素:详参html的基本信息
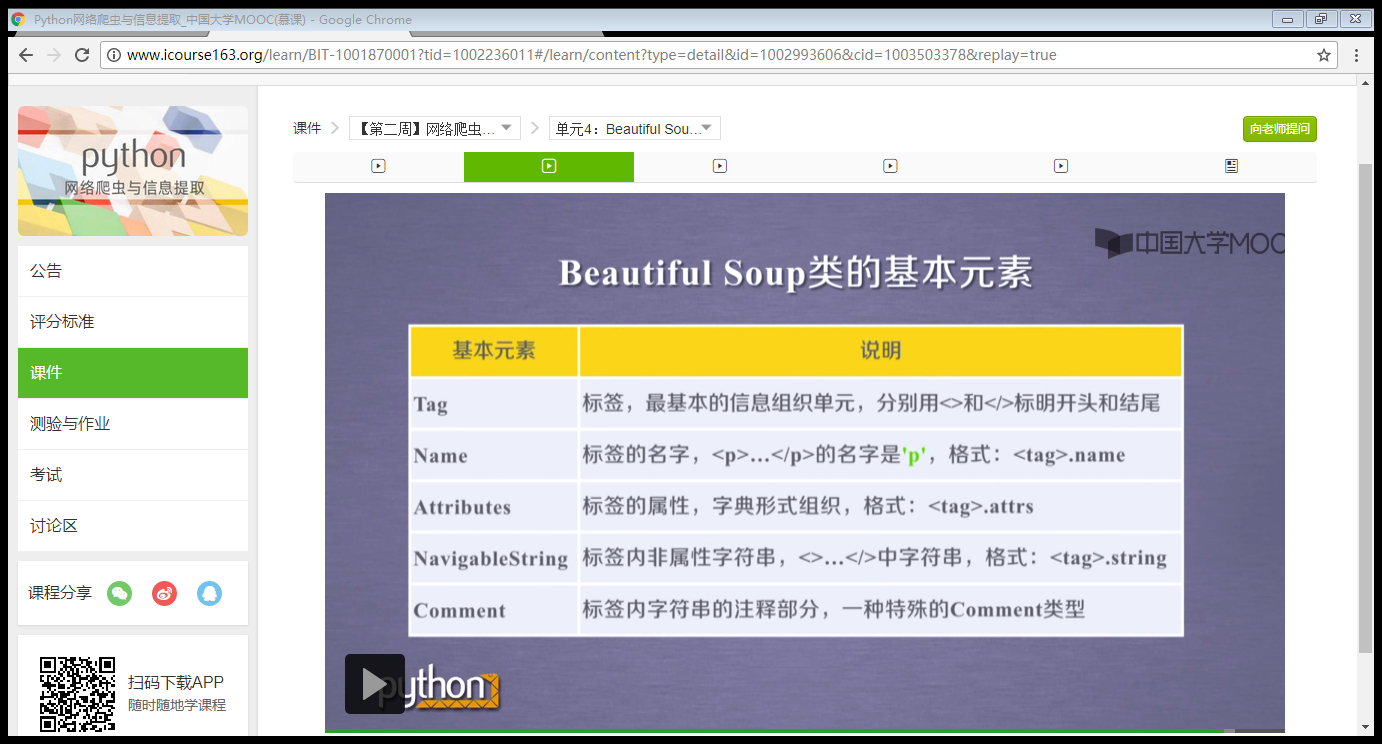
from bs4 import BeautifulSoup 语句含义:从bs4库中引入一个BeautifulSoup的类型

下行遍历,上行遍历和平行遍历:
爬取中国大学排名
import requests
from bs4 import BeautifulSoup
import bs4 def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "" def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string]) def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2])) def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
python网络爬虫与信息提取 学习笔记day3的更多相关文章
- python网络爬虫与信息提取 学习笔记day2
Day2: 查看robots协议: 查看京东的robots协议 查看百度的robots协议,可以看到百度拒绝了搜狗的爬虫233 爬取京东商品页面相关信息: import requests url = ...
- python网络爬虫与信息提取 学习笔记day1
Day1: 安装python之后,为其配置requests第三方库,并爬取百度主页内容. 语句解释: r.status_code检测请求的状态码,如果状态码为200,则说明访问成功,否则,则说明访问失 ...
- python 网络爬虫与信息提取 学习笔记day4
正则表达式简介: 简洁表示一组字符串的特征或者模式,在文本处理中十分常用,主要应用于字符串匹配中 1. 通用的字符串表达框架 2. 简洁表达一组字符串的表达式 3. 针对字符串表达简洁和特征思想 ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
随机推荐
- windows下 python3.5+tensorflow 安装
个人随笔,备忘参考 首先最近的tensorflow 对python3.5.x友好,我先装了Python3.6,查其他的一些博客说出现问题,后来重装3.5.0.下载用迅雷,超快. 安装比较简单,官网下载 ...
- linux的shell学习笔记
shell脚本第一行写明解释器的路径: #!/bin/bash运行脚本两种方式:使用bash命令运行shell文件,或授予脚本文件执行权限,可直接执行文件shell启动时,一开始执行一组命令来定义提问 ...
- EasyUI Parser 解析器
Parser(解析器)应用场景 1,自动调用parser 只要我们书写相应的class,easyui就能成功的渲染页面,这是因为解析器在默认情况下,会在dom加载完成的时候($(docunment). ...
- WordPress评论时一键填入昵称、邮箱和网址
现在很多博客都启用了多说,可是依然有很多博主坚守着wordpress或其主题自带的评论框,这样,每当我们访问这些博客时,发现精彩的内容或者 找到共鸣时.抑或只是想挑逗一下博主,准备在评论处爽爽的来一发 ...
- 20165230 2017-2018-2 《Java程序设计》第3周学习总结
20165230 2017-2018-2 <Java程序设计>第3周学习总结 教材学习内容总结 本周主要学习了类与对象. 包括创建对象与构造方法. 了解了程序是由若干个类所构成:类分为类名 ...
- 如何给自己的外包APP开发报价?
作者:CODING 兄弟,你看做这样一个软件需要多少钱?" 这估计是所有软件从业人员被问的最多也是最无奈的一个问题.这个问题等同于,"你看装修一个100平米的房子需要多少钱?&qu ...
- python函数式编程之yield表达式形式
先来看一个例子 def foo(): print("starting...") while True: res = yield print("res:",res ...
- python变量定义和定义规范
变量定义的规则: 变量名只能是 字母.数字或下划线的任意组合 变量名的第一个字符不能是数字 以下关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', ...
- Mycat 读写分离详解
Mycat 的读写分离是依赖数据库级别的数据主从同步的基础上来实现的(Mysql 的主从配置链接),Mycat 的读写分离是在 schema.xml 配置的 dataHost 节点的 balance ...
- 安装VMware workstation遇到的两个问题:安装过程中的DLL问题和安装后打开需要的管理权限问题
1.安装过程中遇到Microsoft runtime DLL安装程序未能完成安装的问题? 在遇到这个问题时不要点击确定,需要在开始菜单中输入%temp%,然后跳转到一个文件夹里,找到后缀为setup的 ...