19.通过MAPREDUCE 把收集数据进行清洗
在eclipse软件里创建一个maven项目
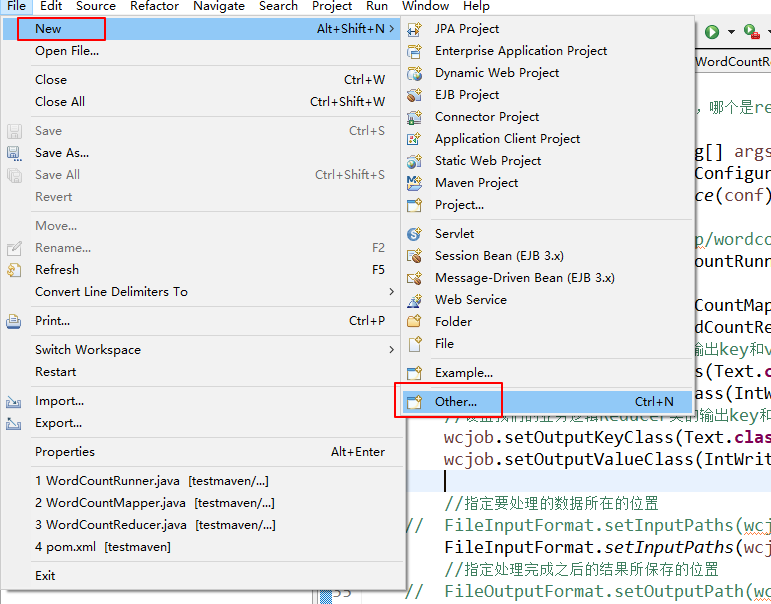
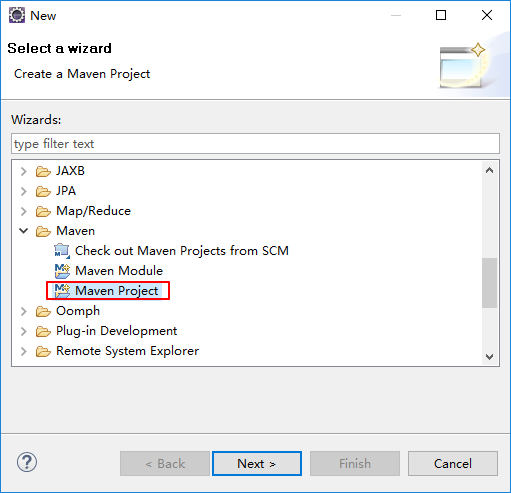
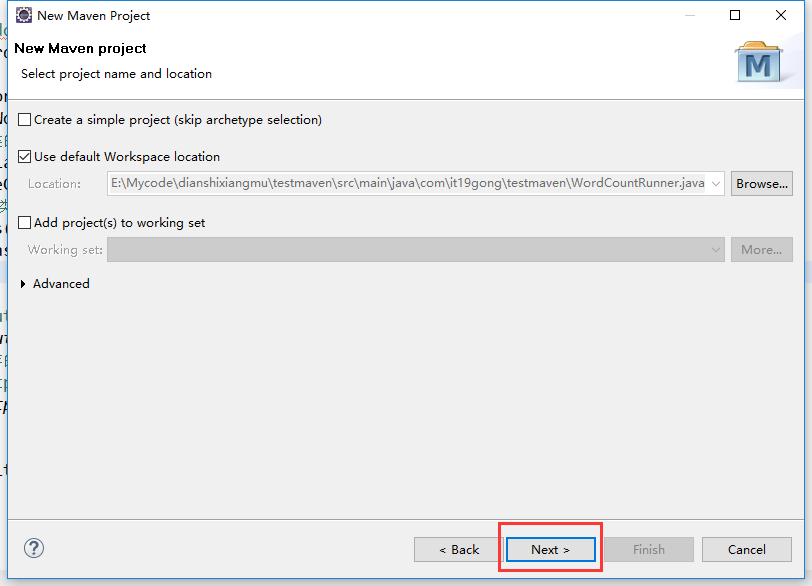
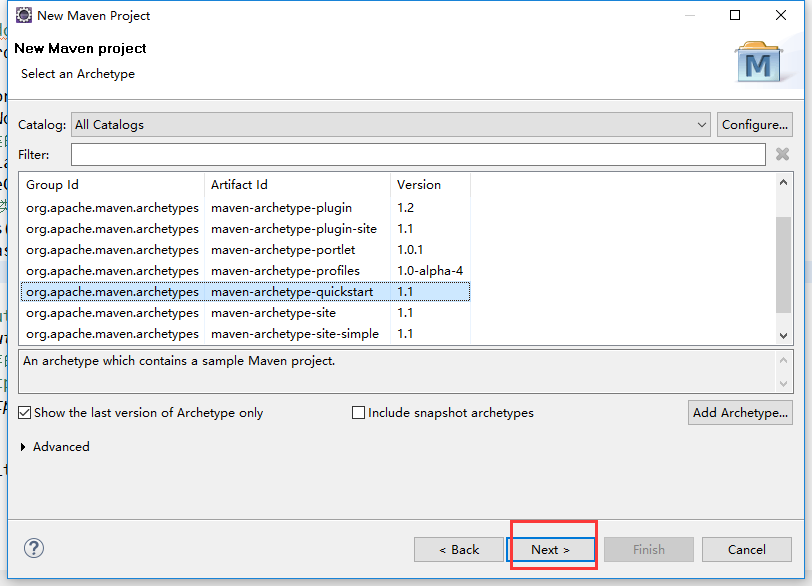
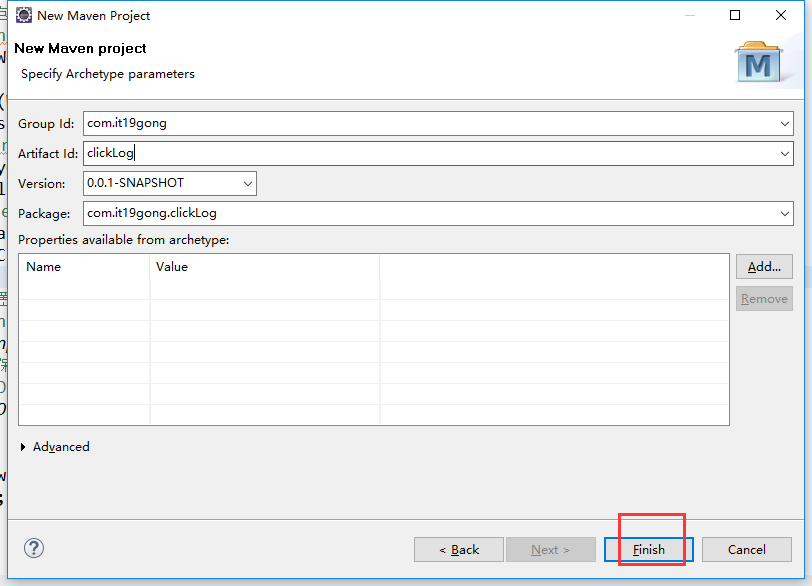
jdk要换成本地安装的1.8版本的
加载pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.it19gong</groupId>
<artifactId>clickLog</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>clickLog</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency> <dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>E:/software/jdk1.8/lib/tools.jar</systemPath>
</dependency> <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.0</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.33</version>
</dependency>
</dependencies> </project>
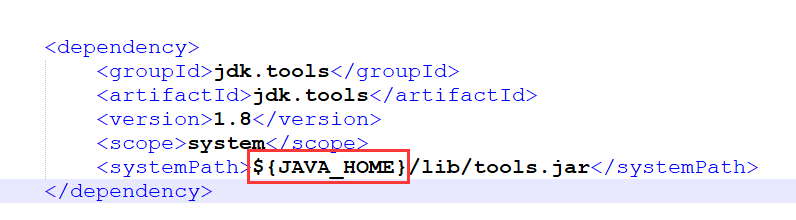
在加载依赖包的时候如果出现错误,在仓库里找不到1.8jdk.tools
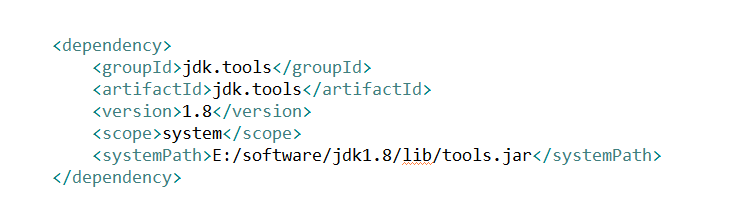
在这个地方改成本地的jdk绝对路径,再重新加载一次maven的依赖包
我这里修改成
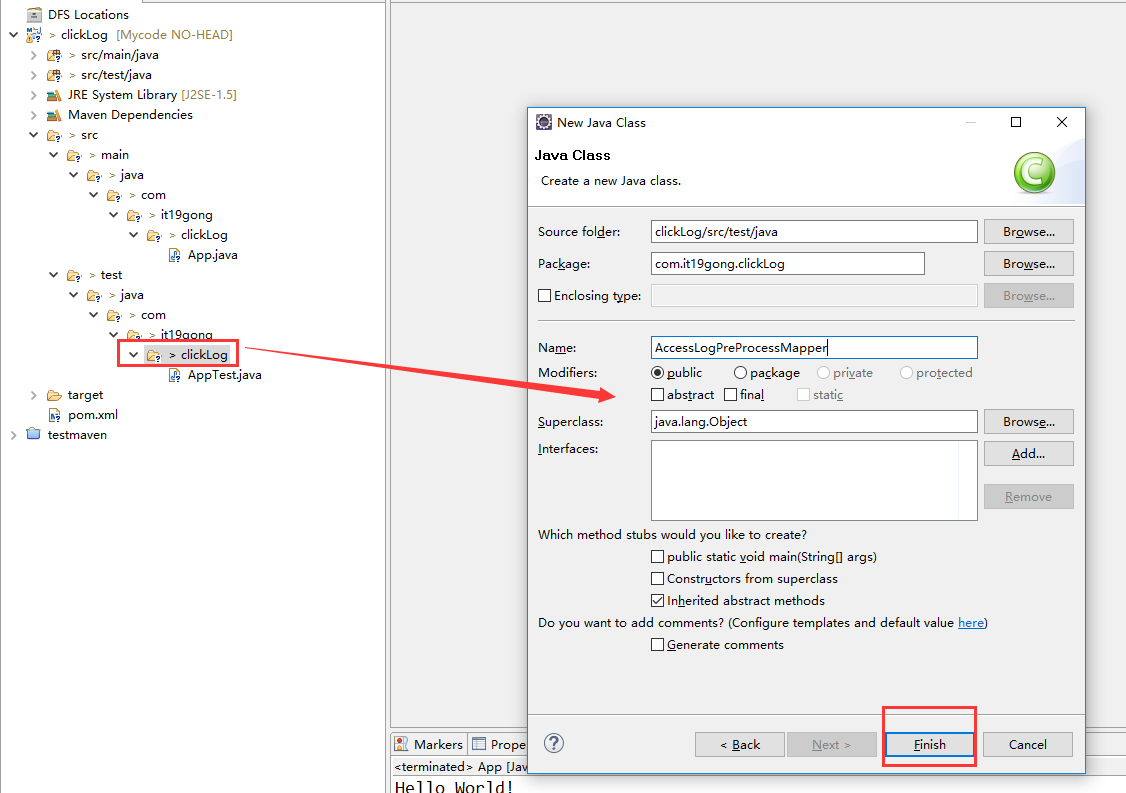
在项目下新建AccessLogPreProcessMapper类
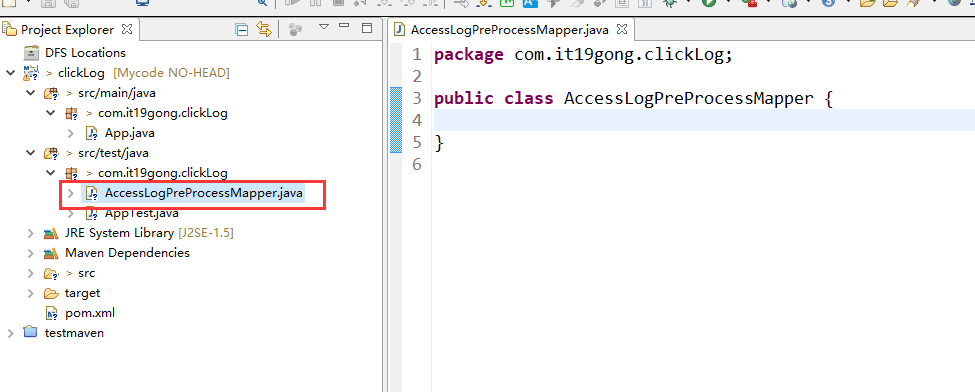
package com.it19gong.clickLog; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class AccessLogPreProcessMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
Text text = new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String itr[] = value.toString().split(" ");
if (itr.length < 11)
{
return;
}
String ip = itr[0];
String date = AnalysisNginxTool.nginxDateStmpToDate(itr[3]);
String url = itr[6];
String upFlow = itr[9]; text.set(ip+","+date+","+url+","+upFlow);
context.write(text, NullWritable.get()); }
}
创建AnalysisNginxTool类
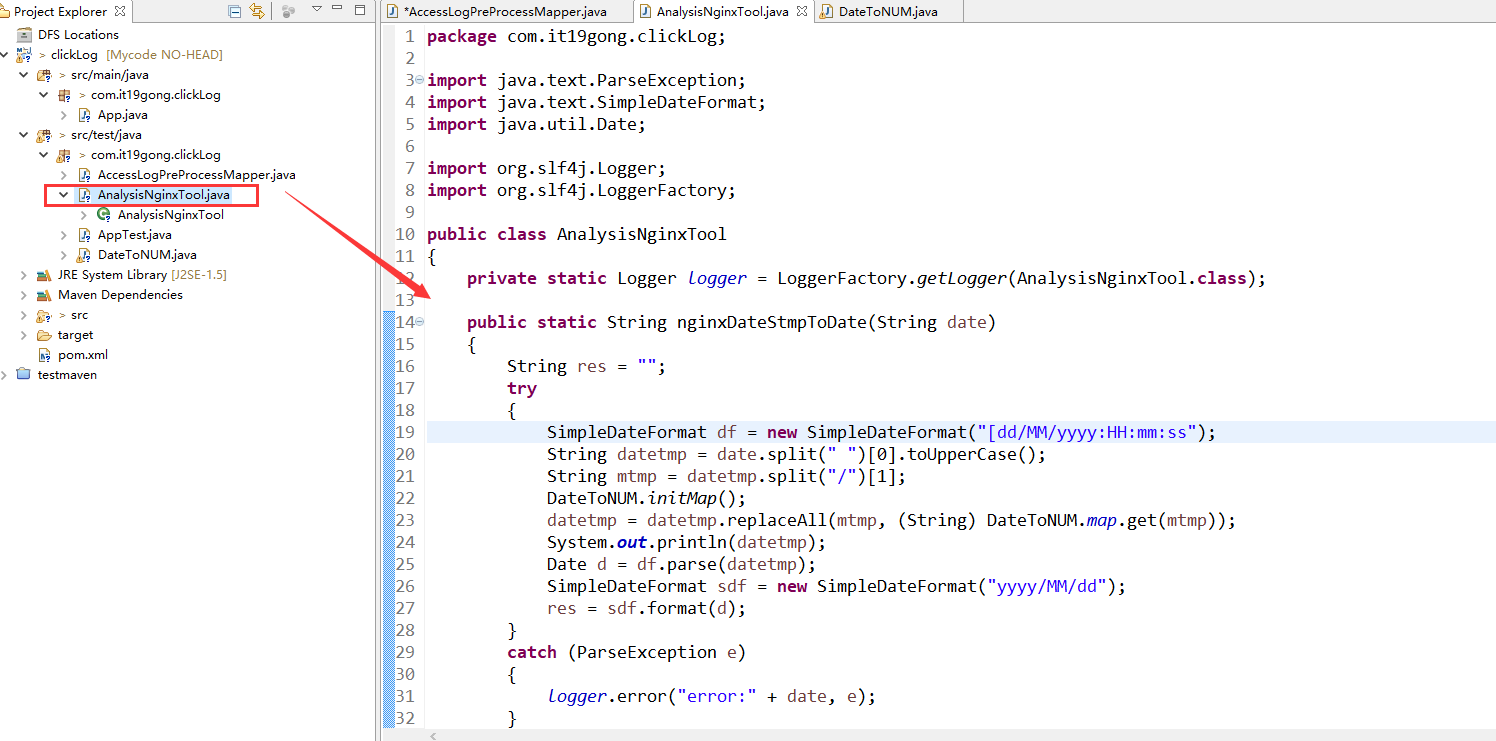
package com.it19gong.clickLog; import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class AnalysisNginxTool
{
private static Logger logger = LoggerFactory.getLogger(AnalysisNginxTool.class); public static String nginxDateStmpToDate(String date)
{
String res = "";
try
{
SimpleDateFormat df = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss");
String datetmp = date.split(" ")[0].toUpperCase();
String mtmp = datetmp.split("/")[1];
DateToNUM.initMap();
datetmp = datetmp.replaceAll(mtmp, (String) DateToNUM.map.get(mtmp));
System.out.println(datetmp);
Date d = df.parse(datetmp);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd");
res = sdf.format(d);
}
catch (ParseException e)
{
logger.error("error:" + date, e);
}
return res;
} public static long nginxDateStmpToDateTime(String date)
{
long l = 0;
try
{
SimpleDateFormat df = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss");
String datetmp = date.split(" ")[0].toUpperCase();
String mtmp = datetmp.split("/")[1];
datetmp = datetmp.replaceAll(mtmp, (String) DateToNUM.map.get(mtmp)); Date d = df.parse(datetmp);
l = d.getTime();
}
catch (ParseException e)
{
logger.error("error:" + date, e);
}
return l;
}
}
创建DateToNUM类
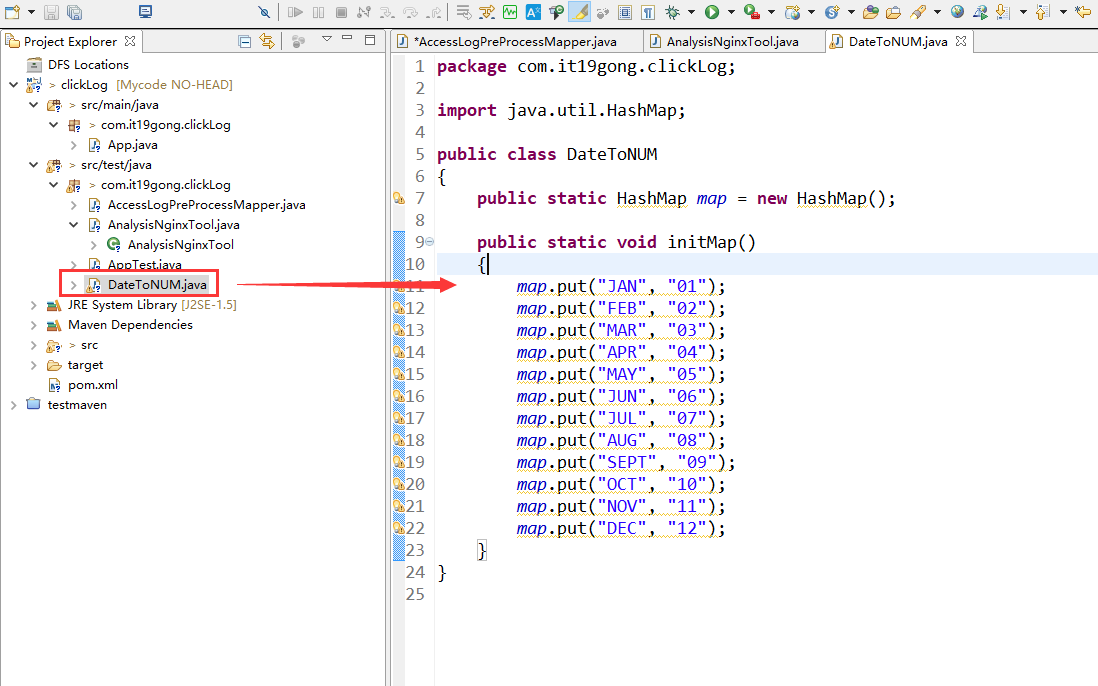
package com.it19gong.clickLog; import java.util.HashMap; public class DateToNUM
{
public static HashMap map = new HashMap(); public static void initMap()
{
map.put("JAN", "01");
map.put("FEB", "02");
map.put("MAR", "03");
map.put("APR", "04");
map.put("MAY", "05");
map.put("JUN", "06");
map.put("JUL", "07");
map.put("AUG", "08");
map.put("SEPT", "09");
map.put("OCT", "10");
map.put("NOV", "11");
map.put("DEC", "12");
}
}
新建AccessLogDriver类
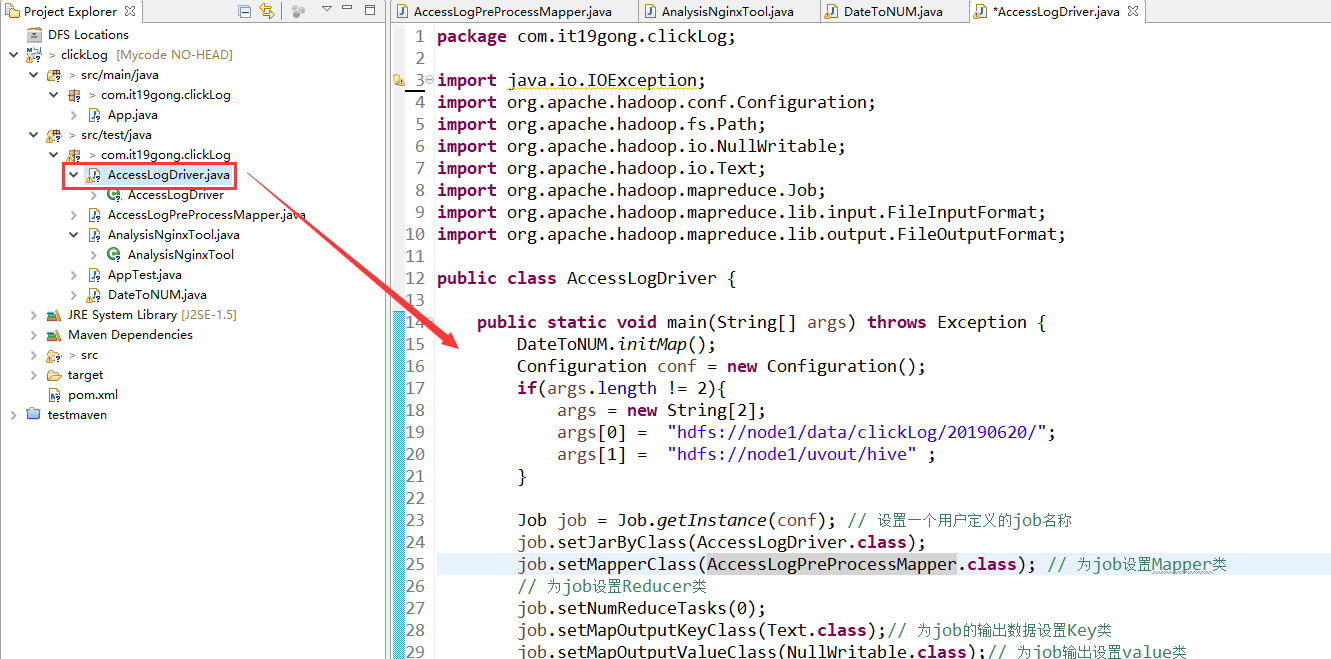
package com.it19gong.clickLog; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class AccessLogDriver { public static void main(String[] args) throws Exception {
DateToNUM.initMap();
Configuration conf = new Configuration();
if(args.length != 2){
args = new String[2];
args[0] = "hdfs://node1/data/clickLog/20190620/";
args[1] = "hdfs://node1/uvout/hive" ;
} Job job = Job.getInstance(conf); // 设置一个用户定义的job名称
job.setJarByClass(AccessLogDriver.class);
job.setMapperClass(AccessLogPreProcessMapper.class); // 为job设置Mapper类
// 为job设置Reducer类
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);// 为job的输出数据设置Key类
job.setMapOutputValueClass(NullWritable.class);// 为job输出设置value类
FileInputFormat.addInputPath(job, new Path(args[0])); // 为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 为job设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1); // 运行job
} }
把工程打包成Jar包
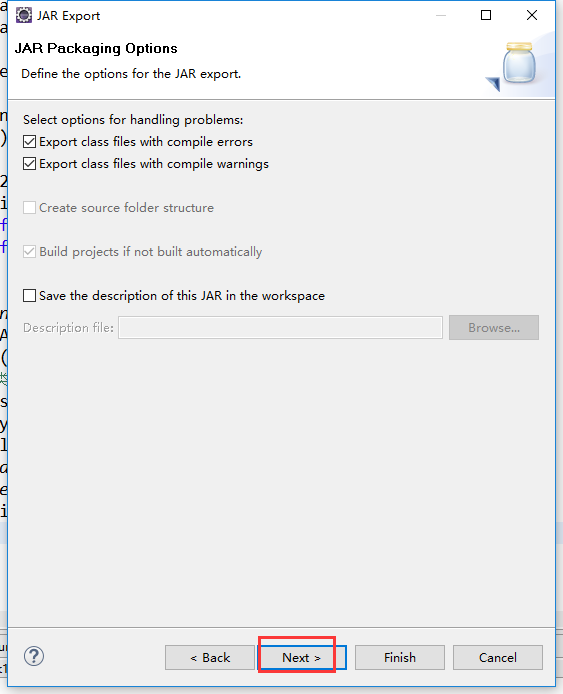
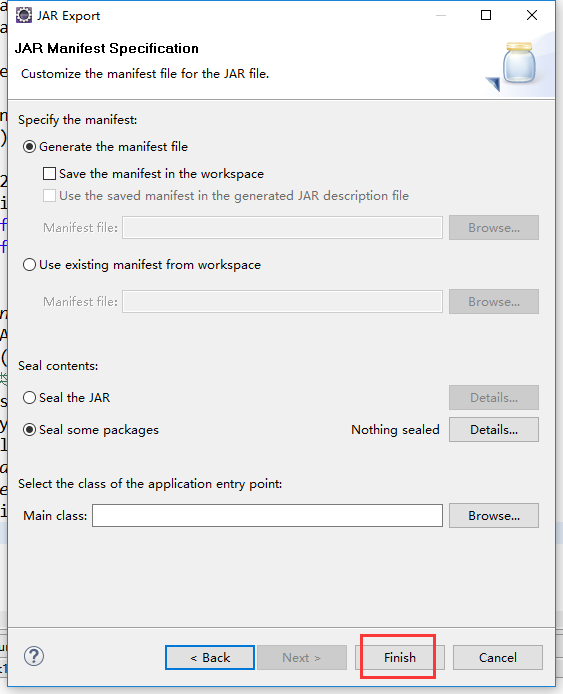
把jar包上传到集群

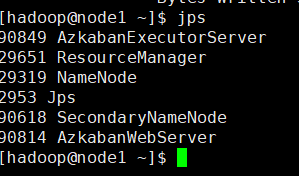
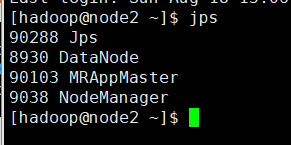
在集群上运行一下,先检查一下集群的启动进程

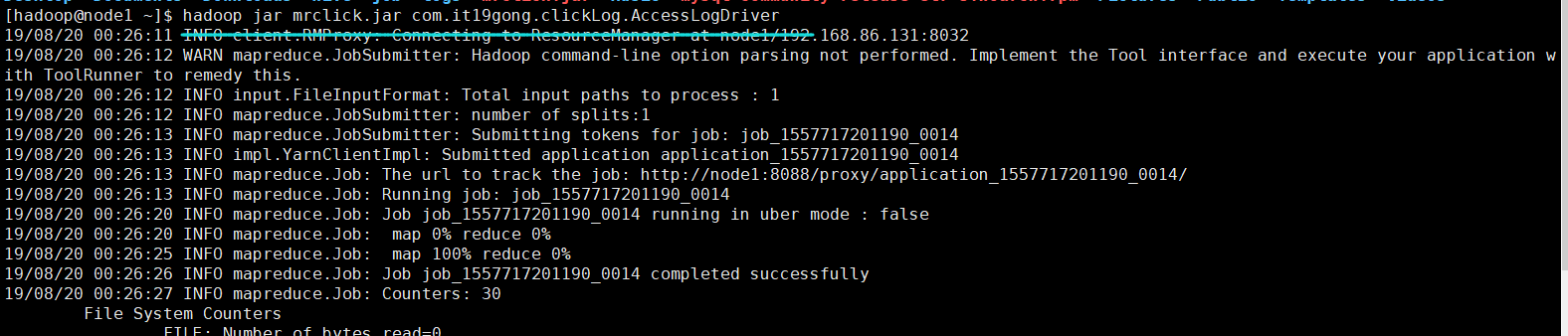
hadoop jar mrclick.jar com.it19gong.clickLog.AccessLogDriver
可以看到输出目录
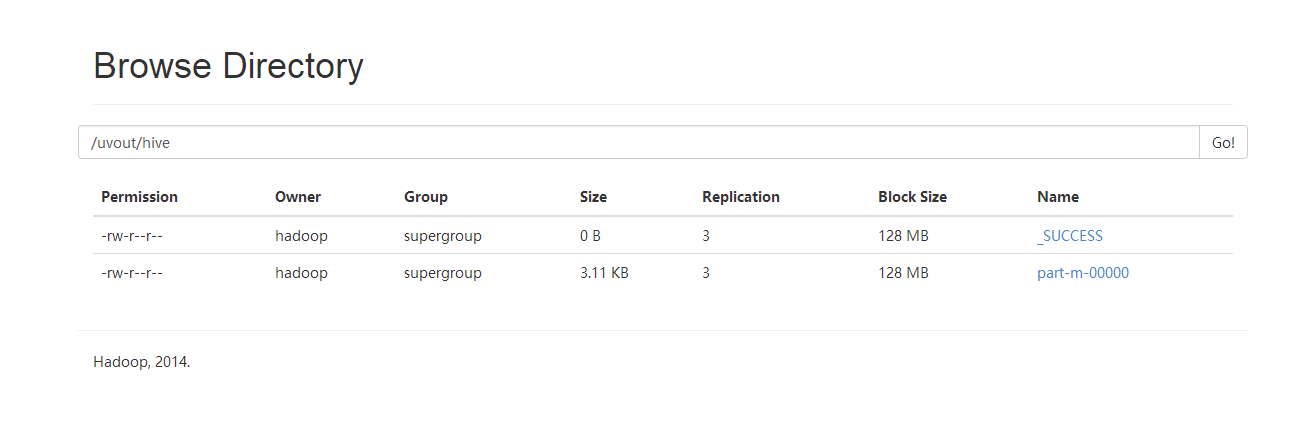
查看清洗后的数据
19.通过MAPREDUCE 把收集数据进行清洗的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- Hadoop生态圈-使用MapReduce处理HBase数据
Hadoop生态圈-使用MapReduce处理HBase数据 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.对HBase表中数据进行单词统计(TableInputFormat) ...
- 使用MapReduce将HDFS数据导入Mysql
使用MapReduce将Mysql数据导入HDFS代码链接 将HDFS数据导入Mysql,代码示例 package com.zhen.mysqlToHDFS; import java.io.DataI ...
- 使用MapReduce将mysql数据导入HDFS
package com.zhen.mysqlToHDFS; import java.io.DataInput; import java.io.DataOutput; import java.io.IO ...
- 使用hadoop mapreduce分析mongodb数据
使用hadoop mapreduce分析mongodb数据 (现在很多互联网爬虫将数据存入mongdb中,所以研究了一下,写此文档) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明 ...
- 【原创】MapReduce备份Elasticsearch数据到HDFS(JAVA)
一.环境:JAVA8,Elasticsearch-5.6.2,Hadoop-2.8.1二.实现功能:mapreduce读elasticsearch数据.输出parquet文件.多输出路径三.主要依赖 ...
- Java 8 (5) Stream 流 - 收集数据
在前面已经使用过collect终端操作了,主要是用来把Stream中的所有元素结合成一个List,在本章中,你会发现collect是一个归约操作,就像reduce一样可以接受各种做法作为参数,将流中的 ...
- java8中用流收集数据
用流收集数据 汇总 long howManyDishes = menu.stream().collect(Collectors.counting()); int totalCalories = men ...
- 《Java 8 in Action》Chapter 6:用流收集数据
1. 收集器简介 collect() 接收一个类型为 Collector 的参数,这个参数决定了如何把流中的元素聚合到其它数据结构中.Collectors 类包含了大量常用收集器的工厂方法,toLis ...
随机推荐
- Java进阶知识11 Hibernate多对多单向关联(Annotation+XML实现)
1.Annotation 注解版 1.1.应用场景(Student-Teacher):当学生知道有哪些老师教,但是老师不知道自己教哪些学生时,可用单向关联 1.2.创建Teacher类和Student ...
- 小米oj 判断是否为连乘数字串
判断是否为连乘数字串 序号:#32难度:非常难时间限制:1000ms内存限制:10M 描述 给出一个字符串S,判断S是否为连乘字符串. 连乘字符串定义为: 字符串拆分成若干数字,后面的数字(从第三个 ...
- HDU 3081 Marriage Match II 最大流OR二分匹配
Marriage Match IIHDU - 3081 题目大意:每个女孩子可以和没有与她或者是她的朋友有过争吵的男孩子交男朋友,现在玩一个游戏,每一轮每个女孩子都要交一个新的男朋友,问最多可以玩多少 ...
- matlab 计算灰度图像的一阶矩、二阶矩、三阶矩
一阶矩,定义了每个颜色分量的平均强度 二阶矩,反映待测区域颜色方差,即不均匀性 三阶矩,定义了颜色分量的偏斜度,即颜色的不对称性 close all;clear all;clc; ...
- 0 - Visualizing and Understanding Convolutional Networks(阅读翻译)
卷积神经网络的可视化理解(Visualizing and Understanding Convolutional Networks) 摘要(Abstract) 近来,大型的卷积神经网络模型在Image ...
- 我的zshrc文件设置备份
# If you come from bash you might have to change your $PATH. # export PATH=$HOME/bin:/usr/local/bin: ...
- 【零基础】Selenium:Webdriver图文入门教程java篇(附相关包下载)
一.selenium2.0简述 与一般的浏览器测试框架(爬虫框架)不同,Selenium2.0实际上由两个部分组成Selenium+webdriver,Selenium负责用户指令的解释(code), ...
- 剑指offer35----复制复杂链表
题目: 请实现一个cloneNode方法,复制一个复杂链表. 在复杂链表中,每个结点除了有一个next指针指向下一个结点之外,还有一个random指向链表中的任意结点或者NULL. 结点的定义如下: ...
- python中的break continue之用法
Break break跳出循环,并且终止最小封闭循环. Continue continue跳过本次循环,继续执行下一次的循环. 二者区别就是break会终止循环,continue不终止循环.
- php 中 使用foreach为数组增加键值对
php 中的 foreach 在php中,使用foreach来遍历数组的频率很高,并且其性能要高于 list() 和 each() 结合来遍历数组: 当遍历二位数组的第一层数组,并要给第二位数组增加一 ...