论文解读(GCC)《Graph Contrastive Clustering》
论文信息
论文标题:Graph Contrastive Clustering
论文作者:Huasong Zhong, Jianlong Wu, Chong Chen, Jianqiang Huang, Minghua Deng, Liqiang Nie, Zhouchen Lin, Xian-Sheng Hua
论文来源:2021, ICCV
论文地址:download
论文代码:download
1 Introduction
研究方向:解决传统的 URL 没有考虑到类别信息和聚类目标的问题。
传统对比学习和本文研究的对比:
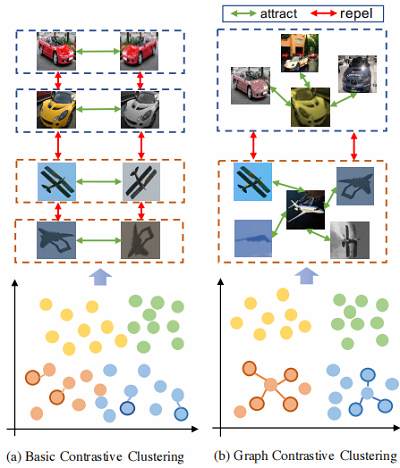
- 传统方式:图及其增强视图为正对;
- 本文:一个聚类簇中的视图也应共享相似的特征表示;
2 Method
2.1 Task
将 $N$ 个未标记图像通过一个基于CNN 的网络聚类分配为 $K$ 个不同的类:
$\ell_{i}=\arg \underset{j}{\text{max}} \left(p_{i j}\right), 1 \leq j \leq K$
2.2 Graph Contrastive (GC)
Symmetric normalized Laplacian:
$L^{\mathrm{sym}}:=D^{-1 / 2} L D^{-1 / 2}=I-D^{-1 / 2} A D^{-1 / 2}$
即:
$L_{i, j}^{s y m}:=\left\{\begin{array}{ll}1 & \text { if } i=j \text { and } \operatorname{deg}\left(v_{i}\right) \neq 0 \\-\frac{1}{\sqrt{\operatorname{deg}\left(v_{i}\right) \operatorname{deg}\left(v_{j}\right)}} & \text { if } i \neq j \text { and } v_{i} \text { is adjacent to } v_{j} \\0 & \text { otherwise. }\end{array}\right.$
【着重观察:$L_{i j}=-\frac{A_{i j}}{\sqrt{d_{i} d_{j}}}, i \neq j$】
社区检测中的基本思想: 同一社区中特征表示的相似性应该大于社区之间的相似性。
图上的基本思想:邻居之间的表示相似性应该大于非邻居的相似性。
社区内(intra-community)的相似性定义为:
$\mathcal{S}_{i n t r a}=\sum\limits _{L_{i j}<0}-L_{i j} S\left(x_{i}, x_{j}\right)$
社区间(inter-community)的相似性定义为:
$\mathcal{S}_{\text {inter }}=\sum\limits _{L_{i j}=0} S\left(x_{i}, x_{j}\right)$
$S\left(x_{i}, x_{j}\right)$ 是相似性函数,本文设置为:
$S\left(x_{i}, x_{j}\right)=e^{-\left\|x_{i}-x_{j}\right\|_{2}^{2} / \tau} $
其中,$\left\|x_{i}-x_{j}\right\|_{2}^{2}=\left\|x_{i}\right\|_{2}^{2}+\left\|x_{j}\right\|_{2}^{2}-2 x_{i} \cdot x_{j}=2-2x_ix_j$ 【通常 表示 $\left\|z_{i}\right\|_{2}=1$ (经过正则化)】
本文的相似性函数是 $S\left(x_{i}, x_{j}\right)=e^{x_{i} \cdot x_{j} / \tau}$ 。
然后,计算 GC 的总损失为:
$\mathcal{L}_{G C}=-\frac{1}{N} \sum\limits _{i=1}^{N} \log \left(\frac{\sum\limits_{L_{i j}<0}-L_{i j} S\left(x_{i}, x_{j}\right)}{\sum\limits_{L_{i j}=0} S\left(x_{i}, x_{j}\right)}\right)$
最小化 $\mathcal{L}_{G C}$ 可以同时增加社区内总相似度,降低社区间总相似度,从而提高可分离性,得到学习得到的特征表示与图结构一致的结果。
2.3 Framework
框架如下:
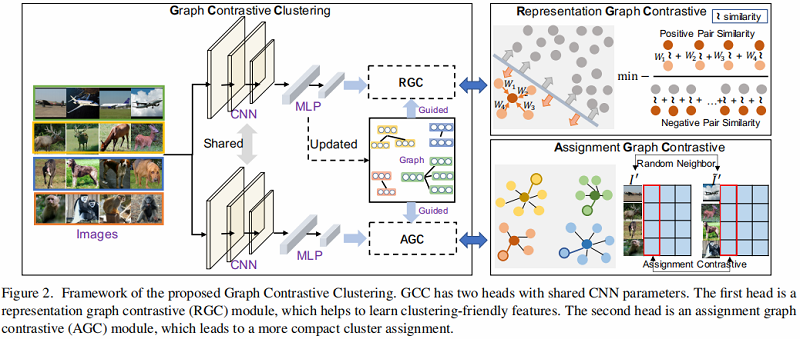
2.3.1 Graph Construction
深度模型在训练过程中经常波动,一个 epoch 的特征表示可能有较大的偏差,本文采用移动平均去解决这个问题。
假设 $\Phi_{\theta}^{(t)}$ 代表着模型,第 $t$ 个 epoch 的特征表示 $Z^{(t)}= \left(z_{1}^{(t)}, \cdots, z_{N}^{(t)}\right)=\left(\Phi_{\theta}^{(t)}\left(I_{1}\right), \cdots, \Phi_{\theta}^{(t)}\left(I_{N}\right)\right) $ ,采用的移动平均如下:
${\large \bar{z}_{i}^{(t)}=\frac{(1-\alpha) \bar{z}_{i}^{(t-1)}+\alpha z_{i}^{(t)}}{\left\|(1-\alpha) \bar{z}_{i}^{(t-1)}+\alpha z_{i}^{(t)}\right\|_{2}}} , i=1, \cdots, N,$
其中 $\alpha$ 是权衡参数,$\bar{z}_{i}^{(0)}=z_{i}^{(0)}$ 。
然后根据特征表示构造 KNN 图,并计算邻接矩阵:
$A_{i j}^{(t)}=\left\{\begin{array}{ll}1, & \text { if } \bar{z}_{j}^{(t)} \in \mathcal{N}^{k}\left(\bar{z}_{i}^{(t)}\right) \text { or } \bar{z}_{i}^{(t)} \in \mathcal{N}^{k}\left(\bar{z}_{j}^{(t)}\right) \\0, & \text { otherwise }\end{array}\right. \quad\quad\quad(6)$
接着计算其对应的 $L^{\mathrm{sym}}$。
2.3.2 Representation Graph Contrastive
在得到 $L^{\mathrm{sym}}$ 后计算 RGC 损失:
$\mathcal{L}_{R G C}^{(t)}=-\frac{1}{N} \sum\limits _{i=1}^{N} \log {\Large \left(\frac{\sum\limits_{L_{i j}^{(t)}<0}-L_{i j}^{(t)} e^{z_{i}^{\prime} \cdot z_{j}^{\prime} / \tau}}{\sum\limits_{L_{i j}=0} e^{z_{i}^{\prime} \cdot z_{j}^{\prime} / \tau}}\right)} \quad\quad\quad(8)$
2.3.3 Assignment Graph Contrastive
传统:image 本身以及其增强 image 应该分配给同一个簇;
本文:外加 image 的邻居也应该分配给同一个簇;
假设 $I^{\prime}=\left\{I_{1}^{\prime}, \ldots, I_{N}^{\prime}\right\}$ 是原始图像 $\mathbf{I}=\left\{I_{1}, \ldots, I_{N}\right\}$ 的随机增强视图。$\tilde{I}^{\prime}=\left\{\tilde{I}_{1}^{\prime}, \ldots, \tilde{I}_{N}^{\prime}\right\} $ 中 $\tilde{I}_{i}^{\prime}$ 是 $I_{i}$ 根据图邻接矩阵 $A(t)$ 选择的随机邻居,$I^{\prime}$ 和 $ \tilde{I}^{\prime}$ 的概率分配矩阵如下:【行向量角度】
其中,$\operatorname{RN}\left(I_{i}\right)$ 表示图像 $I_{i}$ 的一个随机邻居。
对上述概率分配矩阵进行转换:【列向量的角度】
$\mathbf{q}^{\prime}=\left[q_{1}^{\prime}, \quad \ldots \quad, q_{K}^{\prime}\right]_{N \times K}$
$\tilde{\mathbf{q}}^{\prime}=\left[\tilde{q}_{1}^{\prime}, \quad \cdots \quad, \tilde{q}_{K}^{\prime}\right]_{N \times K}$
其中 $q_{i}^{\prime}$ 和 $\tilde{q}_{i}^{\prime}$ 可以告诉我们 $\mathbf{I}^{\prime}$ 和 $\tilde{\mathbf{I}}^{\prime}$ 中的哪些图片将分别被分配给簇 $i$ 。那么我们可以将AGC的学习损失定义为:
$\mathcal{L}_{A G C}=-\frac{1}{K} \sum\limits _{i=1}^{K} \log \left({\Large \frac{e^{q_{i}^{\prime} \cdot \tilde{q}_{i}^{\prime} / \tau}}{\sum _{j=1}^{K} e^{q_{i}^{\prime} \cdot \tilde{q}_{j}^{\prime} / \tau}} }\right)\quad\quad\quad(9)$
2.3.4 Cluster Regularization Loss
在深度聚类中,很容易陷入局部最优解,将大多数样本分配到少数聚类中。为了避免简单的解决方案,我们还添加了一个类似于 PICA[16] 和 SCAN[33] 的聚类正则化损失:
$\mathcal{L}_{C R}=\log (K)-H(\mathcal{Z})\quad\quad\quad(10)$
其中,$H$ 是熵函数,${\large \mathcal{Z}_{i}=\frac{\sum_{j=1}^{N} q_{i j}}{\sum _{i=1}^{K} \sum_{j=1}^{N} q_{i j}}} $,$\mathbf{q}=\left[q_{1}, \cdots, q_{K}\right]_{N \times K}$ 是 $\mathbf{I}$ 的分配概率。
那么GCC的总体目标函数可以表述为:
$\mathcal{L}=\mathcal{L}_{R G C}+\lambda \mathcal{L}_{A G C}+\eta \mathcal{L}_{C R}\quad\quad\quad(11)$
其中,$ \lambda$ 和 $\eta$ 是权重参数。
2.4 Model Training
训练过程如下:

3 Experiments
实验结果

相关论文
基于 reconstruction 的深度聚类方法:[39, 28, 8, 11, 40]
基于 self-augmentation 的深度聚类方法:[3, 36, 17, 12, 16, 33, 44]
经典的聚类算法:[43, 10, 2, 35, 37]
谱聚类:[26]
子空间聚类:[24, 9]
深度自适应聚类:[3]
深度综合相关挖掘:[36]
聚类正则化:PICA [16]、SCAN [33]
论文解读(GCC)《Graph Contrastive Clustering》的更多相关文章
- 论文解读(GCC)《GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training》
论文信息 论文标题:GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training论文作者:Jiezhong Qiu, Qibi ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息 论文标题:Self-supervised Graph Neural Networks without explicit negative sampling论文作者:Zekarias T. K ...
- 论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
论文信息 论文标题:Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering论文作者:Chaki ...
- 论文解读(MCGC)《Multi-view Contrastive Graph Clustering》
论文信息 论文标题:Multi-view Contrastive Graph Clustering论文作者:Erlin Pan.Zhao Kang论文来源:2021, NeurIPS论文地址:down ...
- 论文解读(CGC)《CGC: Contrastive Graph Clustering for Community Detection and Tracking》
论文信息 论文标题:CGC: Contrastive Graph Clustering for Community Detection and Tracking论文作者:Namyong Park, R ...
- 论文解读(SCGC))《Simple Contrastive Graph Clustering》
论文信息 论文标题:Simple Contrastive Graph Clustering论文作者:Yue Liu, Xihong Yang, Sihang Zhou, Xinwang Liu论文来源 ...
- 论文解读(gCooL)《Graph Communal Contrastive Learning》
论文信息 论文标题:Graph Communal Contrastive Learning论文作者:Bolian Li, Baoyu Jing, Hanghang Tong论文来源:2022, WWW ...
- 论文解读(AGC)《Attributed Graph Clustering via Adaptive Graph Convolution》
论文信息 论文标题:Attributed Graph Clustering via Adaptive Graph Convolution论文作者:Xiaotong Zhang, Han Liu, Qi ...
随机推荐
- 07模块化设计之top_down
一设计功能:(一)用两个分频模块,实现16分频,且让输入a 和b在16个系统时钟内,相与一次. (二)模块化设计思想(结构化思维) 拆分,即把一个系统划分成多个功能模块,控制模块,组合模块.然后从功能 ...
- 如何看待malloc产生内存碎片
上代码直接研究: int main() { int *heap_d; int *heap_e; int *heap_f; heap_d = (int *)malloc(10); heap_e = (i ...
- 一个关于wait/notify与锁关系的探究
wait/notify 机制是解决生产者消费者问题的良药.它的核心逻辑是基于条件变量的锁机制处理.所以,它们到底是什么关系?wait()时是否需要持有锁? notify()是否需要持有锁?先说答案:都 ...
- 去掉一个Vector集合中重复的元素 ?
Vector newVector = new Vector(); For (int i=0;i<vector.size();i++) { Object obj = vector.get(i); ...
- 客户端注册 Watcher 实现?
1.调用 getData()/getChildren()/exist()三个 API,传入 Watcher 对象 2.标记请求 request,封装 Watcher 到 WatchRegistrati ...
- 学习zabbix(八)
一,Zabbix架构 zabbix 是一个基于 WEB 界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案.zabbix 能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制 ...
- resin服务之三---独立resin的配置
独立resin的配置 关掉httpd服务: [root@data-1-1 ~]# killall httpd [root@data-1-1 ~]# lsof -i :80 ------>h ...
- 学习GlusterFS(一)
一.概述 1.GlusterFS是集群式NAS存储系统,分布式文件系统(POSIX兼容),Tcp/Ip方式互联的一个并行的网络文件系统,通过原生 GlusterFS 协议访问数据,也可以通过 NFS/ ...
- idea常见设置一
1.顶部执行栏调整 原: 设置:勾选view==>toolbar 后: 这个一看其实没有什么太大的作用,但是你看这个按钮 这个按钮就是File==>Settings,这样会稍微方便点,只要 ...
- 自动驾驶运动规划-Dubins曲线
1.Simple Car模型 如下图所示,Simple Car模型是一个表达车辆运动的简易模型.Simple Car模型将车辆看做平面上的刚体运动,刚体的原点位于车辆后轮的中心:x轴沿着车辆主轴方向, ...