十九、Hadoop学记笔记————Hbase和MapReduce
概要:

hadoop和hbase导入环境变量:

要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到:
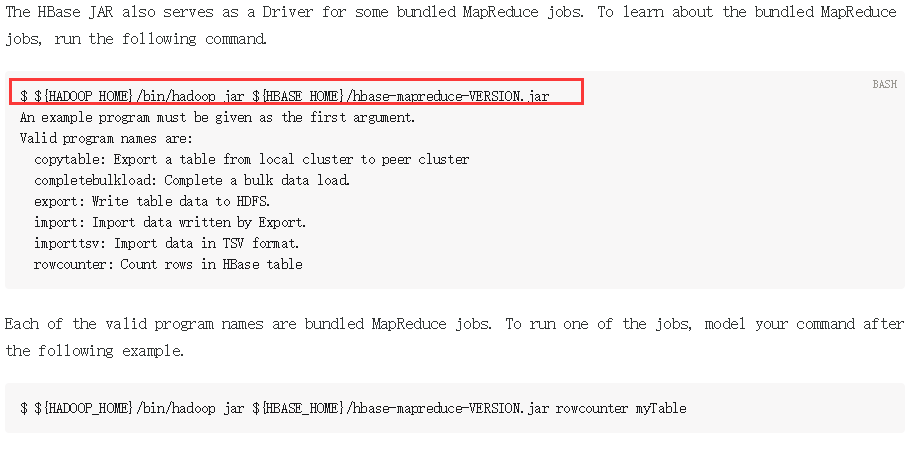
如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问Hbase的jar包:

参考官网可解决:

运行后解决:

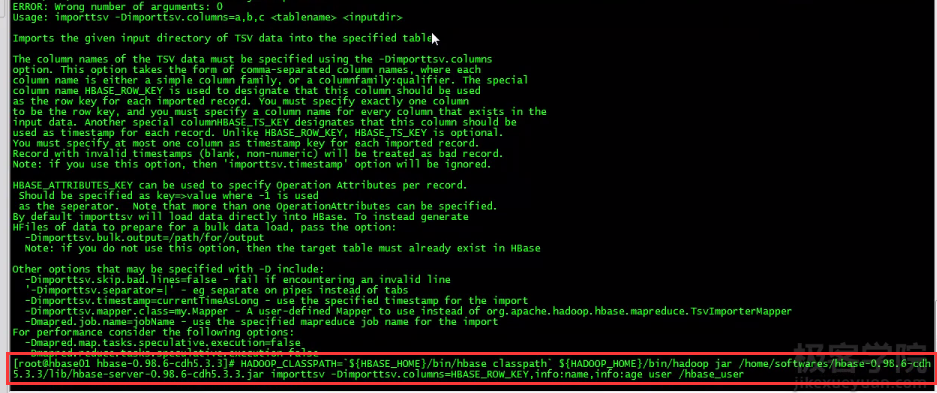
导入数据运行指令:
tsv是指以制表符为分隔符的文件
先创建测试数据,创建user文件:

上传至hdfs,并且启动hbase shell:

创建表:

之后导入数据:
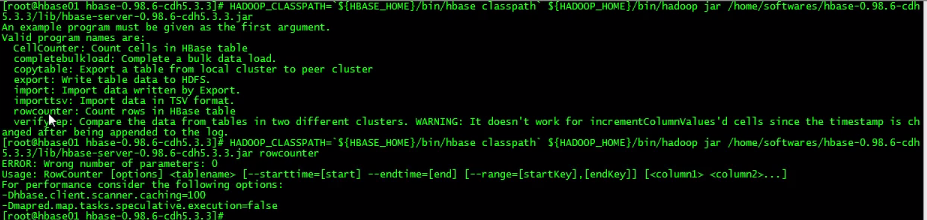
还有一些其他的方法,比如rowcounter统计行数:
接下来演示用sqoop将mysql数据考入hbase,构建测试数据:
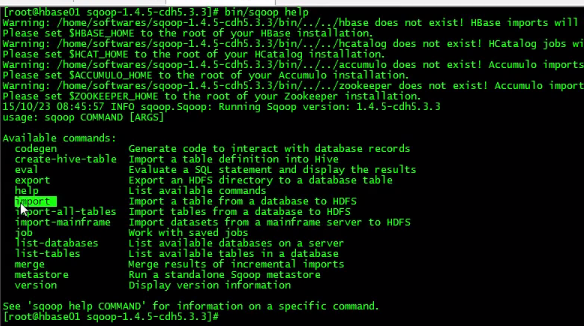
使用import,需要先配置hbase环境变量:


Hbase表数据的迁移:

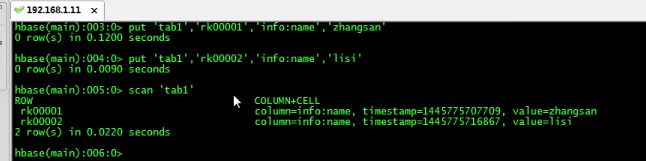
之后编写MapReduce程序,代码如下:
package com.tyx.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class Tab2TabMapReduce extends Configured implements Tool { // mapper class
public static class TabMapper extends TableMapper<Text, Put> {
private Text rowkey = new Text(); @Override
protected void map(ImmutableBytesWritable key, Result value,Context context)
throws IOException, InterruptedException {
byte[] bytes = key.get();
rowkey.set(Bytes.toString(bytes)); Put put = new Put(bytes); for (Cell cell : value.rawCells()) {
// add cell
if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))) {
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
put.add(cell);
}
}
} context.write(rowkey, put);
}
} // reduce class
public static class TabReduce extends TableReducer<Text,Put, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<Put> values,Context context)
throws IOException, InterruptedException {
for (Put put : values) {
context.write(null, put);
} }
} @Override
public int run(String[] args) throws Exception {
//create job
Job job = Job.getInstance(this.getConf(), this.getClass().getSimpleName()); // set run class
job.setJarByClass(this.getClass()); Scan scan = new Scan();
scan.setCaching(500);
scan.setCacheBlocks(false); // set mapper
TableMapReduceUtil.initTableMapperJob(
"tab1", // input table
scan , // scan instance
TabMapper.class, // set mapper class
Text.class, // mapper output key
Put.class, //mapper output value
job // set job
); TableMapReduceUtil.initTableReducerJob(
"tab2" , // output table
TabReduce.class, // set reduce class
job // set job
); job.setNumReduceTasks(1); boolean b = job.waitForCompletion(true); if(!b) {
System.err.print("error with job!!!");
} return 0;
} public static void main(String[] args) throws Exception { //create config
Configuration config = HBaseConfiguration.create(); //submit job
int status = ToolRunner.run(config, new Tab2TabMapReduce(), args); //exit
System.exit(status);
} }
运行指令:


接下来是hdfs中文件导入Hbase:
构造数据:


然后编写MapReduce程序:
package com.jkxy.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class HDFS2TabMapReduce extends Configured implements Tool{ public static class HDFS2TabMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> { ImmutableBytesWritable rowkey = new ImmutableBytesWritable(); @Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { String[] words = value.toString().split("\t");
//rk0001 zhangsan 33 Put put = new Put(Bytes.toBytes(words[0]));
put.add(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(words[1]));
put.add(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(words[2])); rowkey.set(Bytes.toBytes(words[0])); context.write(rowkey, put);
}
} @Override
public int run(String[] args) throws Exception { // create job
Job job = Job.getInstance(this.getConf(), this.getClass().getSimpleName()); // set class
job.setJarByClass(this.getClass()); // set path
FileInputFormat.addInputPath(job, new Path(args[0])); //set mapper
job.setMapperClass(HDFS2TabMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class); // set reduce
TableMapReduceUtil.initTableReducerJob(
"user", // set table
null,
job);
job.setNumReduceTasks(0); boolean b = job.waitForCompletion(true); if(!b) {
throw new IOException("error with job!!!");
} return 0;
} public static void main(String[] args) throws Exception {
//get configuration
Configuration conf = HBaseConfiguration.create(); //submit job
int status = ToolRunner.run(conf, new HDFS2TabMapReduce(), args); //exit
System.exit(status);
} }
运行指令
接下来演示使用BulkLaod将数据从Hdfs导入Hbase,使用该方式可以绕过WAL,memstor等步骤,加快海量数据的效率,代码如下:
package com.jkxy.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.mapreduce.PutSortReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class HFile2TabMapReduce extends Configured implements Tool { public static class HFile2TabMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> { ImmutableBytesWritable rowkey = new ImmutableBytesWritable(); @Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { String[] words = value.toString().split("\t"); Put put = new Put(Bytes.toBytes(words[0]));
put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(words[1]));
put.add(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(words[2]));
rowkey.set(Bytes.toBytes(words[0])); context.write(rowkey, put);
}
} @Override
public int run(String[] args) throws Exception { //create job
Job job = Job.getInstance(getConf(), this.getClass().getSimpleName()); // set run jar class
job.setJarByClass(this.getClass()); // set input . output
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2])); // set map
job.setMapperClass(HFile2TabMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class); // set reduce
job.setReducerClass(PutSortReducer.class); HTable table = new HTable(getConf(), args[0]);
// set hfile output
HFileOutputFormat2.configureIncrementalLoad(job, table ); // submit job
boolean b = job.waitForCompletion(true);
if(!b) {
throw new IOException(" error with job !!!");
}
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(getConf());
// load hfile
loader.doBulkLoad(new Path(args[2]), table); return 0;
} public static void main(String[] args) throws Exception {
// get configuration
Configuration conf = HBaseConfiguration.create(); //run job
int status = ToolRunner.run(conf, new HFile2TabMapReduce(), args); // exit
System.exit(status); } }
使用如下指令:
十九、Hadoop学记笔记————Hbase和MapReduce的更多相关文章
- 二十、Hadoop学记笔记————Hive On Hbase
Hive架构图: 一般用户接口采用命令行操作, hive与hbase整合之后架构图: 使用场景 场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经 ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- 二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序 Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HD ...
- 二十四、Hadoop学记笔记————Spark的架构
master为主节点 一个集群中可能运行多个application,因此也可能会有多个driver DAG Scheduler就是讲RDD Graph拆分成一个个stage 一个Task对应一个Spa ...
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算 Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Y ...
- 二十一、Hadoop学记笔记————kafka的初识
这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统 Apache flume系统,用于日志收集 Apache storm系统,用于实时数据处理 Spark ...
- 学记笔记 $\times$ 巩固 · 期望泛做$Junior$
最近泛做了期望的相关题目,大概\(Luogu\)上提供的比较简单的题都做了吧\(233\) 好吧其实是好几天之前做的了,不过因为太颓废一直没有整理-- \(Task1\) 期望的定义 在概率论和统计学 ...
随机推荐
- 《java入门第一季》之面向对象面试题(this和super的区别)
this和super的区别? 分别是什么呢? this代表本类对象的引用. super代表父类存储空间的标识(可以理解为父类引用,可以操作父类的成员) 怎么用呢? A:调用成员变量 this.成员变量 ...
- Android 高仿微信朋友圈动态, 支持双击手势放大并滑动查看图片。
转载请注明出处:http://blog.csdn.net/sk719887916/article/details/40348873 作者skay: 最近参与了开发一款旅行APP,其中包含实时聊天和动态 ...
- ZeroC Ice IceGrid Node和IceGrid
IceGrid Node介绍 绝大多数分布式系统都有一个共同特点,即分布在各个主机上的节点进程并不是完全独立的,而是彼此之间有相互联系和通信的.集群对集群中的节点有一些控制指令,如部署.启停或者调整某 ...
- MR for Baum-Welch algorithm
The Baum-Welch algorithm is commonly used for training a Hidden Markov Model because of its superior ...
- leetcode之旅(11)-Integer to Roman
题目描述: Given an integer, convert it to a roman numeral. Input is guaranteed to be within the range fr ...
- opencv基本图像操作
// Basic_OpenCV_2.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream> #i ...
- 云技术:负载均衡SLB
什么是SLB? SLB是Server Load Balance(负载均衡)的简称,XX云计算有限公司提供的负载均衡服务,通过设置虚拟服务IP,将位于同一机房的多台云服务器资源虚拟成一个高性能.高可用的 ...
- javascript中如何让类工厂和构造函数变成同一个函数
我们知道在js中可以用一个函数来定义对象的类,该函数称之为对象的构造函数,我们在需要create对象的时候直接调用这个构造函数即可: var Man = funciton(name){ this.na ...
- 使用XStream是实现XML与Java对象的转换(3)--注解
六.使用注解(Annotation) 总是使用XStream对象的别名方法和注册转换器,会让人感到非常的乏味,又会产生很多重复性代码,于是我们可以使用注解的方式来配置要序列化的POJO对象. 1,最基 ...
- Dapper.SimpleCRUD mysql 插入数据时出现的小插曲
最近想玩一下.net dapper,然后在nuget包中搜索看到了 Dapper.SimpleCRUD ,然后我等好奇心重的小骚年,内心又开始跃跃欲试. 使用sqlserver数据库时没有遇到问题,既 ...