19.通过MAPREDUCE 把收集数据进行清洗
在eclipse软件里创建一个maven项目
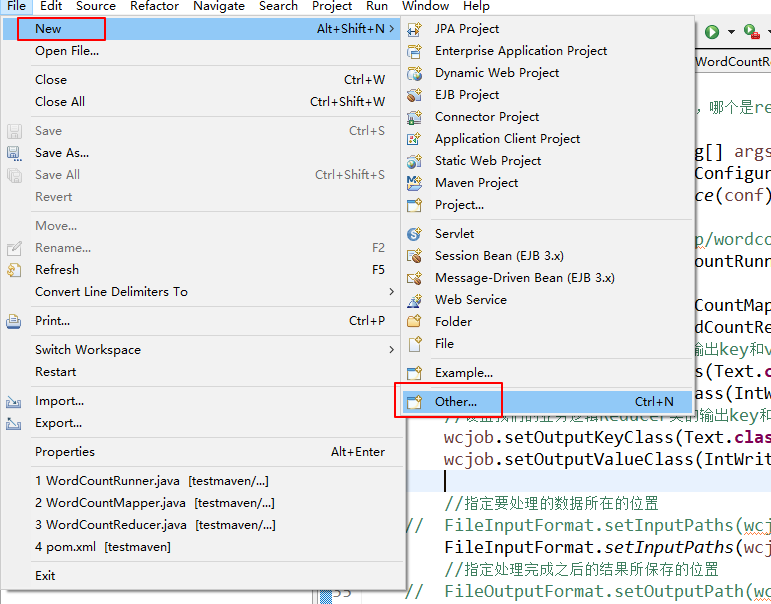
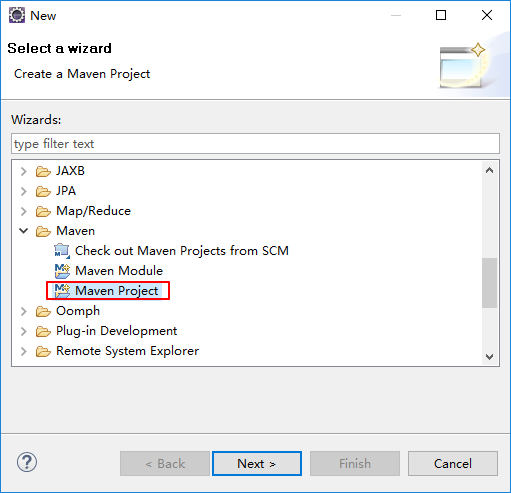
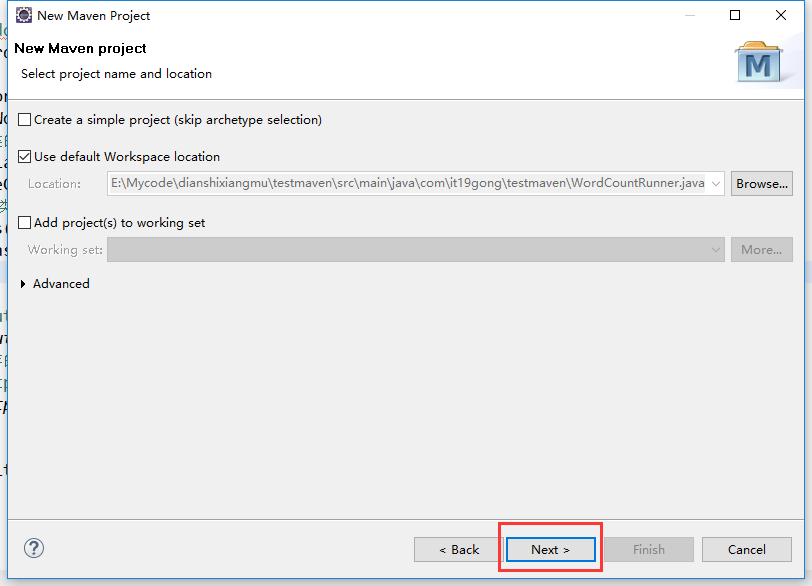
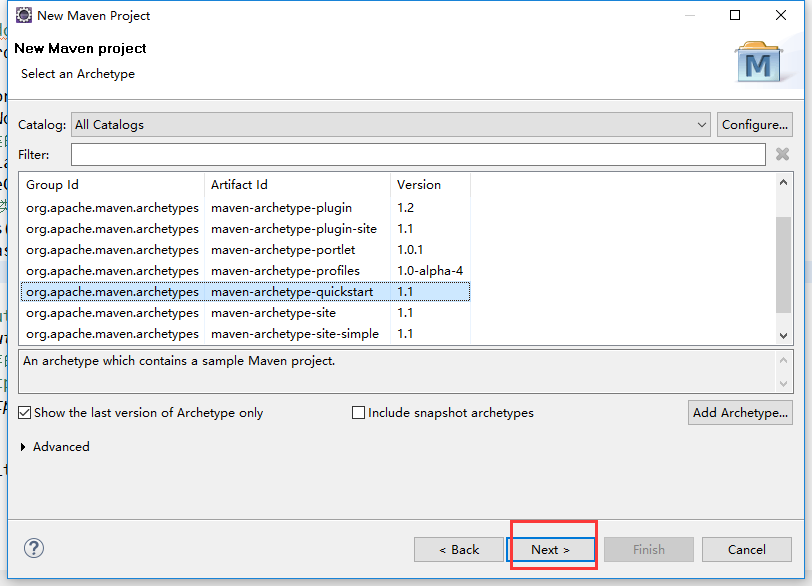
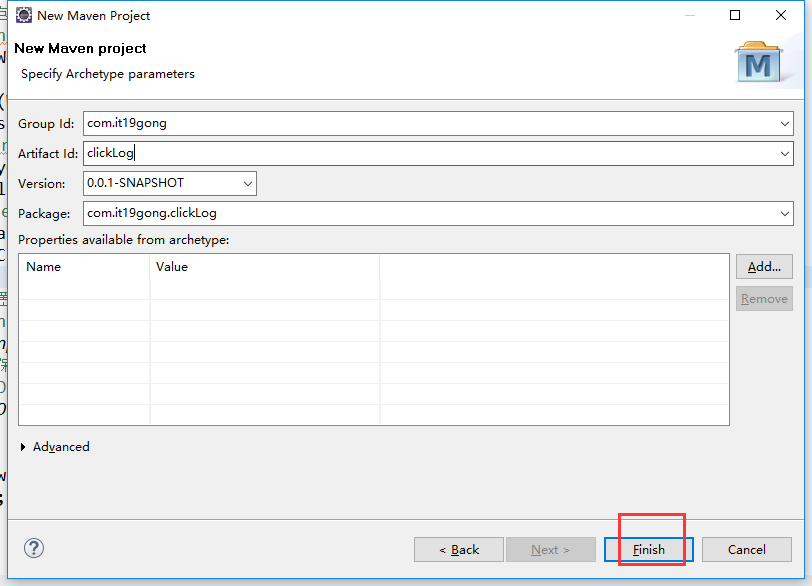
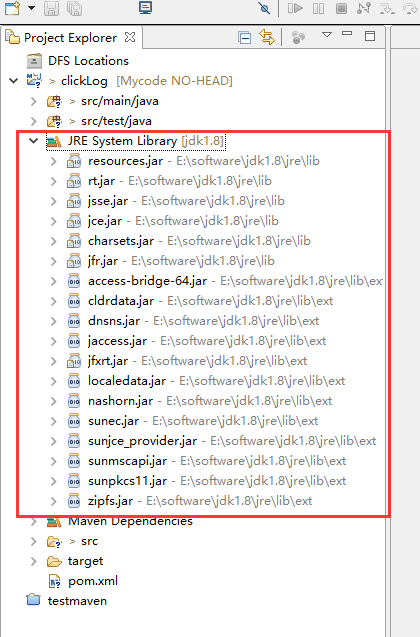
jdk要换成本地安装的1.8版本的
加载pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.it19gong</groupId>
<artifactId>clickLog</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>clickLog</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency> <dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>E:/software/jdk1.8/lib/tools.jar</systemPath>
</dependency> <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.0</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.33</version>
</dependency>
</dependencies> </project>
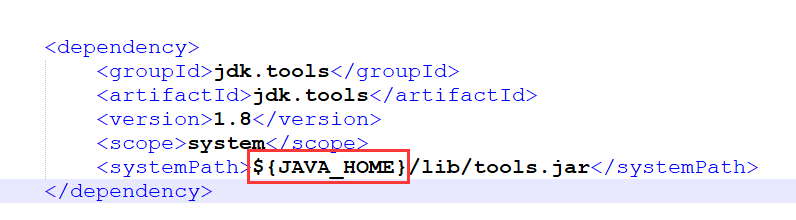
在加载依赖包的时候如果出现错误,在仓库里找不到1.8jdk.tools
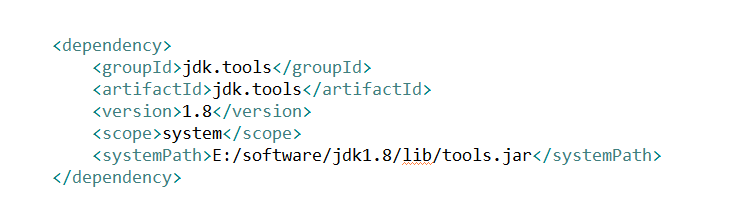
在这个地方改成本地的jdk绝对路径,再重新加载一次maven的依赖包
我这里修改成
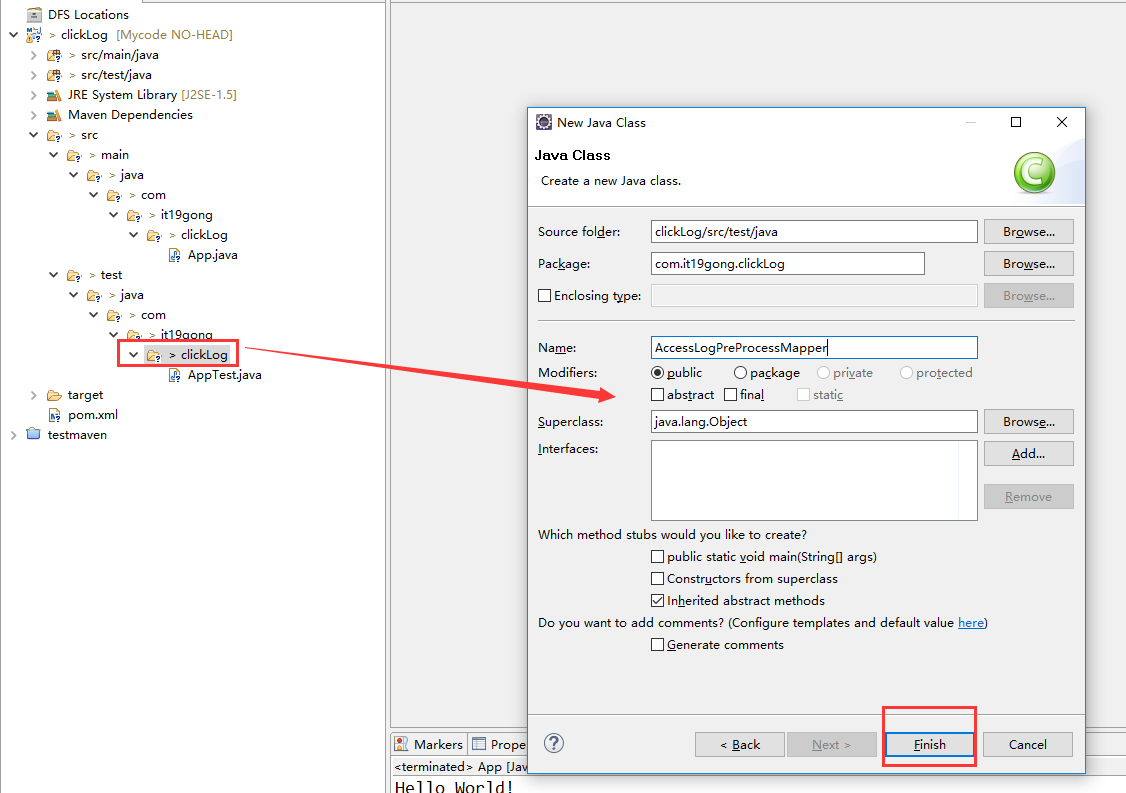
在项目下新建AccessLogPreProcessMapper类
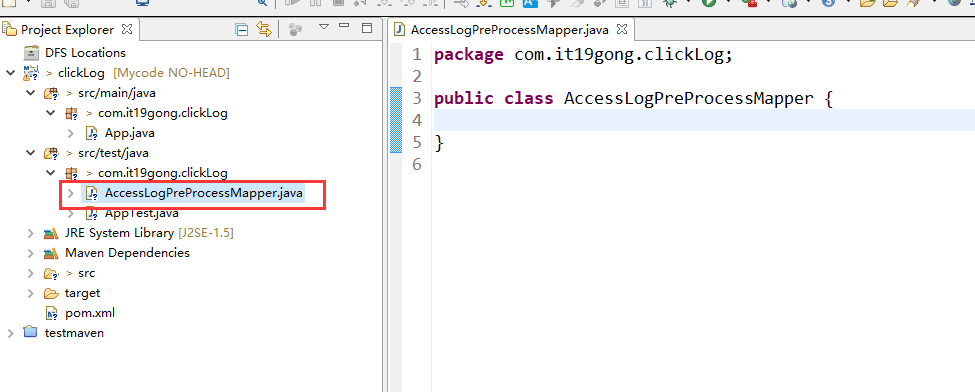
package com.it19gong.clickLog; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class AccessLogPreProcessMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
Text text = new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String itr[] = value.toString().split(" ");
if (itr.length < 11)
{
return;
}
String ip = itr[0];
String date = AnalysisNginxTool.nginxDateStmpToDate(itr[3]);
String url = itr[6];
String upFlow = itr[9]; text.set(ip+","+date+","+url+","+upFlow);
context.write(text, NullWritable.get()); }
}
创建AnalysisNginxTool类
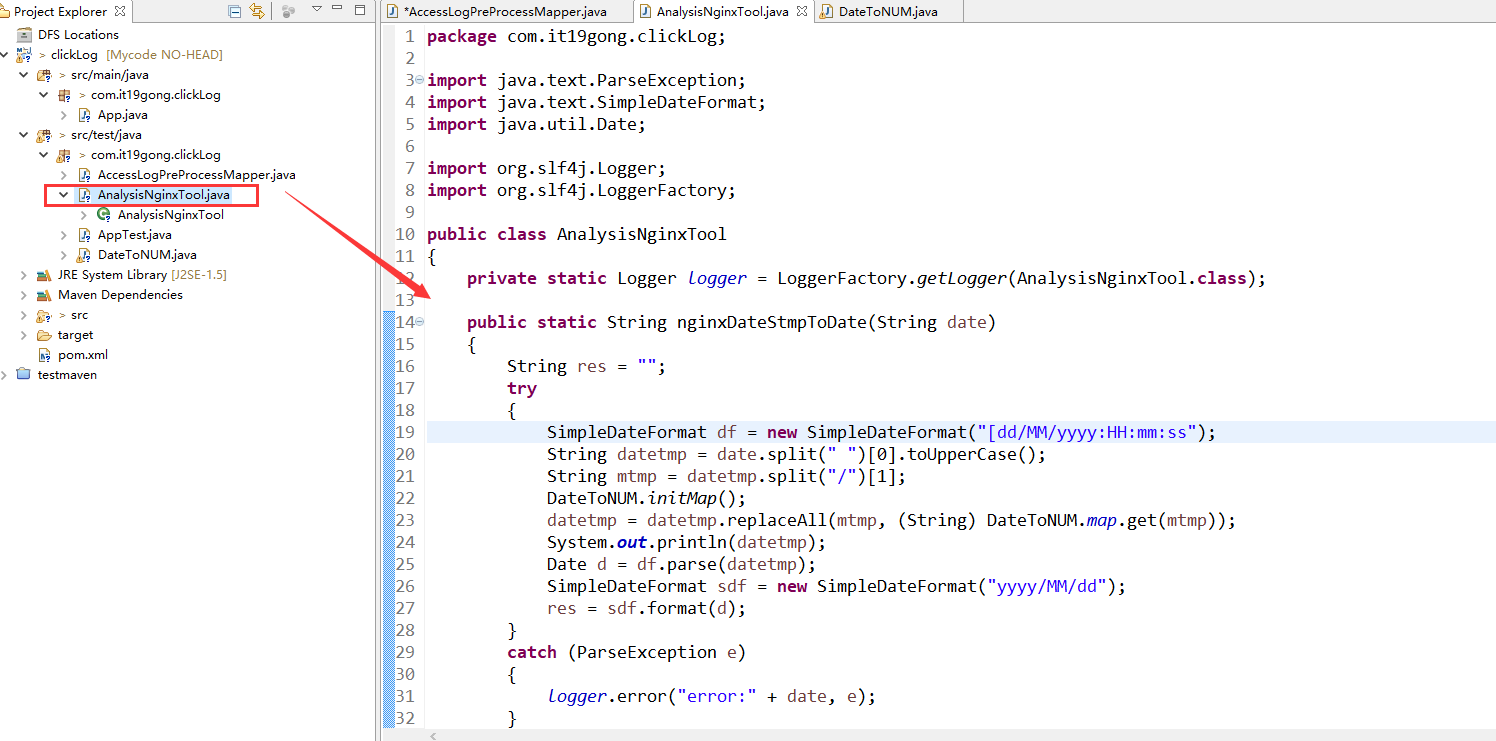
package com.it19gong.clickLog; import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class AnalysisNginxTool
{
private static Logger logger = LoggerFactory.getLogger(AnalysisNginxTool.class); public static String nginxDateStmpToDate(String date)
{
String res = "";
try
{
SimpleDateFormat df = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss");
String datetmp = date.split(" ")[0].toUpperCase();
String mtmp = datetmp.split("/")[1];
DateToNUM.initMap();
datetmp = datetmp.replaceAll(mtmp, (String) DateToNUM.map.get(mtmp));
System.out.println(datetmp);
Date d = df.parse(datetmp);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd");
res = sdf.format(d);
}
catch (ParseException e)
{
logger.error("error:" + date, e);
}
return res;
} public static long nginxDateStmpToDateTime(String date)
{
long l = 0;
try
{
SimpleDateFormat df = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss");
String datetmp = date.split(" ")[0].toUpperCase();
String mtmp = datetmp.split("/")[1];
datetmp = datetmp.replaceAll(mtmp, (String) DateToNUM.map.get(mtmp)); Date d = df.parse(datetmp);
l = d.getTime();
}
catch (ParseException e)
{
logger.error("error:" + date, e);
}
return l;
}
}
创建DateToNUM类
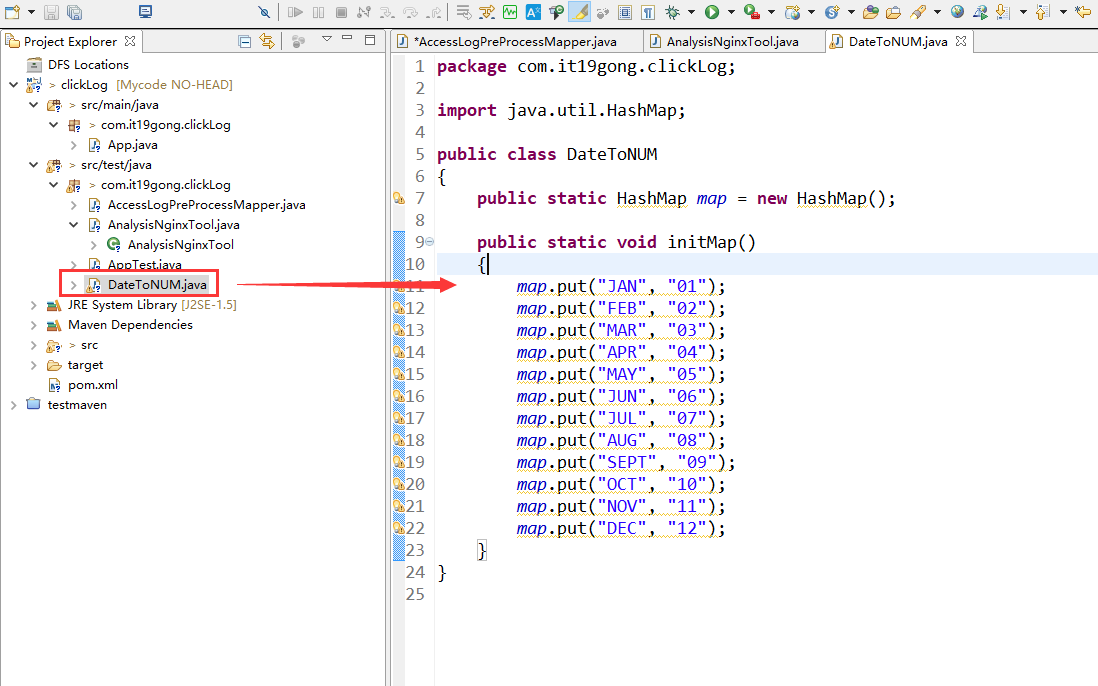
package com.it19gong.clickLog; import java.util.HashMap; public class DateToNUM
{
public static HashMap map = new HashMap(); public static void initMap()
{
map.put("JAN", "01");
map.put("FEB", "02");
map.put("MAR", "03");
map.put("APR", "04");
map.put("MAY", "05");
map.put("JUN", "06");
map.put("JUL", "07");
map.put("AUG", "08");
map.put("SEPT", "09");
map.put("OCT", "10");
map.put("NOV", "11");
map.put("DEC", "12");
}
}
新建AccessLogDriver类
package com.it19gong.clickLog; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class AccessLogDriver { public static void main(String[] args) throws Exception {
DateToNUM.initMap();
Configuration conf = new Configuration();
if(args.length != 2){
args = new String[2];
args[0] = "hdfs://node1/data/clickLog/20190620/";
args[1] = "hdfs://node1/uvout/hive" ;
} Job job = Job.getInstance(conf); // 设置一个用户定义的job名称
job.setJarByClass(AccessLogDriver.class);
job.setMapperClass(AccessLogPreProcessMapper.class); // 为job设置Mapper类
// 为job设置Reducer类
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);// 为job的输出数据设置Key类
job.setMapOutputValueClass(NullWritable.class);// 为job输出设置value类
FileInputFormat.addInputPath(job, new Path(args[0])); // 为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 为job设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1); // 运行job
} }
把工程打包成Jar包
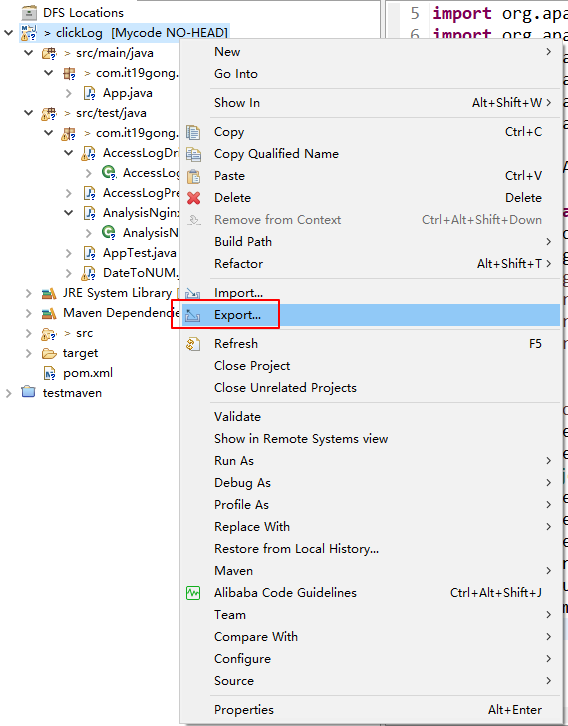
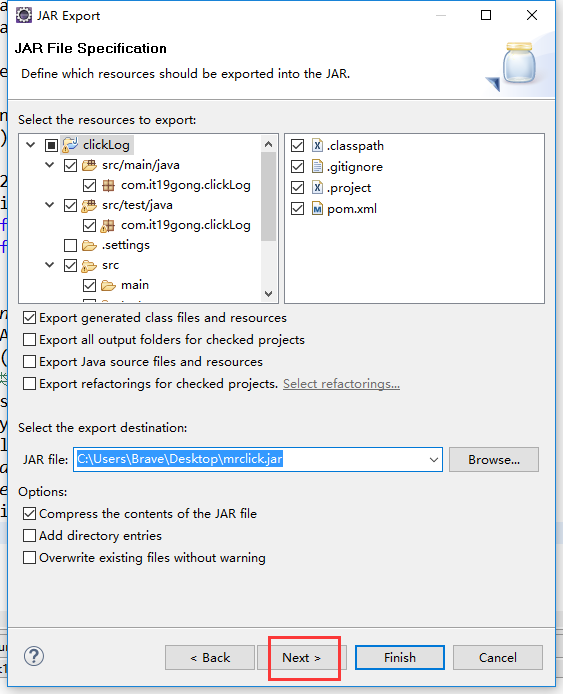
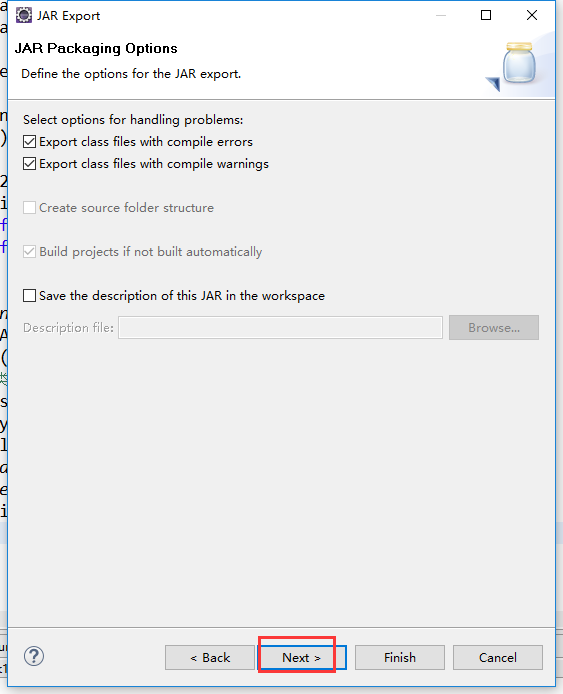
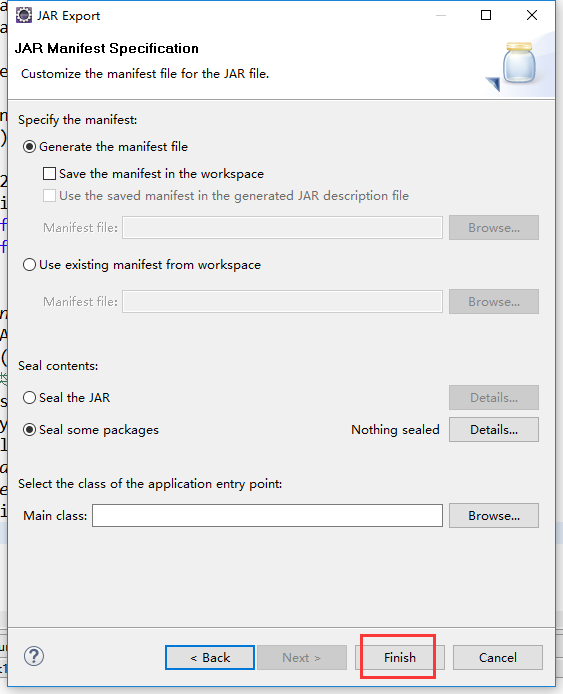
把jar包上传到集群

在集群上运行一下,先检查一下集群的启动进程
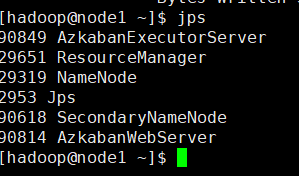
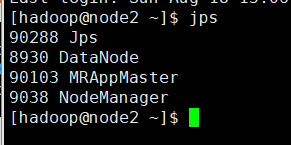

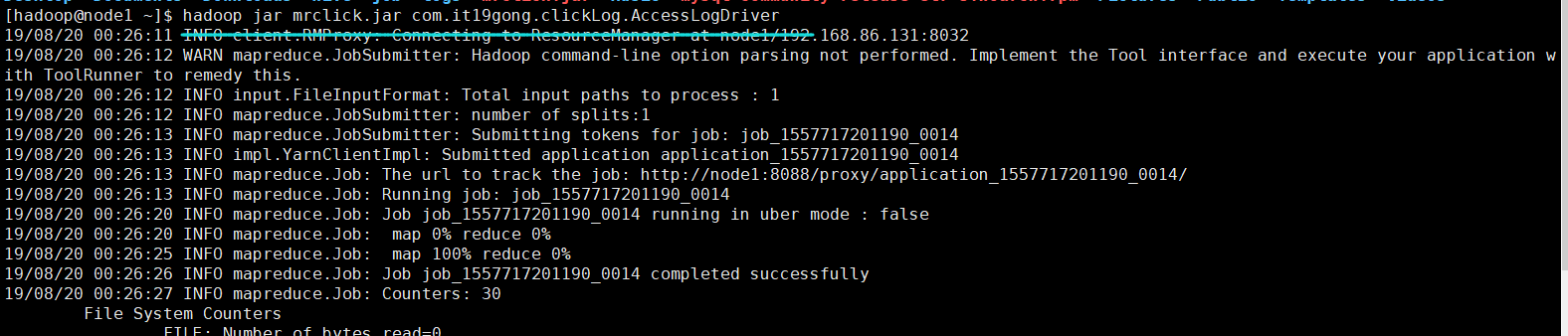
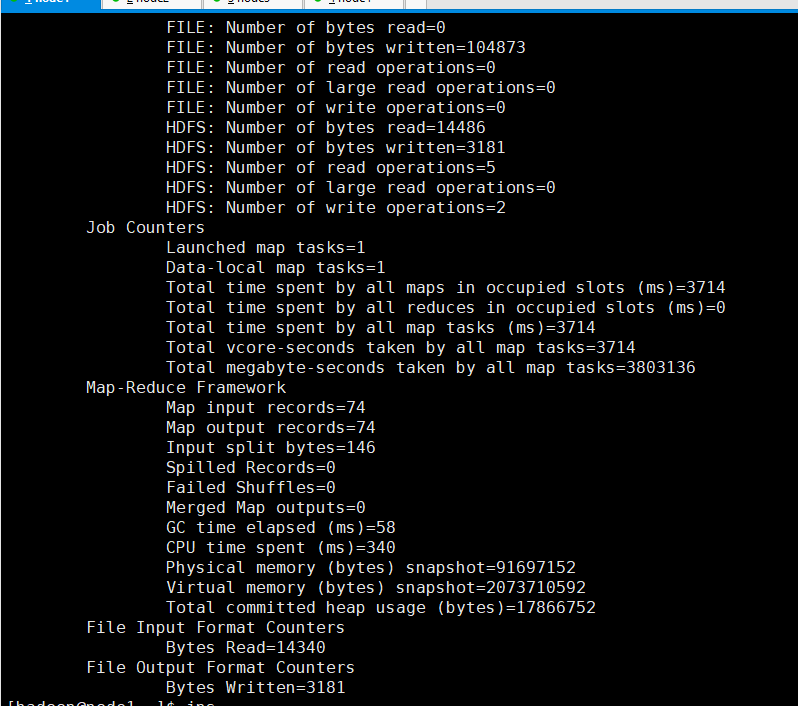
hadoop jar mrclick.jar com.it19gong.clickLog.AccessLogDriver
可以看到输出目录
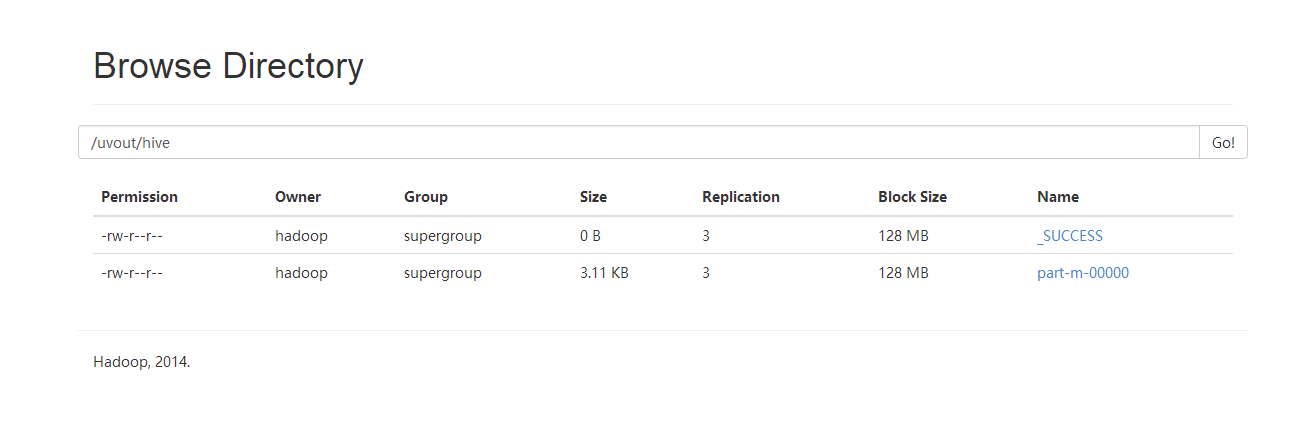
查看清洗后的数据
19.通过MAPREDUCE 把收集数据进行清洗的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- Hadoop生态圈-使用MapReduce处理HBase数据
Hadoop生态圈-使用MapReduce处理HBase数据 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.对HBase表中数据进行单词统计(TableInputFormat) ...
- 使用MapReduce将HDFS数据导入Mysql
使用MapReduce将Mysql数据导入HDFS代码链接 将HDFS数据导入Mysql,代码示例 package com.zhen.mysqlToHDFS; import java.io.DataI ...
- 使用MapReduce将mysql数据导入HDFS
package com.zhen.mysqlToHDFS; import java.io.DataInput; import java.io.DataOutput; import java.io.IO ...
- 使用hadoop mapreduce分析mongodb数据
使用hadoop mapreduce分析mongodb数据 (现在很多互联网爬虫将数据存入mongdb中,所以研究了一下,写此文档) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明 ...
- 【原创】MapReduce备份Elasticsearch数据到HDFS(JAVA)
一.环境:JAVA8,Elasticsearch-5.6.2,Hadoop-2.8.1二.实现功能:mapreduce读elasticsearch数据.输出parquet文件.多输出路径三.主要依赖 ...
- Java 8 (5) Stream 流 - 收集数据
在前面已经使用过collect终端操作了,主要是用来把Stream中的所有元素结合成一个List,在本章中,你会发现collect是一个归约操作,就像reduce一样可以接受各种做法作为参数,将流中的 ...
- java8中用流收集数据
用流收集数据 汇总 long howManyDishes = menu.stream().collect(Collectors.counting()); int totalCalories = men ...
- 《Java 8 in Action》Chapter 6:用流收集数据
1. 收集器简介 collect() 接收一个类型为 Collector 的参数,这个参数决定了如何把流中的元素聚合到其它数据结构中.Collectors 类包含了大量常用收集器的工厂方法,toLis ...
随机推荐
- docker学习---docker基础知识
目录 docker的基础 1.安装docker 2.使用镜像 3.镜像迁移|导入和导出 4.docker Hub介绍 5.搭建私有镜像仓库 5.1.docker开源的镜像分发工具--docker Re ...
- Luogu P5022 旅行 搜索+贪心
好吧...一直咕..现在才过...被卡常卡到爆... 写的垃圾版本,$n^2$无脑删边..可以发现走出来的是棵树...更优秀的及数据加强版先咕着...一定写.qwq #include<cstdi ...
- PHP mysqli_fetch_assoc() 函数
从结果集中取得一行作为关联数组: <?php // 假定数据库用户名:root,密码:123456,数据库:RUNOOB $con=mysqli_connect("localhost& ...
- 之前写的关于chromedp的文章被别人转到CSDN,很受鼓励,再来一篇golang爬虫实例
示例说明:用chromedp操作chrome,导航到baidu,然后输入“美女”,然后再翻2页,在此过程中保存cookie和所有img标签内容,并保存第一页的baidu logo为png 注释已经比较 ...
- 路由器配置——OSPF协议(2)
一.实验目的:使用OSPF协议达到全网互通的效果 二.拓扑图 三.具体步骤配置 (1)R1路由器配置 Router>enableRouter#configure terminalEnter co ...
- 【CUDA 基础】5.6 线程束洗牌指令
title: [CUDA 基础]5.6 线程束洗牌指令 categories: - CUDA - Freshman tags: - 线程束洗牌指令 toc: true date: 2018-06-06 ...
- python并发——进程间同步和通信
一.进程间同步 对于一些临界资源,不能使用并发无限消耗,就需要设置专门的临界标示,比如锁或者信号量等 from multiprocessing import Process, Lock import ...
- flask静态html
flask使用静态html 在flask并不是所有的html都需要做成动态html,并且做成动态html在使用静态资源时要改变它的路径.所以我们有些可以使用静态html. 静态html不需要后台渲染, ...
- 文本处理工具sed
处理文本的工具sed 行编辑器 ,默认自带循环. sed是一种流编辑器,它一次处理一行内容. 功能:主要用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等 sed工具 用法: sed ...
- [Java]字符串数组 与 字符串链表 之间的相互转化
代码: package com.hy; import java.util.Arrays; import java.util.Collections; import java.util.List; pu ...