Kubernetes之调度器和调度过程
scheduler
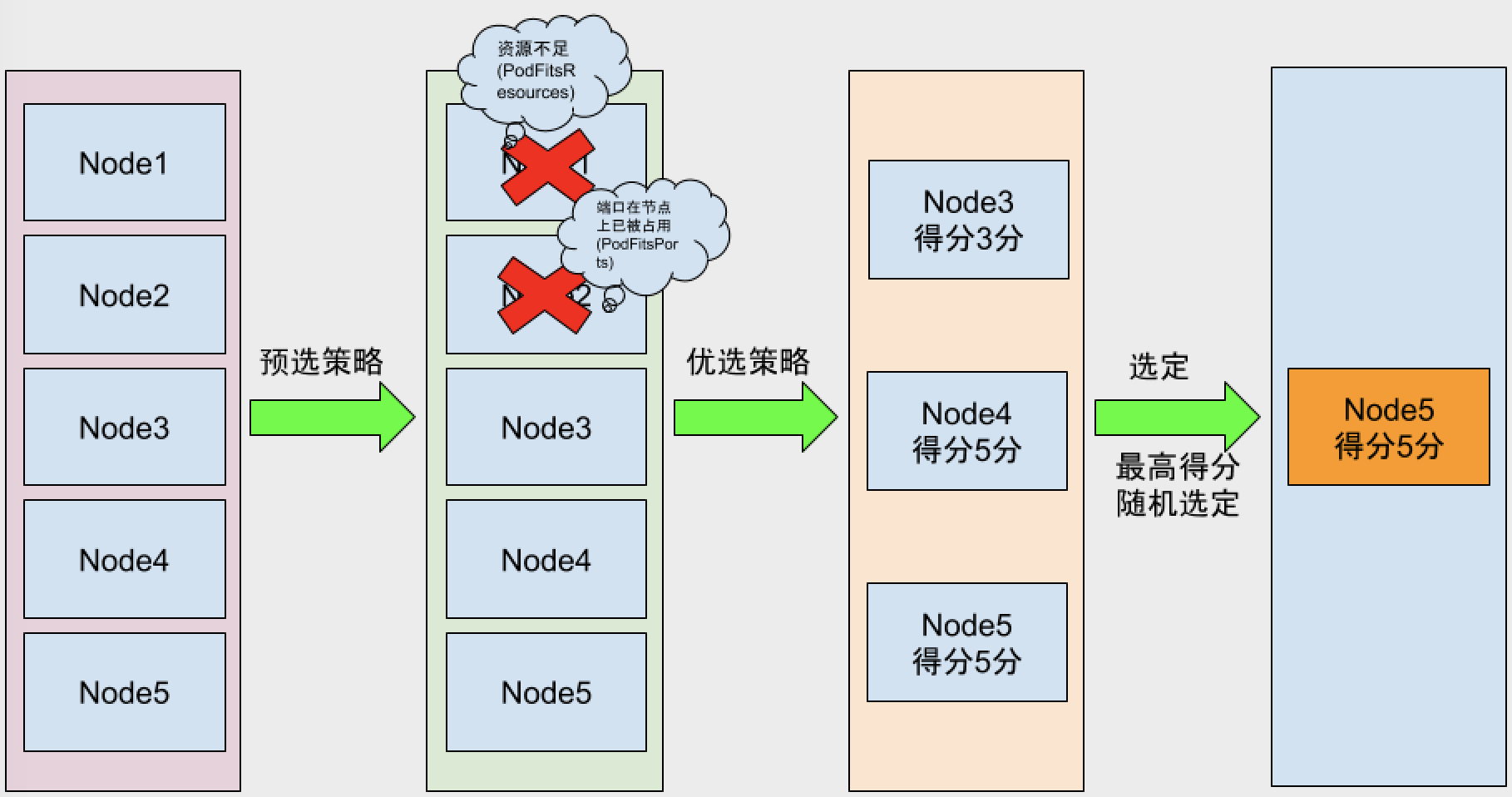
当Scheduler通过API server 的watch接口监听到新建Pod副本的信息后,它会检查所有符合该Pod要求的Node列表,开始执行Pod调度逻辑。调度成功后将Pod绑定到目标节点上。Scheduler在整个系统中承担了承上启下的作用,承上是负责接收创建的新Pod,为安排一个落脚的地(Node),启下是安置工作完成后,目标Node上的kubelet服务进程接管后继工作,负责Pod生命周期的后半生。具体来说,Scheduler的作用是将待调度的Pod安装特定的调度算法和调度策略绑定到集群中的某个合适的Node上,并将绑定信息传给API server 写入etcd中。整个调度过程中涉及三个对象,分别是:待调度的Pod列表,可以的Node列表,以及调度算法和策略。
Kubernetes Scheduler 提供的调度流程分三步:
- 预选策略(predicate) 遍历nodelist,选择出符合要求的候选节点,Kubernetes内置了多种预选规则供用户选择。
- 优选策略(priority) 在选择出符合要求的候选节点中,采用优选规则计算出每个节点的积分,最后选择得分最高的。
- 选定(select) 如果最高得分有好几个节点,select就会从中随机选择一个节点。
如图:
预选策略算法的集合在官方源码
常用的预选策略(代码里的策略不一定都会被使用)
- CheckNodeConditionPred 检查节点是否正常
- GeneralPred HostName(如果pod定义hostname属性,会检查节点是否匹配。pod.spec.hostname)、PodFitsHostPorts(检查pod要暴露的hostpors是否被占用。pod.spec.containers.ports.hostPort)
- MatchNodeSelector pod.spec.nodeSelector 看节点标签能否适配pod定义的nodeSelector
- PodFitsResources 判断节点的资源能够满足Pod的定义(如果一个pod定义最少需要2C4G node上的低于此资源的将不被调度。用kubectl describe node NODE名称 可以查看资源使用情况)
- NoDiskConflict 判断pod定义的存储是否在node节点上使用。(默认没有启用)
- PodToleratesNodeTaints 检查pod上Tolerates的能否容忍污点(pod.spec.tolerations)
- CheckNodeLabelPresence 检查节点上的标志是否存在 (默认没有启动)
- CheckServiceAffinity 根据pod所属的service。将相同service上的pod尽量放到同一个节点(默认没有启动)
- CheckVolumeBinding 检查是否可以绑定(默认没有启动)
- NoVolumeZoneConflict 检查是否在一起区域(默认没有启动)
- CheckNodeMemoryPressure 检查内存是否存在压力
- CheckNodeDiskPressure 检查磁盘IO压力是否过大
- CheckNodePIDPressure 检查pid资源是否过大
优选策略
- least_requested 选择消耗最小的节点(根据空闲比率评估 cpu(总容量-sum(已使用)*10/总容量) )
- balanced_resource_allocation 从节点列表中选出各项资源使用率最均衡的节点(CPU和内存)
- node_prefer_avoid_pods 节点倾向
- taint_toleration 将pod对象的spec.toleration与节点的taints列表项进行匹配度检查,匹配的条目越多,得分越低。
- selector_spreading 与services上其他pod尽量不在同一个节点上,节点上通一个service的pod越少得分越高。
- interpod_affinity 遍历node上的亲和性条目,匹配项越多的得分越高
- most_requested 选择消耗最大的节点上(尽量将一个节点上的资源用完)
- node_label 根据节点标签得分,存在标签既得分,没有标签没得分。标签越多 得分越高。
- image_locality 节点上有所需要的镜像既得分,所需镜像越多得分越高。(根据已有镜像体积大小之和)
高级调度方式
当我们想把调度到预期的节点,我们可以使用高级调度分为:
- 节点选择器: nodeSelector、nodeName
- 节点亲和性调度: nodeAffinity
- Pod亲和性调度:PodAffinity
- Pod反亲和性调度:podAntiAffinity
NodeSelector
我们定义一个pod,让其选择带有node=ssd这个标签的节点
apiVersion: v1
kind: Pod
metadata:
name: pod-
labels:
name: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
nodeSelector:
node: ssd kubectl apply -f test.yaml
查看信息
#get一下pod 一直处于Pending状态
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
pod- / Pending 7s
#查看详细信息,是没有可用的selector
$ kubectl describe pod pod-
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 9s (x14 over 36s) default-scheduler / nodes are available: node(s) didn't match node selector.
#我们给node2打上这个标签
$ kubectl label node k8s-node02 node=ssd
node/k8s-node02 labeled
#Pod正常启动
$ kubectl describe pod pod-
....
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 2m (x122 over 8m) default-scheduler / nodes are available: node(s) didn't match node selector.
Normal Pulled 7s kubelet, k8s-node02 Container image "ikubernetes/myapp:v1" already present on machine
Normal Created 7s kubelet, k8s-node02 Created container
Normal Started 7s kubelet, k8s-node02 Started container
nodeAffinity
kubectl explain pod.spec.affinity.nodeAffinity
- requiredDuringSchedulingIgnoredDuringExecution 硬亲和性 必须满足亲和性。
- matchExpressions 匹配表达式,这个标签可以指定一段,例如pod中定义的key为zone,operator为In(包含那些),values为 foo和bar。就是在node节点中包含foo和bar的标签中调度
- matchFields 匹配字段 和上面的意思 不过他可以不定义标签值,可以定义
- preferredDuringSchedulingIgnoredDuringExecution 软亲和性 能满足最好,不满足也没关系。
- preference 优先级
- weight 权重1-100范围内,对于满足所有调度要求的每个节点,调度程序将通过迭代此字段的元素计算总和,并在节点与对应的节点匹配时将“权重”添加到总和。
运算符包含:In,NotIn,Exists,DoesNotExist,Gt,Lt。可以使用NotIn和DoesNotExist实现节点反关联行为。
硬亲和性:
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-pod
labels:
name: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- foo
- bar
$ kubectl apply -f pod-affinity-demo.yaml
$ kubectl describe pod node-affinity-pod
.....
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 33s (x25 over 1m) default-scheduler / nodes are available: node(s) didn't match node selector.
# 给其中一个node打上foo的标签
$ kubectl label node k8s-node03 zone=foo
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
node-affinity-pod / Running 8m
软亲和性:
与requiredDuringSchedulingIgnoredDuringExecution比较,这里需要注意的是preferredDuringSchedulingIgnoredDuringExecution是个列表项,而preference不是一个列表项了。
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-pod-
labels:
name: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight:
preference:
matchExpressions:
- key: zone
operator: In
values:
- foo
- bar
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
node-affinity-pod 1/1 Running 0 3h 10.244.3.2 k8s-node03
node-affinity-pod-2 1/1 Running 0 1m 10.244.3.3 k8s-node03
podAffinity
Pod亲和性场景,我们的k8s集群的节点分布在不同的区域或者不同的机房,当服务A和服务B要求部署在同一个区域或者同一机房的时候,我们就需要亲和性调度了。
kubectl explain pod.spec.affinity.podAffinity 和NodeAffinity是一样的,都是有硬亲和性和软亲和性
硬亲和性:
- labelSelector 选择跟那组Pod亲和
- namespaces 选择哪个命名空间
- topologyKey 指定节点上的哪个键
样例
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-pod1
labels:
name: podaffinity-myapp
tier: service
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-pod2
labels:
name: podaffinity-myapp
tier: front
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: name
operator: In
values:
- podaffinity-myapp
topologyKey: kubernetes.io/hostname
查看
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
node-affinity-pod1 / Running 12s 10.244.2.6 k8s-node02
node-affinity-pod2 / Running 12s 10.244.2.5 k8s-node02
podAntiAffinity
Pod反亲和性场景,当应用服务A和数据库服务B要求尽量不要在同一台节点上的时候。
kubectl explain pod.spec.affinity.podAntiAffinity 也分为硬反亲和性和软反亲和性调度(和podAffinity一样的配置)
#首先把两个node打上同一个标签。
kubectl label node k8s-node02 zone=foo
kubectl label node k8s-node03 zone=foo
#反硬亲和调度
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-pod1
labels:
name: podaffinity-myapp
tier: service
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-pod2
labels:
name: podaffinity-myapp
tier: front
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: name
operator: In
values:
- podaffinity-myapp
topologyKey: zone
查看一下(因为zone这个key在每个node都有会,所以第二个Pod没有办法调度,所以一直Pending状态)
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
node-affinity-pod1 / Running 11s
node-affinity-pod2 / Pending 11s
污点容忍调度(Taint和Toleration)
前两种方式都是pod选择那个pod,而污点调度是node选择的pod,污点就是定义在节点上的键值属性数据。举要作用是让节点拒绝pod,拒绝不合法node规则的pod。Taint(污点)和 Toleration(容忍)是相互配合的,可以用来避免 pod 被分配到不合适的节点上,每个节点上都可以应用一个或多个 taint ,这表示对于那些不能容忍这些 taint 的 pod,是不会被该节点接受的。
Taint
Taint是节点上属性,我们看一下Taints如何定义
kubectl explain node.spec.taints(对象列表)
- key 定义一个key
- value 定义一个值
- effect pod不能容忍这个污点时,他的行为是什么,行为分为三种:NoSchedule 仅影响调度过程,对现存的pod不影响。PreferNoSchedule 系统将尽量避免放置不容忍节点上污点的pod,但这不是必需的。就是软版的NoSchedule NoExecute 既影响调度过程,也影响现存的pod,不满足的pod将被驱逐。
node 打 taint
kubectl taint NODE NAME KEY_1=VAL_1:TAINT_EFFECT_1 ... KEY_N=VAL_N:TAINT_EFFECT_N [options]
增加taint
kubectl taint node k8s-node02 node-type=prod:NoSchedule
删除taint
kubectl taint node k8s-node02 node-type:NoSchedule-
tolerations
- key 被容忍的key
- tolerationSeconds 被驱逐的宽限时间,默认是0 就是立即被驱逐
- value 被容忍key的值
- operator Exists只要key在就可以调度,Equal(等值比较)必须是值要相同
- effect 节点调度后的操作
创建一个容忍
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas:
selector:
matchLabels:
app: myapp
release: dev
template:
metadata:
labels:
app: myapp
release: dev
spec:
containers:
- name: myapp-containers
image: ikubernetes/myapp:v2
ports:
- name: http
containerPort:
tolerations:
- key: "node-type"
operator: "Equal"
value: "prod"
effect: "NoSchedule"
Kubernetes之调度器和调度过程的更多相关文章
- Linux调度器 - deadline调度器
一.概述 实时系统是这样的一种计算系统:当事件发生后,它必须在确定的时间范围内做出响应.在实时系统中,产生正确的结果不仅依赖于系统正确的逻辑动作,而且依赖于逻辑动作的时序.换句话说,当系统收到某个请求 ...
- 重新梳理调度器——GMP 调度模型
调度器--GMP 调度模型 Goroutine 调度器,它是负责在工作线程上分发准备运行的 goroutines. 首先在讲 GMP 调度模型之前,我们先了解为什么会有这个模型,之前的调度模型是什么样 ...
- scrapy 基础组件专题(七):scrapy 调度器、调度器中间件、自定义调度器
一.调度器 配置 SCHEDULER = 'scrapy.core.scheduler.Scheduler' #表示scrapy包下core文件夹scheduler文件Scheduler类# 可以通过 ...
- Ambari和YARN的Capacity调度器,安装过程
用Spark测试YARN的资源池,测试过程中发现很多时候爆资源不够: 于是添加机器,专门用于跑spark:首先是ssh不通,原来错把71的id_psa.put文件拷贝到64上面:后来ssh通了,amb ...
- Kubernetes集群调度器原理剖析及思考
简述 云环境或者计算仓库级别(将整个数据中心当做单个计算池)的集群管理系统通常会定义出工作负载的规范,并使用调度器将工作负载放置到集群恰当的位置.好的调度器可以让集群的工作处理更高效,同时提高资源利用 ...
- 第十五章 Kubernetes调度器
一.简介 Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上.听起来非常简单,但有很多要考虑的问题: ① 公平:如何保证每个节点都能被分配资源 ② ...
- Kubernetes 调度器实现初探
Kubernetes 调度器 Kubernetes 是一个基于容器的分布式调度器,实现了自己的调度模块.在Kubernetes集群中,调度器作为一个独立模块通过pod运行.从几个方面介绍Kuberne ...
- Kubernetes K8S之调度器kube-scheduler详解
Kubernetes K8S之调度器kube-scheduler概述与详解 kube-scheduler调度概述 在 Kubernetes 中,调度是指将 Pod 放置到合适的 Node 节点上,然后 ...
- kubernetes机理之调度器以及控制器
一 了解调度器 1.1 调度器是如何将一个pod调度到节点上的 我们都已然知晓了,API服务器不会主动的去创建pod,只是拉起系统组件,这些组件订阅资源状态的通知,之后创建相应的资源,而负责调度po ...
随机推荐
- Your project path contains non-ASCII characters
Android studio导入project时报错 non-ASCII characters意味着中文字符报错,解决方法简单有效: 检查项目路径中是否出现中文名,将中文字符修改成英文就可以解决辽~
- Java使用PipedStream管道流通信
多线程使用PipedStream 通讯 Java 提供了四个相关的管道流,我们可以使用其在多线程进行数据传递,其分别是 类名 作用 备注 PipedInputStream 字节管道输入流 字节流 Pi ...
- 20年硅谷技术牛人到访DataPipeline谈:技术如何与业务平衡发展
导读:技术人员的常态是“左手支持业务签单,右手提升系统性能”,却经常陷入技术和业务该如何平衡发展的困惑?今天,且听一位硅谷牛人分享他的平衡之道. 以个人名誉申请31个国内外技术和产品专利,中国最佳CT ...
- servlet之转发与重定向的区别
转发(服务器端跳转): 一次请求 <jsp:forward> request.getRequestDispatcher("new.jsp").forward(requ ...
- Ubuntu 16.04 屏幕亮度无法调节怎么办
安装好ubuntu 16.04之后,发现屏幕超亮,找不到调节按钮,这应该是系统的一个漏洞, 不过可以安装工具来操作,从而解决亮度调节问题,下面是安装 Brightness Controller 的方 ...
- Linux内核入门到放弃-页面回收和页交换-《深入Linux内核架构》笔记
概述 可换出页 只有少量几种页可以换出到交换区,对其他页来说,换出到块设备上与之对应的后备存储器即可,如下所述. 类别为 MAP_ANONYMOUS 的页,没有关联到文件,例如,这可能是进程的栈或是使 ...
- Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来. 今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴 ...
- day11(函数参数,函数对象,打散机制,函数嵌套调用)
一,复习 # 什么是函数:具体特定功能的代码块 - 特定功能代码块作为一个整体,并给该整体命名,就是函数 # 函数的优点: # 1.减少代码的冗余 # 2.结构清晰,可读性强 # 3.具有复用性,开发 ...
- Day9 轨道角动量
转自中山大学电子与信息工程 http://seit.sysu.edu.cn/node/1004 能量.动量(角动量和线动量)光子的基本属性,其中光子角动量包括自旋角动量和轨道角动量(Orbital a ...
- visual studio 配置属性中增加自定义宏和宏值
visual studio中有一些预先定义的宏,用于配置项目属性,如SolutionDir.我们也可以自定义类似的宏,从而在配置包含目录(include)或添加依赖项时简化配置项. 如何创建自己的宏呢 ...