web scraper——爬取知乎|微博用户数据模板【三】
前言
在这里呢,我就只给模板,不写具体的教程啦,具体的可以参考我之前写的博文。
https://www.cnblogs.com/wangyang0210/p/10338574.html
模板
进入微博选择粉丝较多的博主
复制下面的模板导入站点即可
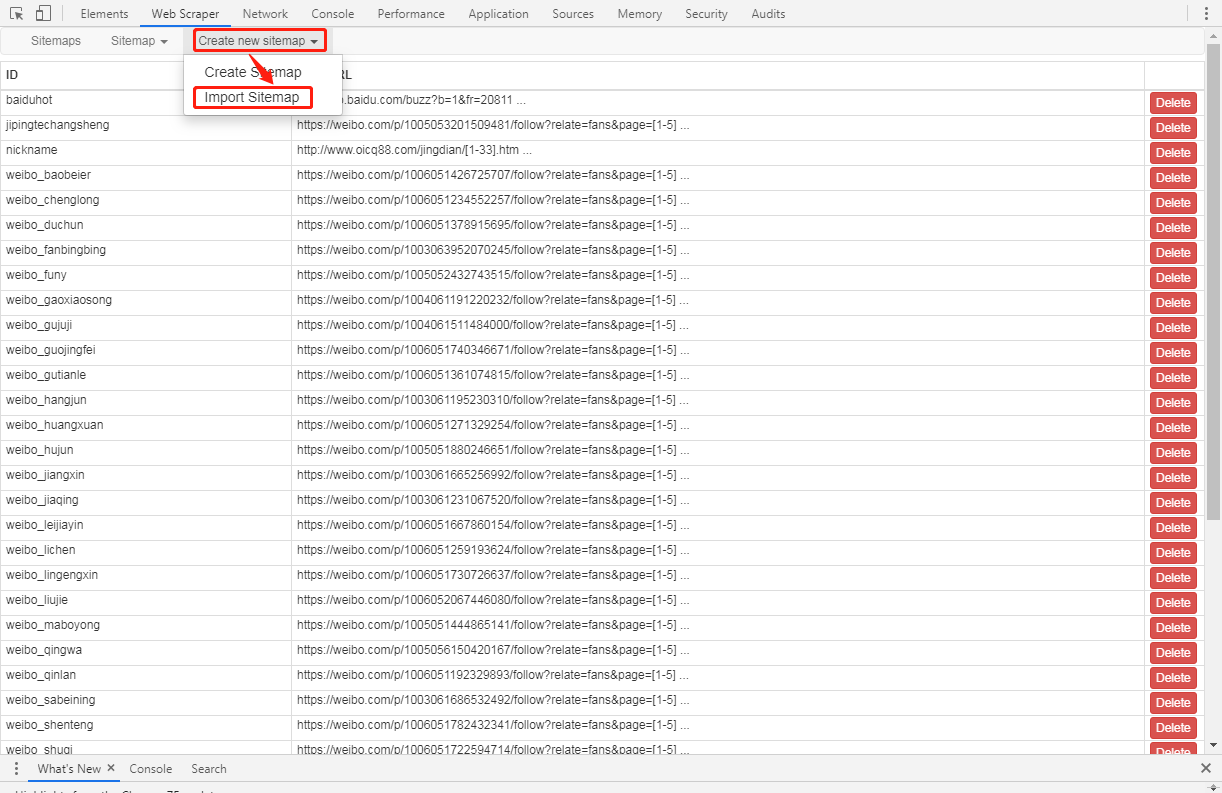
修改地址,编辑好名称,点击
Import Sitemap即可
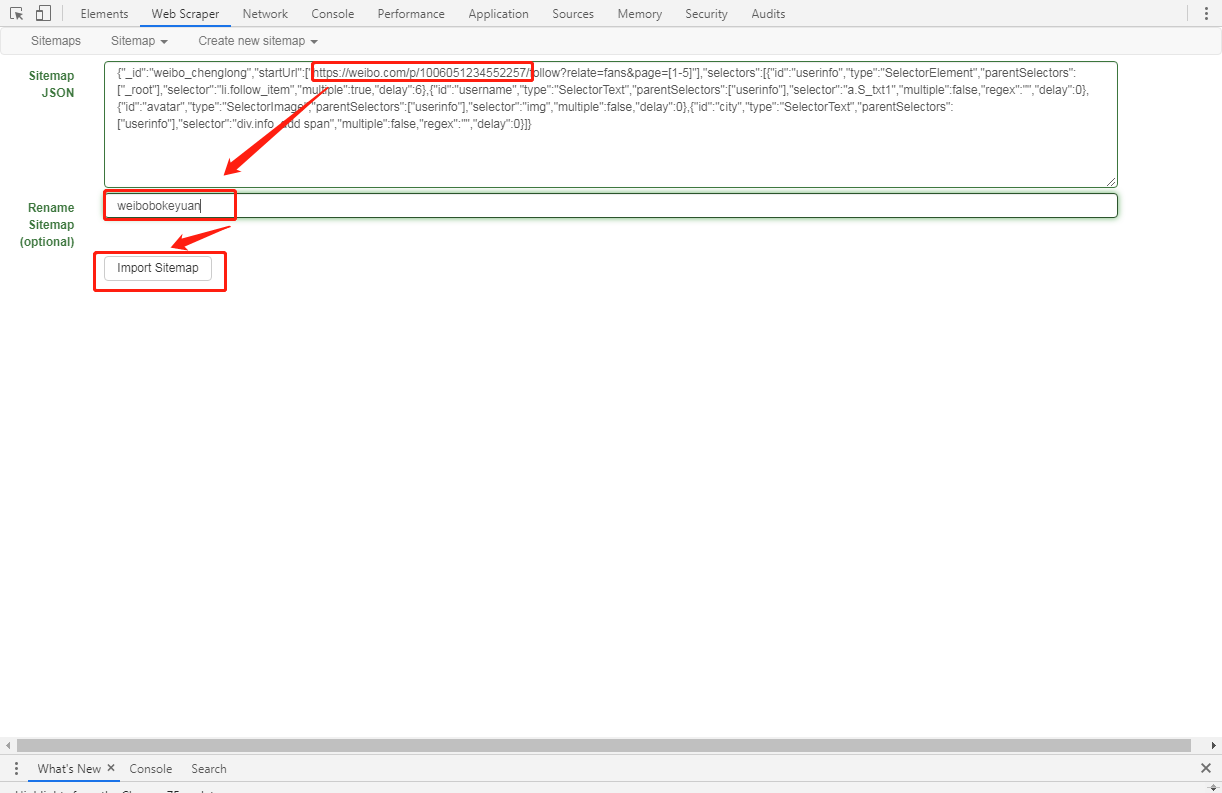
微博
{"_id":"weibo_chenglong","startUrl":["https://weibo.com/p/1006051234552257/follow?relate=fans&page=[1-5]"],"selectors":[{"id":"userinfo","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.follow_item","multiple":true,"delay":6},{"id":"username","type":"SelectorText","parentSelectors":["userinfo"],"selector":"a.S_txt1","multiple":false,"regex":"","delay":0},{"id":"avatar","type":"SelectorImage","parentSelectors":["userinfo"],"selector":"img","multiple":false,"delay":0},{"id":"city","type":"SelectorText","parentSelectors":["userinfo"],"selector":"div.info_add span","multiple":false,"regex":"","delay":0}]}
知乎
{"_id":"zhihuranqiqigongzuoshi","startUrl":["https://www.zhihu.com/people/xie-ling-520/followers?page=[1-45]"],"selectors":[{"id":"list","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.List-item","multiple":true,"delay":0},{"id":"username","type":"SelectorText","parentSelectors":["list"],"selector":"div.UserItem-title","multiple":false,"regex":"","delay":0},{"id":"avatar","type":"SelectorImage","parentSelectors":["list"],"selector":"img","multiple":false,"delay":0}]}
web scraper——爬取知乎|微博用户数据模板【三】的更多相关文章
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- Web Scraper爬取就是这么简单
这应该是最全的一个文档了 https://www.jianshu.com/p/e4c1561a3ea7 所以我就不介绍了,大家直接看就可以了,有问题可以提出来,我会针对问题对文章进行补充~
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- python 爬取知乎图片
先上完整代码 import requests import time import datetime import os import json import uuid from pyquery im ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 16、爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件
爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # 爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # URL https://www.zhihu.co ...
随机推荐
- [转] 这个常识很重要,教你如何区分JEDEC 1600内存与XMP 1600内存
[ 本主题由 围观分子803 于 2016-03-01 20:14:26 设为精华1,原因:主题新颖,支持知识普及! ] 最后由 幻尘 于 2016-03-01 11:57:15 修改 也许一些DIY ...
- Spring中WebMvcConfigurer用到的JDK8特性
闲来无聊,随便翻看项目,发现WebMvcConfigurerAdapter已经过时了,它的作用也不用说了,就是起到适配器的作用,让实现类不用实现所有方法,可以根据实际需要去实现需要的方法. @Depr ...
- 在Grafana使用普罗米修斯
aaarticlea/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0idXRmLTgiPz4KPCEtLSBHZW5lcmF0b3I6IE ...
- 简单的爬虫程序以及使用PYQT进行界面设计(包含源码解析)
由于这个是毕业设计的内容,而且还是跨专业的.爬虫程序肯定是很简单的,就是调用Yahoo的API进行爬取图片.这篇博客主要讲的是基础的界面设计. 放上源码,然后分部解析一下重要的地方.注:flickra ...
- 文件包含lfi
CG-CTF web(文件包含漏洞) 参考链接:https://blog.csdn.net/qq_34072526/article/details/89431431 php://filter 的使用: ...
- C#——零散学习
C#——零散学习0 //控制台输入字符串,转化为int,double,float等数值类型: //Convert.ToXXX32();函数. Convert.ToInt32(); //把字符串转换为i ...
- left join 左边有数据,右边无数据
参考了链接: https://blog.csdn.net/chenjianandiyi/article/details/52402011 主要是and和where的区别: 原Sql: Con ...
- Linux Shell/Bash wildcard通配符、元字符、转义符使用
说到shell通配符(wildcard),大家在使用时候会经常用到.下面是一个实例: 1 1 2 3 4 [chengmo@localhost ~/shell]$ ls a.txt b.txt ...
- Mars Android 接入指南
Mars Android 接入指南 https://github.com/Tencent/mars/wiki/Mars-Android-%E6%8E%A5%E5%85%A5%E6%8C%87%E5%8 ...
- K-匿名算法研究
12月的最后几天,研究了下k匿名算法,在这里总结下. 提出背景 Internet 技术.大容量存储技术的迅猛发 展以及数据共享范围的逐步扩大,数据的自动采集 和发布越来越频繁,信息共享较以前来得更为容 ...