Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来。
今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴,怎么办呢?办法总是有的,即便没有我们也可以创造一个办法。

下面就看看我今天写的程序:
#coding=utf-8 #urllib模块提供了读取Web页面数据的接口
import urllib.request
#re模块主要包含了正则表达式
import re
#定义一个getHtml()函数
def getHtml(url):
page = urllib.request.urlopen(url) #urllib.request.urlopen()方法用于打开一个URL地址
html = page.read() #read()方法用于读取URL上的数据
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext' #正则表达式,得到图片地址
imgre = re.compile(reg) #re.compile() 可以把正则表达式编译成一个正则表达式对象.
html = html.decode('utf-8') #python3
imglist = re.findall(imgre,html) #re.findall() 方法读取html 中包含 imgre(正则表达式)的数据
#把筛选的图片地址通过for循环遍历并保存到本地
#核心是urllib.request.urlretrieve()方法,直接将远程数据下载到本地,图片通过x依次递增命名
x = 0 for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'D:\E\%s.jpg' % x)
x += 1 html = getHtml("https://tieba.baidu.com/p/xxxxxxxx")
print(getImg(html))
运行程序后,下面就是见证奇迹的时刻,打开对应文件夹:
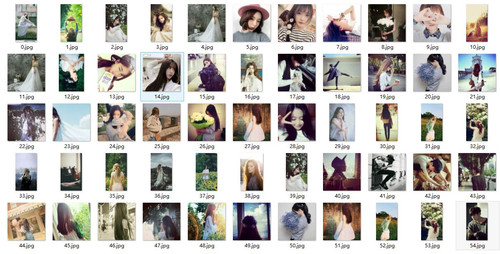
哇!图片全部保存了下来,so nice! :-)
2019年1月更新备注:
此前代码为2015年Python2.x环境测试,现在已将代码更新,测试环境为Python3.7 ,注意请在D盘新建一个文件夹重命名为E
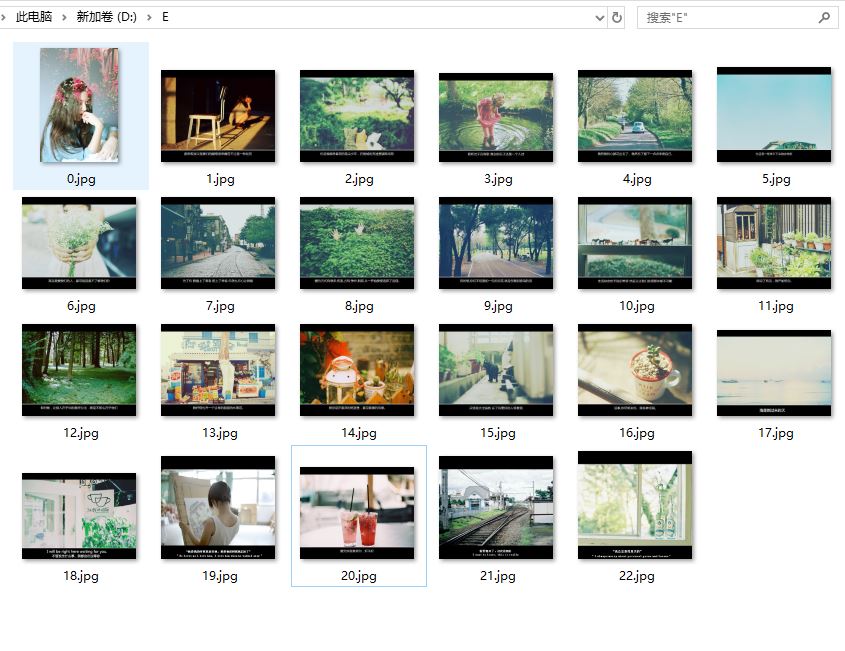
测试网址:https://tieba.baidu.com/p/2555125530
测试结果如图:
Python爬虫爬取网页图片的更多相关文章
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- erlang 爬虫——爬取网页图片
说起爬虫,大家第一印象就是想到了python来做爬虫.其实,服务端语言好些都可以来实现这个东东. 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌 ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
随机推荐
- JDK中的Atomic包中的类及使用
引言 Java从JDK1.5开始提供了java.util.concurrent.atomic包,方便程序员在多线程环境下,无锁的进行原子操作.原子变量的底层使用了处理器提供的原子指令,但是不同的CPU ...
- 【Python实践-2】求一个或多个数的乘积
# -*- coding: utf-8 -*- #定义一个函数,可接收一个或多个数并计算乘积 def product(*numbers): s=1 for n in numbers: s=s*n re ...
- 跟我一起学opencv 第三课之图像在opencv中的表示-Mat对象
1.下面第一章图是一位美女图像,和其他数据一样图像在计算机中也是以二进制存储,下面第二张图 2.在摄像头眼里一幅图像就是一个矩阵或者说是二维数组,数组元素是像素值 3.opencv中以Mat对象表示图 ...
- 【视频】ASP.NET Core MVC 2.* 入门
比较初级的入门教程,网址在B站:https://www.bilibili.com/video/av33728783/ 内容如下: 1. ASP.NET Core 简介和开发工具 2. ASP.NET ...
- Java微服务之Spring Boot on Docker
本文学习前提:Java, Spring Boot, Docker, Spring Cloud 一.准备工作 1.1 安装Docker环境 这一部分请参考我的另一篇文章<ASP.NET Core ...
- Node.js 命令行工具的编写
日常开发中,编写 Node.js 命令行工具来完成一些小任务是很常见的操作.其编写也不难,和日常编写 Node.js 代码并无二致. package.json 中的 bin 字段 一个 npm 模块, ...
- .NET Core开发者的福音之玩转Redis的又一傻瓜式神器推荐
作者:依乐祝 原本链接:https://www.cnblogs.com/yilezhu/p/9947905.html 引子 为什么写这篇文章呢?因为.NET Core的生态越来越好了!之前玩转.net ...
- 学习ASP.NET Core Razor 编程系列十二——在页面中增加校验
学习ASP.NET Core Razor 编程系列目录 学习ASP.NET Core Razor 编程系列一 学习ASP.NET Core Razor 编程系列二——添加一个实体 学习ASP.NET ...
- 为Qt视图中的文字添加彩虹渐变效果
将view中的文本内容用自定义的颜色显示是一种十分常见的需求.今天我们稍微改变些"花样". 本文索引 需求定义 需求分析 代码实现 思考题 需求定义 我们的需求很简单,现在有一些在 ...
- [转]Blue Prism Interview Questions and Answers
本文转自:https://www.rpatraining.co.in/blue-prism-interview-questions/ What is a Visual Business Object? ...