关于scrapy
Scrapy安装
1,Pip install wheel
2,pip install 复制路径+文件名Twisted-18.7.0-cp36-cp36m-win_amd64.whl
3,Pip install scrapy
https://germey.gitbooks.io/python3webspider/content/1.8.2-Scrapy%E7%9A%84%E5%AE%89%E8%A3%85.html
4 出win7api的加 pip install 复制路径+文件名pywin32-223.1-cp36-cp36m-win_amd64.whl
创建项目
1,scrapy startproject scrapy_project
创建spider,
2,cd scrapy_project
3,scrapy genspider bole jobbole.com
#bole jobbole.com 一个是文件名 一个是网站名
创立一个文件夹 main 里面
from scrapy.cmdline import execute
execute('scrapy crawl bole'.split())
#bole是文件名
setting 里面的Trun改成False
通过xpath获取内容, xpath返回的元素内容是selector:
zan = response.xpath('//h10[@id="89252votetotal"]/text()').extract_first()
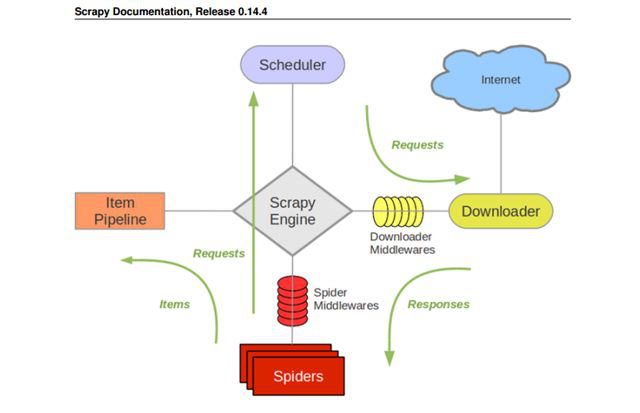
关于scrapy的更多相关文章
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- scrapy爬虫docker部署
spider_docker 接我上篇博客,为爬虫引用创建container,包括的模块:scrapy, mongo, celery, rabbitmq,连接https://github.com/Liu ...
- scrapy 知乎用户信息爬虫
zhihu_spider 此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧.代码地 ...
- ubuntu 下安装scrapy
1.把Scrapy签名的GPG密钥添加到APT的钥匙环中: sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 6272 ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- Scrapy:为spider指定pipeline
当一个Scrapy项目中有多个spider去爬取多个网站时,往往需要多个pipeline,这时就需要为每个spider指定其对应的pipeline. [通过程序来运行spider],可以通过修改配置s ...
- scrapy cookies:将cookies保存到文件以及从文件加载cookies
我在使用scrapy模拟登录新浪微博时,想将登录成功后的cookies保存到本地,下次加载它实现直接登录,省去中间一系列的请求和POST等.关于如何从本次请求中获取并在下次请求中附带上cookies的 ...
- Scrapy开发指南
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. Scrapy基于事件驱动网络框架 Twis ...
- 利用scrapy和MongoDB来开发一个爬虫
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询. 安装 在进行今天的任务之前我们需要安装二个框架,分别 ...
- python3 安装scrapy
twisted(网络异步框架) wget https://pypi.python.org/packages/dc/c0/a0114a6d7fa211c0904b0de931e8cafb5210ad82 ...
随机推荐
- Gitlab安装、汉化及使用
环境:centos 关闭防火墙和selinux [root@Gitlab ~]# setenforce [root@Gitlab ~]# service iptables stop && ...
- Spark大型电商项目实战-及其改良(4) 单独运行程序发现的问题
之前的运行结果比对发现,有1个函数的作用在2个job里面是相同的,但是对应的计算时间却差太远 于是把4个job分开运行.虽说使用的数据不同,但是生成数据的生成器是相同的,数据排布差距不大,数据量也是相 ...
- Java过滤器Filter
过滤器 一. 简介 过滤器一般用于设置字符编码.登录验证.权限验证.敏感词过滤等,减少了代码的冗余,便于代码的复用,但是不一定是每个servlet都必须使用过滤器的. 二. 过滤器的工作流程 图片来源 ...
- ssh到虚拟机---一台主机上
问题描述:我们需要ssh来编辑虚拟机中的文件,以此提高工作效率.但是新建的虚机一般来说没有开启ssh服务,所以需要在虚拟机上开启ssh服务. 1)检查是否安装了SSH rpm -qa |grep ss ...
- grep 以及find 命令
grep 以及find 命令 1. find 命令 Linux 下find 命令在目录结构中搜索文件,并执行指定的操作.Linux 下find 命令提供了相当多的查找条件,功能很强大.由于find 具 ...
- 持久层Mybatis3底层源码分析,原理解析
Mybatis-持久层的框架,功能是非常强大的,对于移动互联网的高并发 和 高性能是非常有利的,相对于Hibernate全自动的ORM框架,Mybatis简单,易于学习,sql编写在xml文件中,和代 ...
- Vue学习(一)Vue目录结构
安装教程网上一大把,可以自己搜索.记录下学习过程. 认识下Vue的目录结构,取自:https://www.cnblogs.com/dragonir/p/8711761.html vue 文件目录结构详 ...
- vue filters中使用data中数据
vue filters中 this指向的不是vue实例,但想要获取vue实例中data中的数据,可以采用下面方法.在 beforeCreate中将vue实例赋值给全局变量app0,然后filters中 ...
- VFIO PF SRIOV IOMMU UIO概念解释、关联
1.UIO出现的原因 第一,硬件设备可以根据功能分为网络设备,块设备,字符设备,或者根据与CPU相连的方式分为PCI设备,USB设备等.它们被不同的内核子系统支持.这些标准的设备的驱动编写较为容易而且 ...
- Discuz3.2与Java 项目整合单点登陆
JAVA WEB项目与Discuz 论坛整合的详细步骤完全版目前未有看到,最近遇到有人在问,想到这个整个不是一时半会也解释不清楚.便把整个整合过程以及后续碰到的问题解决方案写下,以供参考. 原理 Di ...