【半监督学习】MixMatch、UDA、ReMixMatch、FixMatch
半监督学习(Semi-Supervised Learning,SSL)的 SOTA 一次次被 Google 刷新,从 MixMatch 开始,到同期的 UDA、ReMixMatch,再到 2020 年的 FixMatch。
这四篇深度半监督学习方面的工作,都是从 consistency regularization 和 entropy minimization 两方面入手:
- consistency regularization:一致性,给输入图片或者中间层注入 noise,模型的输出应该尽可能保持不变或者近似。
- entropy minimization:最小化熵,模型在 unlabeled data 上的熵应该尽可能最小化。Pseudo label 也隐含地用到了 entropy minimization。
Consistency Regularization
对于每一个 unlabeled instance,consistency regularization 要求两次随机注入 noise 的输出近似。背后的思想是,如果一个模型是鲁棒的,那么即使输入有扰动,输出也应该近似。
对于 consistency regularization 来说,如何注入 noise 以及如何计算近似,就是每个方法的不同之处。注入 noise 可以通过模型本身的随机性(如 dropout)或者直接加入噪声(如 Gaussian noise),也可以通过 data augmentation;计算一致性的方法,可以使用 L2,也可以使用 KL divergency、cross entropy。
Entropy Minimization
MixMatch、UDA 和 ReMixMatch 通过 temperature sharpening 来间接利用 entropy minimization,而 FixMatch 通过 Pseudo label 来间接利用 entropy minimization。可以认为,只要通过得到 unlabeled data 的人工标签然后按照监督学习的方法(如 cross entropy loss)来训练的,都间接用到了 entropy minimization。因为人工标签都是 one-hot 或者近似 one-hot 的,如果 unlabeled data 的 prediction 近似人工标签,那么此时无标签数据的熵肯定也是较小的。
为什么这里使用人工标签而不是伪标签的称呼?一般而言,在半监督中,伪标签(pseudo label)特指 hard label,即 one-hot 类型的或者通过 argmax 得到的。[4]
Entropy minimization 可以在计算 unlabeled data 部分的 loss 和 consistency regularization 一起实现。
temperature sharpening 和 pseudo label 都得到了 unlabeled data 的人工标签,当前者 temperature=0 时,两者相等。pseudo label 要比 temperature sharpening 要简单,因为少了一个 temperature 超参数。
如果不利用 entropy minimization,那么 temperature sharpening 和 pseudo label 其实都是不需要的,只需要两次随机注入 noise 的 unlabeled instance 输出近似,就可以保证 consistency regularization。
或者说,得到 unlabeled data 的人工标签,可以使得 entropy minimization 和 consistency regularization 通过一项 loss 来完成。
结合 Consistency Regularization 和 Entropy Minimization
一般来说,半监督学习中的 unlabeled data 会使用全部训练数据集,即有标签的样本也会作为无标签样本来使用。
半监督学习中,labeled data 的标签都是给定的,而 unlabeled data 的标签都是不知道的。那么如何获得 unlabeled data 的人工标签(artificial label),MixMatch、UDA、ReMixMatch 和 FixMatch 的做法或多或少都不相同:
- MixMatch:平均 K 次 weak augmentation(如 shifting 和 flipping)的 predictions ,然后经过 temperature sharpening;
- UDA:一次 weak augmentation 的 prediction,然后经过 temperature sharpening;
- ReMixMatch:一次 weak augmentation 的 prediction,然后经过 distribution alignment,最后经过 temperature sharpening;
- FixMatch:一次 weak augmentation 的 prediction,然后 one-hot 得到 hard label。
得到了人工标签,我们就可以按照监督学习的方式来训练,这种思考方式就利用了 entropy minimization。而从 unlabeled data 的 consistency regularization 角度思考,我们需要注入不同的 noise,使得 unlabeled data 的 predictions 和它们的人工标签一致。
MixMatch、UDA、ReMixMatch 和 FixMatch 都利用 data augmentation 改变输入样本来注入 noise,不同的是 data augmentation 的具体方式和强度:
- MixMatch:一次 weak augmentation 得到 prediction,这就和正常的监督训练一样,只是 unlabeled loss 用的是 L2 而已;
- UDA:一次 strong augmentation(RandAugment) 得到 prediction;
- ReMixMatch:多次 strong augmentation(CTAugment)得到 predictions,然后同时参与 unlabeled loss 的计算,即一个 unlabeled instance 一个 step 多次增强后计算多次 loss;
- FixMatch:一次 strong augmentation(RandAugment 或 CTAugment)得到 prediction。
从 UDA 和 ReMixMatch 开始,strong augmentation 引入了半监督训练。UDA 使用了作者之前提出的 RandAugment 的 strong augmentation 方式,而 ReMixMatch 提出了一种 CTAugment。FixMatch 就把 UDA 和 ReMixMatch 中用到的 strong augmentation 都拿来用了一遍。
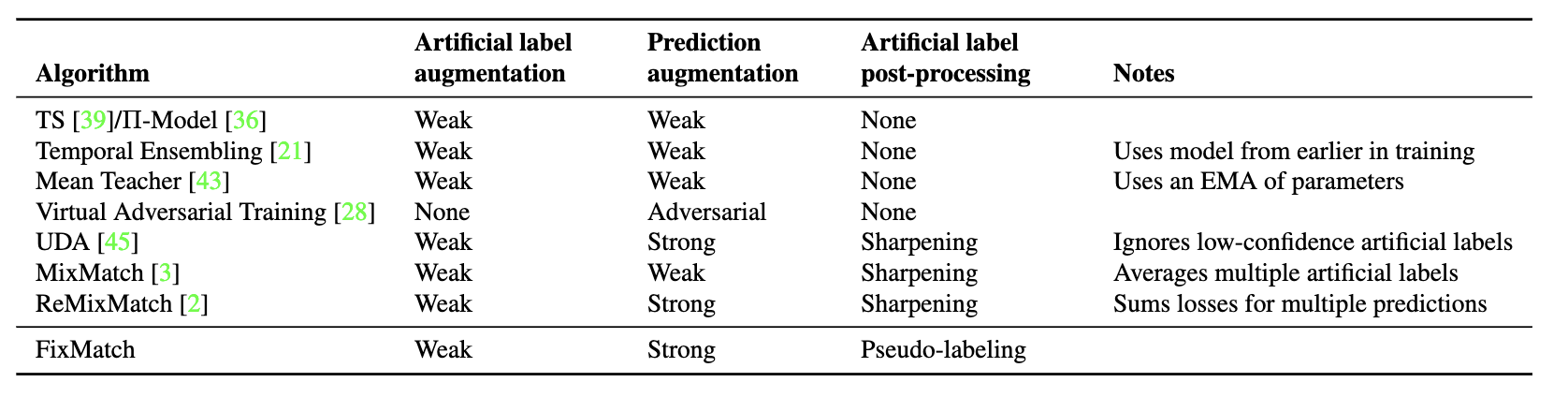
对于 unlabeled data 部分的 loss:
- MixMatch:L2 loss;
- UDA:KL divergency;
- ReMixMatch:cross entropy(包括自监督的 rotation loss 和没有使用 mixup 的 pre-mixup unlabeled loss);
- FixMatch:带阈值的 cross entropy。
FixMatch: Simplifying SSL with Consistency and Confidence
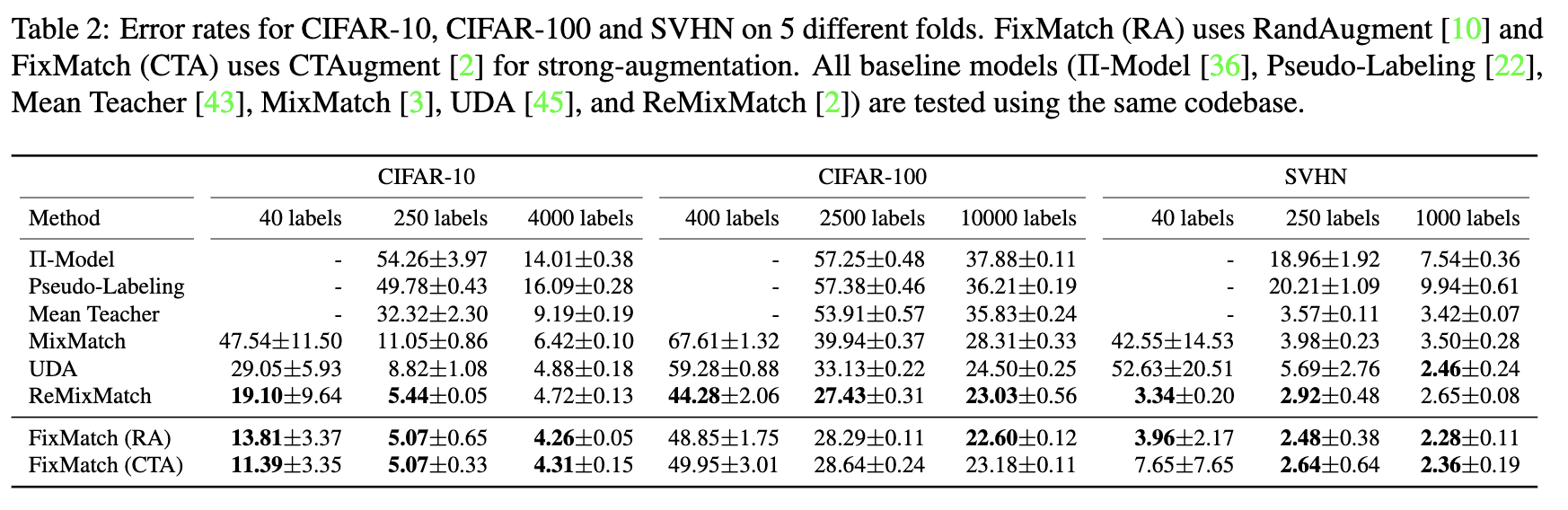
FixMatch 简化了 MixMatch、UDA 和 ReMixMatch,然后获得了更好的效果:
- 首先,temperature sharpening 换成 pseudo label,这是一个简化;
- 其次,FixMatch 通过设定一个阈值,在计算 unlabeled loss 时,对 prediction 的 confidence 超过阈值的 unlabeled instance 才算入 unlabeled loss,这样使得 unlabeled loss 的权重可以固定,这是第二个简化。
References
[1] Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N., Oliver, A., Raffel, C. (2019). MixMatch: A Holistic Approach to Semi-Supervised Learning arXiv https://arxiv.org/abs/1905.02249
[2] Berthelot, D., Carlini, N., Cubuk, E., Kurakin, A., Sohn, K., Zhang, H., Raffel, C. (2019). ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring arXiv https://arxiv.org/abs/1911.09785
[3] Xie, Q., Dai, Z., Hovy, E., Luong, M., Le, Q. (2019). Unsupervised Data Augmentation for Consistency Training arXiv https://arxiv.org/abs/1904.12848
[4] Sohn, K., Berthelot, D., Li, C., Zhang, Z., Carlini, N., Cubuk, E., Kurakin, A., Zhang, H., Raffel, C. (2020). FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence arXiv https://arxiv.org/abs/2001.07685
【半监督学习】MixMatch、UDA、ReMixMatch、FixMatch的更多相关文章
- 利用DP-SSL对少量的标记样本进行有效的半监督学习
作者 | Doreen 01 介绍 深度学习之所以能在图像分类.自然语言处理等方面取得巨大成功的原因在于大量的训练数据得到了高质量的标注. 然而在一些极其复杂的场景(例如:无人驾驶)中会产生海量的数据 ...
- 基于PU-Learning的恶意URL检测——半监督学习的思路来进行正例和无标记样本学习
PU learning问题描述 给定一个正例文档集合P和一个无标注文档集U(混合文档集),在无标注文档集中同时含有正例文档和反例文档.通过使用P和U建立一个分类器能够辨别U或测试集中的正例文档 [即想 ...
- sklearn半监督学习
标签: 半监督学习 作者:炼己者 欢迎大家访问 我的简书 以及 我的博客 本博客所有内容以学习.研究和分享为主,如需转载,请联系本人,标明作者和出处,并且是非商业用途,谢谢! --- 摘要:半监督学习 ...
- python大战机器学习——半监督学习
半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数.它是一类可以自动地利用未标记的数据来提升学习性能的算法 1.生成式半监督学习 优点:方法简单,容易实现.通常在有标记数据极少时, ...
- 吴裕雄 python 机器学习——半监督学习LabelSpreading模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 吴裕雄 python 机器学习——半监督学习标准迭代式标记传播算法LabelPropagation模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 虚拟对抗训练(VAT):一种用于监督学习和半监督学习的正则化方法
正则化 虚拟对抗训练是一种正则化方法,正则化在深度学习中是防止过拟合的一种方法.通常训练样本是有限的,而对于深度学习来说,搭设的深度网络是可以最大限度地拟合训练样本的分布的,从而导致模型与训练样本分布 ...
- 【论文解读】【半监督学习】【Google教你水论文】A Simple Semi-Supervised Learning Framework for Object Detection
题记:最近在做LLL(Life Long Learning),接触到了SSL(Semi-Supervised Learning)正好读到了谷歌今年的论文,也是比较有点开创性的,浅显易懂,对比实验丰富, ...
- AI之强化学习、无监督学习、半监督学习和对抗学习
1.强化学习 @ 目录 1.强化学习 1.1 强化学习原理 1.2 强化学习与监督学习 2.无监督学习 3.半监督学习 4.对抗学习 强化学习(英语:Reinforcement Learning,简称 ...
随机推荐
- Eclipse新建项目介绍
最近在用Eclipse,对于一个新手来说,新建项目时出现五花八门的名字,该选择哪个进行创建呢?今天小编抱着学习的态度,顺便整理分享给大家. 选择File->New->Project... ...
- koa2框架介绍
koa2框架介绍 1.koa2介绍:是当前最流行的node.js的框架,koa2是由express原来的人打造的.他的体积很小,但是扩展性很强. 2.koa2优点和缺点: 2.1.优点: .抛弃了ca ...
- drf-jwt的过滤,筛选,排序,分页组件
目录 自定义drf-jwt配置 案例:实现多方式登陆签发token urls.py models.py serializers.py views.py 案例:自定义认证反爬规则的认证类 urls.py ...
- editplus软件使用技巧
1.文本文件的特点 注:不针对editplus这个软件,对于其他的文本文件处理软件也同样适用. 文本文件就是不包含其它文字格式(比如字体,字号,对齐,行间距等)以及富文本(比如图片,表格等)的一种纯文 ...
- 题解 P1305 【新二叉树】
好像没有人搞\(\color{green}map\)反映,没有人用\(\color{green}map\)反映搞并查集! \(\color{green}map\)第一个好处是作为一个数组,可以开很大! ...
- python使用matplotlib:subplot绘制多个子图 不规则画图
https://www.cnblogs.com/xiaoboge/p/9683056.html
- 一个完整的机器学习项目在Python中的演练(二)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块"拼 ...
- CSS3过渡结束监听事件,清除/修改表单元素的一些默认样式
document.querySelector('div').addEventListener('transitionEnd',function(){ console.log('过度结束') }) 如果 ...
- ArrayList 扩容 和 Vector
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[siz ...
- Spring Boot熟稔于心的20个常识
1.什么是 Spring Boot? Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供 ...