Node.js 抓取电影天堂新上电影节目单及ftp链接
1 概述
本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载。
2 node package
- fs
- cheerio
- superagent
- superagent-charset
- express
- path
fs 用来读写文件
cherrio 类似jquery
superagent (ajax http模块)
superagent-charset 解决中文乱码问题
express 搭建server
path 路径
统一安装这些包,可以使用一下命令:
npm i express cheerio superagent superagent-charset path fs --save-dev
如果想深入了解这些包 可以去下面这个网址了解下
find package
3 步骤
第一步:
利用express 搭建本地服务
const app = require('express')();
const port = 3000;
app.get('/', (req, res)=>{
res.send('hello world');
});
app.listen(port, ()=>{
console.log('listening port on', port);
});
打开浏览器 输入localhost:3000
看到下面页面,说明初步成功
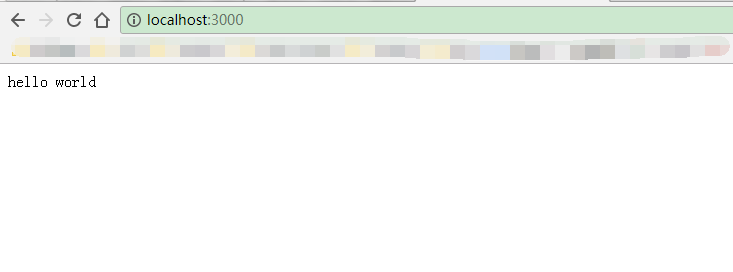
第二步
先试用superagent(http模块)去获取页面的数据,然后用cheerio(类似jquery)去获取页面数据。
具体代码如下
var item = [];
function getMovies() {
item = [];
var url = 'http://www.dytt8.net';
superagent.get(url + '/index.htm').charset().end((err, sres) => {
if (err) {
throw err;
}
var $ = cherrio.load(sres.text);
$('.bd3rl .co_area2').each(function (i, n) {
if (i > 1) return;
var $n = $(n);
var obj = {
name: $n.find('.title_all strong').text(),
data: []
};
$n.find('tr').each(function (i, m) {
var $m = $(m);
var childUrl = url + $m.find('.inddline').eq(0).find('a').eq(1).attr('href');
obj.data.push({
title: $m.find('.inddline').eq(0).text(),
href: url + $m.find('.inddline').eq(0).find('a').eq(1).attr('href'),
date: $m.find('.inddline').eq(1).text(),
download_url: ''
});
});
item.push(obj);
});
fs.writeFile(path.join(__dirname, './doc', 'dy.txt'), '', function () { });
item.forEach(n => {
n.data.forEach((m, i) => {
superagent.get(m.href).charset().end((err, cres) => {
var _$ = cherrio.load(cres.text);
var download_url = _$('#Zoom table a').text();
var title = _$('.bd3r .title_all').text();
title = title.substring(title.indexOf('《') + 1, title.indexOf('》'));
// console.log(title)
var total_movie = title + '~~' + download_url + '\n';
// var total_movie = download_url.split(']')[1].substr(1) + '~~' + download_url + '\n';
var buff = new Buffer(total_movie);
fs.appendFile(path.join(__dirname, './doc', 'dy.txt'), buff, function () { });
});
});
});
});
}
superagent.get()类似ajax get请求,cheerio.load() 类似jquery,获取数据的方法其实就是jquery的方法。
获取完首页的链接,一般我们需要进去详情页才能看得到ftp的地址,可是现在我们做了第二次的轮询请求,就直接得到了ftp的地址,无需进到详情页,节省很多时间。
最终我们会存到本地文件夹里
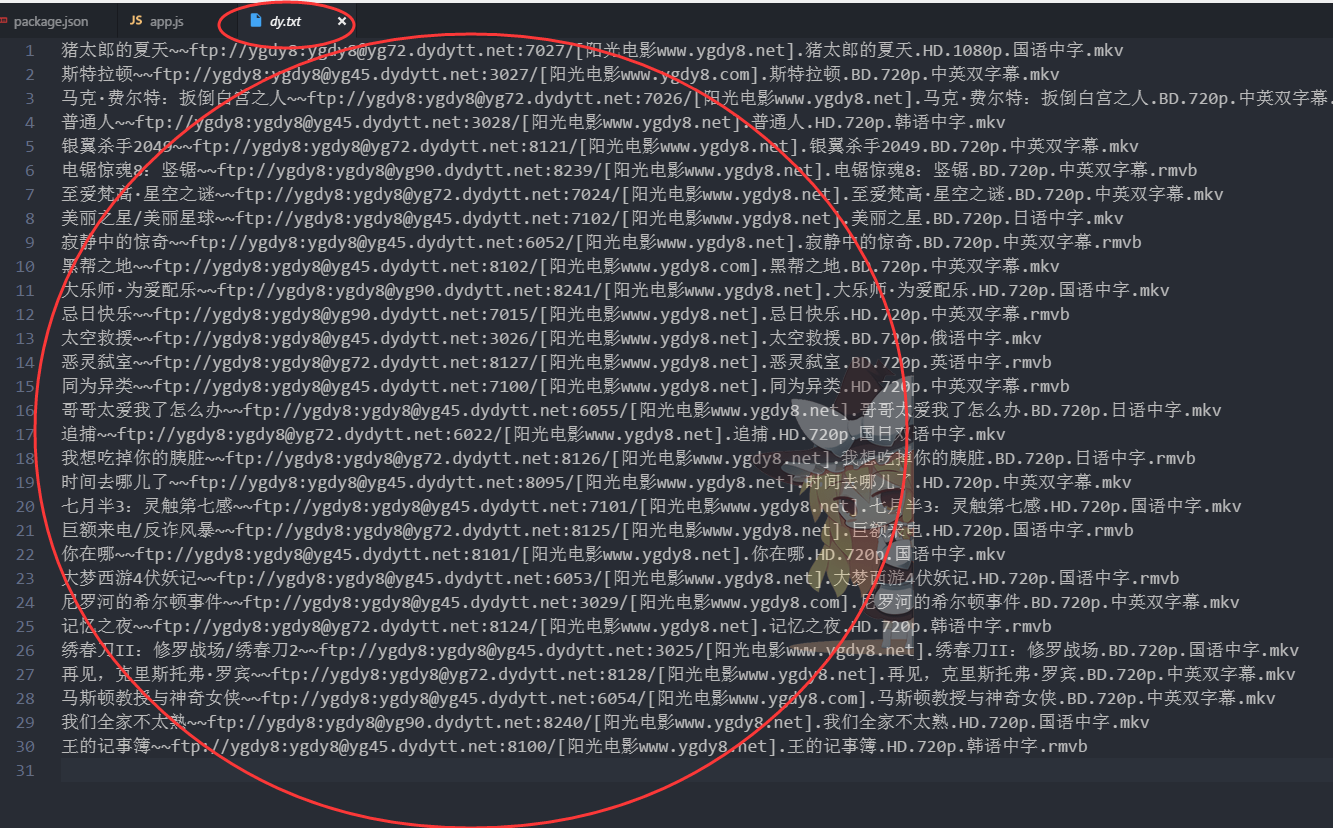
接下来我们会把这些数据呈现到页面中:

代码实现:
app.get('/dy', function (req, res, next) {
var url_data = [];
var img_url = 'https://raw.githubusercontent.com/huainanhai/EXE/master/sevenDay/doc/wz.jpg';
fs.readFile(path.join(__dirname, './doc', 'dy.txt'), 'utf-8', (err, data) => {
if (err) throw err;
url_data = data.split('\n').filter(function (n) {
return n != '';
});
var str = '<div style="width:50%;">';
str += '<h4 style="padding-left:10px;">(温馨提示:复制ftp开头的路径到‘迅雷极速版’(邮件附件里面有)就会自动下载电影了, 最新免费电影节目单不定时更新,福利呦)</h4>'
item.forEach(m => {
str += '<h3 style="padding-left:10px;">' + m.name + '</h3>';
m.data.forEach((n) => {
url_data.forEach(j => {
var name = j.split('~~')[0];
name = name.split('.')[0];
if (n.title.indexOf(name) > -1) {
n.download_url = j.split('~~')[1];
}
});
str += '<div style="">' +
'<a href="' + n.href + '" style="height:30px;display:inline-block;vertical-align: middle;text-decoration:none;margin-left:6px;" target="_blank">' + n.title + '</a>' +
'<span style="height:30px;display:inline-block;vertical-align: middle;color: red;float:right;">' + n.date + '</span>' +
'</div>';
str += '<div style="background:#fdfddf;border:1px solid #ccc;padding:3px 10px;margin-bottom:10px;">' + n.download_url + '</div>';
});
});
str += '<img src="' + img_url + '" width="540" height="748" />';
str += '</div>';
res.send(str);
})
});
4 源码截图

如果要下载本实例,解压 然后 npm install 即可安装所需依赖包,下次我们讲解如果把数据发送到自己的邮箱(或者群发更多人的邮箱)!
Node.js 抓取电影天堂新上电影节目单及ftp链接
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
Node.js 抓取电影天堂新上电影节目单及ftp链接的更多相关文章
- Node.js抓取网页
前几天四六级成绩出来(然而我没考),用Node.js做了一个模拟表单提交并抓取数据的Web 总结一下用到的知识,简单的网页抓取大概就是这个流程了 发送Get或Post请求 表单提交,首先弄到原网页提交 ...
- 使用node.js抓取有路网图书信息(原创)
之前写过使用python抓取有路网图书信息,见http://www.cnblogs.com/dyf6372/p/3529703.html. 最近想学习一下Node.js,所以想试试手,比较一下http ...
- node.js抓取数据(fake小爬虫)
在node.js中,有了 cheerio 模块.request 模块,抓取特定URL页面的数据已经非常方便. 一个简单的就如下 var request = require('request'); va ...
- node.js 抓取网页数据
var $ = require('jquery'); var request = require('request'); request({ url: 'http:\\www.baidu.com',/ ...
- node.js 抓取
http://blog.csdn.net/youyudehexie/article/details/11910465 http://www.tuicool.com/articles/z2YbAr ht ...
- node.js抓取网上图片保存到本地
用到两个模块,http和fs var http = require("http");var fs = require("fs"); var server = h ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- 爬虫:selenium + phantomjs 解决js抓取问题(一)
selenium模块主要用来做测试,模拟键盘.鼠标来操作浏览器. phantomjs 就像一个无界面的浏览器一样. 两个结合能很好的解决js抓取的问题. 测试代码: #coding=utf-8 fro ...
- node.js服务端程序在Linux上持久运行
如果要想在服务端部署node.js程序,让其持久化运行,就不能单单使用npm start命令运行,当然了,这样运行是毫无问题的,但是当关闭xshell窗口或者是关闭进程的时候(其实关闭xshell窗口 ...
随机推荐
- 经典SQL语句大全、50个常用的sql语句
50个常用的sql语句 Student(S#,Sname,Sage,Ssex) 学生表 Course(C#,Cname,T#) 课程表 SC(S#,C#,score) 成绩表 Teacher(T#,T ...
- [ZJOI2012][bzoj 2816] 网络 network [LCT]
题目: http://www.lydsy.com/JudgeOnline/problem.php?id=2816 思路: 第一个条件看完暂时还没什么想法 看完第二个,发现每一个颜色都是一个森林 进而想 ...
- POJ2723 Get Luffy Out 【2-sat】
题目 Ratish is a young man who always dreams of being a hero. One day his friend Luffy was caught by P ...
- app自动测试-微信(iOS)-web-1
appium 是一个用于app自动测试的工具.目前支持测试iOS, Android, Windows上的app.(github: https://github.com/appium/appium) 其 ...
- 【08】Vue 之 vue-cli
8.1. 前置知识学习 npm 学习 官方文档 推荐资料 npm入门 npm介绍 需要了解的知识点 package.json 文件相关配置选项 npm 本地安装.全局安装.本地开发安装等区别及相关命令 ...
- xor和路径(codevs 2412)
题目描述 Description 给定一个无向连通图,其节点编号为1到N,其边的权值为非负整数.试求出一条从1号节点到 N 号节点的路径,使得该路径上经过的边的权值的“XOR 和”最大.该路径可以重复 ...
- NOIP2015提高组T2 洛谷P2661 信息传递
题目描述 有n个同学(编号为1到n)正在玩一个信息传递的游戏.在游戏里每人都有一个固定的信息传递对象,其中,编号为i的同学的信息传递对象是编号为Ti同学. 游戏开始时,每人都只知道自己的生日.之后每一 ...
- 十步优化SQL Server中的数据访问
原文发布时间为:2011-02-24 -- 来源于本人的百度文章 [由搬家工具导入] 转载:http://tech.it168.com/a2009/1125/814/000000814758_all. ...
- python笔记6:模块
6. 模块(一个 .py 文件称为一个模块Module) import 语句 类似 _xxx 和 __xxx 这样的 函数/变量 是非公开的(private),不应该被直接引用 函数定义: 外部不需要 ...
- 牛客网 牛客练习赛13 A.幸运数字Ⅰ
A.幸运数字Ⅰ 链接:https://www.nowcoder.com/acm/contest/70/A来源:牛客网 水题. 代码: #include<iostream> #i ...