Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中
通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的简单实现方法。
必要的第三方库:requests、beautifulsoup4、xlwt。
先来看看通过使用Excel文件保存数据的一个简单实例。
#导入xlwt模块
import xlwt
#创建一个Workbook对象,即创建一个Excel工作簿
f = xlwt.Workbook()
#创建学生信息表
#sheet1表示Excel文件中的一个表
#创建一个sheet对象,命名为“学生信息”,cell_overwrite_ok表示是否可以覆盖单元格,是Worksheet实例化的一个参数,默认值是False
sheet1 = f.add_sheet(u'学生信息',cell_overwrite_ok=True)
#标题信息行集合
rowTitle = [u'学号',u'姓名',u'性别',u'出生年月']
#学生信息行集合
rowDatas = [[u'',u'张三',u'男',u'1998-2-3'],[u'',u'李四',u'女',u'1999-12-12'],[u'',u'王五',u'男',u'1998-7-8']]
#遍历向表格写入标题行信息
for i in range(0,len(rowTitle)):
# 其中的'0'表示行, 'i'表示列,0和i指定了表中的单元格,'rowTitle[i]'是向该单元格写入的内容
sheet1.write(0,i,rowTitle[i])
#遍历向表格写入学生信息
for k in range(0,len(rowDatas)): #先遍历外层的集合,即每行数据
for j in range(0,len(rowDatas[k])): #再遍历内层集合,j表示列数据
sheet1.write(k+1,j,rowDatas[k][j]) #k+1表示先去掉标题行,j表示列数据,rowdatas[k][j] 插入单元格数据
#保存文件的路径及命名
f.save('D:/WriteToExcel.xlsx')
在D盘对应的名为WriteToExcel.xlsx的Excel文件中,发现信息已被插入到表格中。
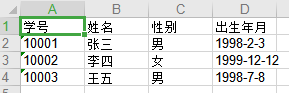
类似地,将爬取到的数据写入Excel文件中保存。
import requests
from bs4 import BeautifulSoup
import xlwt def getHtml():
#k代表存储到Excel的行数
k=1
#创建一个工作簿
f = xlwt.Workbook()
#创建一个工作表
sheet = f.add_sheet("Python相关职业招聘信息")
rowTitle = ['职位名', '公司名', '工作地点', '薪资', '发布时间','链接']
for i in range(0,len(rowTitle)):
sheet.write(0, i, rowTitle[i])
url='https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=' #解析第1页
for page in range(1):
res = requests.get(url.format(page))
res.encoding = 'GBK'
soup = BeautifulSoup(res.text, 'html.parser')
t1 = soup.find_all('.t1 span a')
t2 = soup.select('.t2 a')
t3 = soup.select('.t3')
t4 = soup.select('.t4')
t5 = soup.select('.t5')
for i in range(len(t1)):
job = t1[i].get('title')#获取职位名
href = t2[i].get('href')#获取链接
company = t2[i].get('title')#获取公司名
location = t3[i+1].text#获取工作地点
salary = t4[i+1].text#获取薪资
date = t5[i+1].text#获取发布日期
print(job + " " + company + " " + location + " " + salary + " " + date + " " + href)
f.write(k,0,job)
f.write(k,1,company)
f.write(k,2,location)
f.write(k,3,salary)
f.write(k,4,date)
f.write(k,5,href)
k+=1#每存储一行 k值加1
f.save('D:/Python相关职业招聘信息.xlsx')#写完后调用save方法进行保存 if __name__=='__main__':
getHtml()

Python:将爬取的网页数据写入Excel文件中的更多相关文章
- Python学习笔记_从CSV读取数据写入Excel文件中
本示例特点: 1.读取CSV,写入Excel 2.读取CSV里具体行.具体列,具体行列的值 一.系统环境 1. OS:Win10 64位英文版 2. Python 3.7 3. 使用第三方库:csv. ...
- 爬取百度页面代码写入到文件+web请求过程解析
一.爬取百度页面代码写入到文件 代码示例: from urllib.request import urlopen #导入urlopen包 url="http://www.baidu.com& ...
- PHP将数据写入指定文件中
首先创建一个空的txt文件,这里我们创建了一个1.txt的空文件. 第一种方法:fwrite函数 <?php $file=fopen('1.txt','rb+'); var_dump(fwrit ...
- java 写入数据到Excel文件中_Demo
=======第一版:基本功能实现======= import com.google.common.collect.Maps; import org.apache.log4j.Logger; impo ...
- flink---实时项目--day01--1. openrestry的安装 2. 使用nginx+lua将日志数据写入指定文件中 3. 使用flume将本地磁盘中的日志数据采集到的kafka中去
1. openrestry的安装 OpenResty = Nginx + Lua,是⼀一个增强的Nginx,可以编写lua脚本实现⾮非常灵活的逻辑 (1)安装开发库依赖 yum install -y ...
- python爬虫-爬取豆瓣电影数据
#!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:27# 文件 :spider_05.py# IDE :PyChar ...
- python操作MySQL数据库并将数据写入excel
#!/usr/bin/python# -*- coding:utf-8 -*-'''方法:通过pymsql模块连接mysql数据库,然后通过游标cursor查询SQL语句将结果存储在Excel文件中, ...
- perl 通过<<和文件句柄将数据写入到文件中去
可以通过文件句柄和<<运算符将文件内容写入到文件中去 #!usr/bin/perl -W use strict; use Spreadsheet::ParseExcel; use utf8 ...
- python爬取动态网页数据,详解
原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了? 浏览器请求数据方式:浏览器向服务器的api(例 ...
随机推荐
- 【Java Web开发学习】Servlet、Filter、Listener
[Java Web开发学习]Servlet 转发:https://www.cnblogs.com/yangchongxing/p/9274739.html 1.Servlet package cn.y ...
- 使用GDAL/OGR读写矢量文件
感觉GIS中矢量相关内容还是挺庞杂的,并且由于版本迭代的关系,使用GDAL/OGR读写矢量的资料也有点不太一样.这里总结了一个读写矢量的示例,实现代码如下: #include <iostream ...
- 智能家居手势识别,只需百度AI即可搞定
上次我尝试做了一个给眼镜加特效,针对的是静态图像,具体文章参考 https://ai.baidu.com/forum/topic/show/942890 . 这次我尝试在视频中加眼镜特效,并且加上手势 ...
- December 14th, Week 50th Saturday, 2019
If you have got a talent, protect it. 如果你有天赋,要去保护她. From Jim Carrey. If you think you have a talent, ...
- JsonPath基本用法
JsonPath基本用法 本文主要介绍JsonPath的基本语法,并演示如何在Newtonsoft.Json中进行使用. JsonPath的来源 看它的名字你就能知道,这家伙和JSON文档有关系,正如 ...
- SpringBoot FatJar启动原理
目录 SpringBoot FatJar启动原理 背景 储备知识 URLStreamHandler Archive 打包 SpringBoot启动 扩展 SpringBoot FatJar启动原理 背 ...
- ElementUI项目请求SpringBoot后台项目时提示:Access to XMLHttpRequest at **from origin ** has been blocked by CORS policy
场景 搭建ElementUI前端项目后提示: Access to XMLHttpRequest at **from origin ** has been blocked by CORS policy ...
- PHP命令执行漏洞初探
PHP命令执行漏洞初探 Mirror王宇阳 by PHP 命令执行 PHP提供如下函数用于执行外部应用程序:例如:system().shell_exec().exec().passthru() sys ...
- Hyper-V “SP2019SER”无法更改状态。操作失败,错误代码为“32788”。
卸载Hyper-V,然后重装,再重启已有的Hyper-V服务器,报错如下: 尝试启动选定的虚拟机时出错.“SP2019SER”无法更改状态. 原因:卸载后导致虚拟网卡出现问题导致的. 解决办法: 右击 ...
- Android框架式编程之Retrofit
一.Retrofit 简介 Retrofit 官网地址: https://github.com/square/retrofit Retrofit(即Retrofit,目前最新版本为2.6.0版本),是 ...