腾讯云EMR大数据实时OLAP分析案例解析

OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值。本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾讯云EMR产品深度合作的案例解读,还原一个不一样的大数据云端解决方案。
一、背景介绍
QQ音乐是腾讯音乐旗下一款领先的音乐流媒体产品,平台打造了“听、看、玩”的立体泛音乐娱乐生态圈,为累计注册数在8亿以上的用户提供多元化音乐生活体验,畅享平台上超过3000万首歌曲的海量曲库。优质服务的背后,是每天万亿级新增音乐内容和行为数据,PB数据量级的数据计算服务。
海量的数据意味着更高标准的数据分析业务,对于离线分析的时效、实时与近实时的即席实时交互分析,提出了更高的要求。如何通过用户行为以及音乐内容标签数据,深入洞察用户需求,来优化泛音乐内容创作分享生态,为亿万用户带来更优质的音乐体验?是对QQ音乐大数据团队的巨大挑战以及机遇。
腾讯云弹性 MapReduce(EMR),结合云技术和社区开源技术,提供安全、低成本、高可靠、可弹性伸缩的云端泛Hadoop服务。EMR助力构建企业的大数据平台架构,适用于HBase在线业务,数据仓库,实时流式计算等大数据场景。
QQ音乐大数据团队基于业务需求,搭建和优化基于ClickHouse的OLAP实时大数据分析平台,并与腾讯云EMR团队深入场景合作,共建大数据云端解决方案。下文将通过案例解读,深入解析QQ音乐大数据团队OLAP系统架构演进之路,不断发掘音乐数据背后的价值。
二、大数据分析的挑战
早些年在传统离线数仓阶段,QQ音乐使用Hive作为大数据分析的主要工具,对TB至PB级的数据进行分析,但存在着以下的可提升点:

1. 时效性低
对于音乐服务来说,实时下钻和分析PV、UV,用户圈层、歌曲的种类、DAU等数据,分析结果的价值取决于时效性。核心日报与统计报表场景下,基于Hive的离线分析仅能满足T+1的时效,对于实时日报和分析的需求越来越强烈。
2. 易用性低
基于Hive离线数据分析平台,对于产品、运营、市场人员具有较高的技术门槛,无法满足自助的实时交互式分析需求;开发在上报和提取分析数据时,无法实时获取和验证结果,查询和分析日志经常需要几个小时。
3. 流程效率低
数据分析需求,需由数据分析团队完成,经过排期、沟通、建模、分析、可视化等流程步骤,所需时间以周计算,落地可能达数周,分析结果不及时,影响和拖慢了决策进度。
为了应对以上问题,提升流程效率,提高数据分析处理的时效性和易用性,数据的即席分析和数据可视化能力支撑需要优化和提升,让问题秒级有响应,分析更深入,数据分析更高效。
三、QQ音乐大数据架构技术演进
QQ音乐大数据团队基于ClickHouse+Superset等基础组件,结合腾讯云EMR产品的云端能力,搭建起高可用、低延迟的实时OLAP分析计算可视化平台。
集群日均新增万亿数据,规模达到上万核CPU,PB级数据量。整体实现秒级的实时数据分析、提取、下钻、监控数据基础服务,大大提高了大数据分析与处理的工作效率。
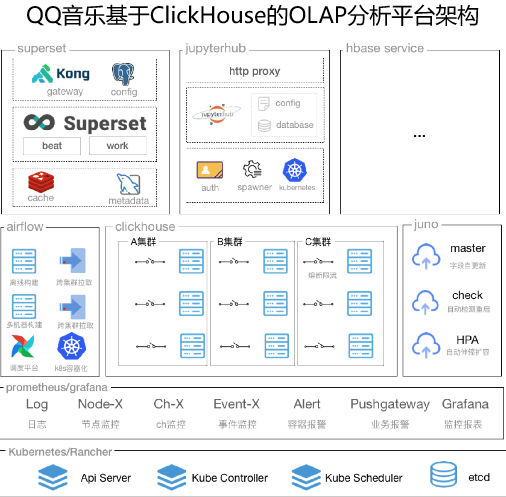
通过OLAP分析平台,极大降低了探索数据的门槛,做到全民BI,全民数据服务,实现了实时PV、UV、营收、用户圈层、热门歌曲等各类指标高效分析,全链路数据秒级分析定位,加强数据上报规范,形成一个良好的正循环。
1. ClickHouse介绍
ClickHouse由俄罗斯第一大搜索引擎Yandex发布,是一个基于列的,面向OLAP的开源轻量级数据库管理系统,能够使用SQL查询实时生成分析数据报告,适合PB数据量级的实时大数据分析。

在场景适用和性能方面,ClickHouse在OLAP的众多组件中有较为突出的优势。
(1)场景适用方面
ClickHouse主要为OLAP应用场景的数据仓库,以库表的方式存储数据,可简单、高效地分析数据,结合Superset以可视化的方式输出分析数据图表。
(2)性能方面
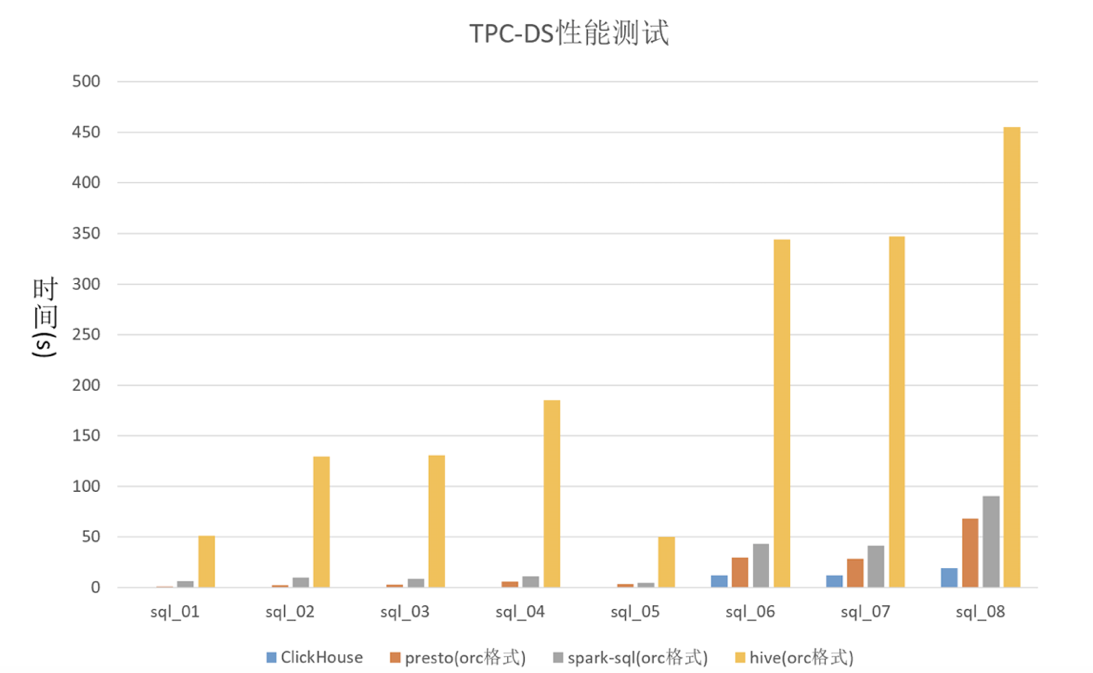
ClickHouse有着卓越的实时分析能力。以性能表现突出的单表为例,使用单表100G,3亿行数据,集群规模8核20G*3,简单的查询在毫秒级完成,复杂查询秒级,查询速度较Presto、SparkSQL提升3-6倍,较Hive提升30-100倍。
对比Presto、Impala、Hawq、Greenplum,ClickHouse以其分布式计算、多核计算、向量化执行与SIMD、代码生成技术以及列式存储等特性,实现了超高速的查询,凸显了更优越的性能。
2. ClickHouse架构系统技术攻克点
面对上万核集群规模、PB级的数据量,经过QQ音乐大数据团队和腾讯云EMR双方技术团队无数次技术架构升级优化,性能优化,逐步形成高可用、高性能、高安全的OLAP计算分析平台。
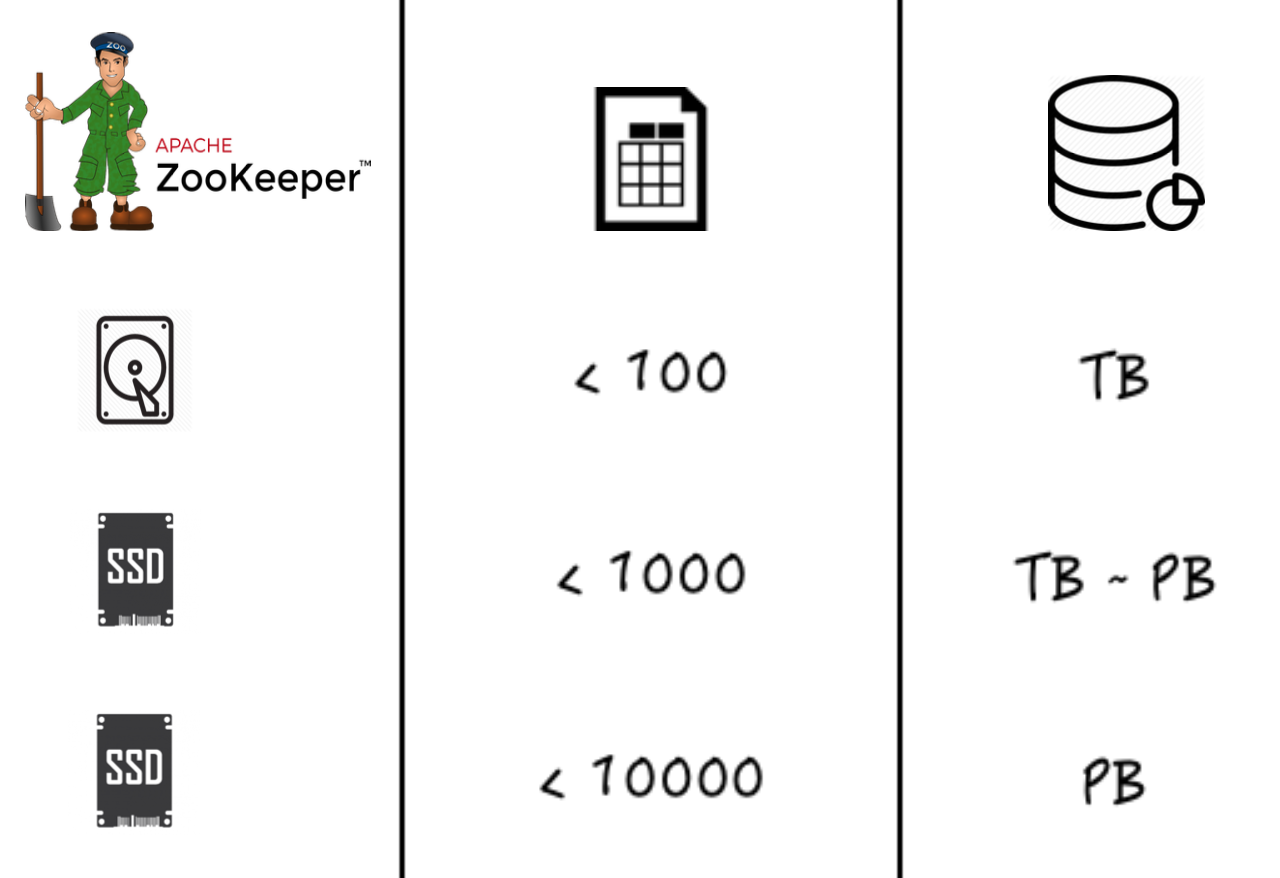
(1)基于SSD盘的ZooKeeper
ClickHouse依赖于ZooKeeper实现分布式系统的协调工作,在ClickHouse并发写入量较大时,ZooKeeper对元数据存储处理不及时,会导致ClickHouse副本间同步出现延迟,降低集群整体性能。
解决方案:采用SSD盘的ZooKeeper大幅提高IO的性能,在表个数小于100,数据量级在TB级别时,也可采用HDD盘,其他情况都建议采用SSD盘。
(2)数据写入一致性
数据在写入ClickHouse失败重试后内容出现重复,导致了不同系统,如Hive离线数仓中分析结果,与ClickHouse集群中运算结果不一致。
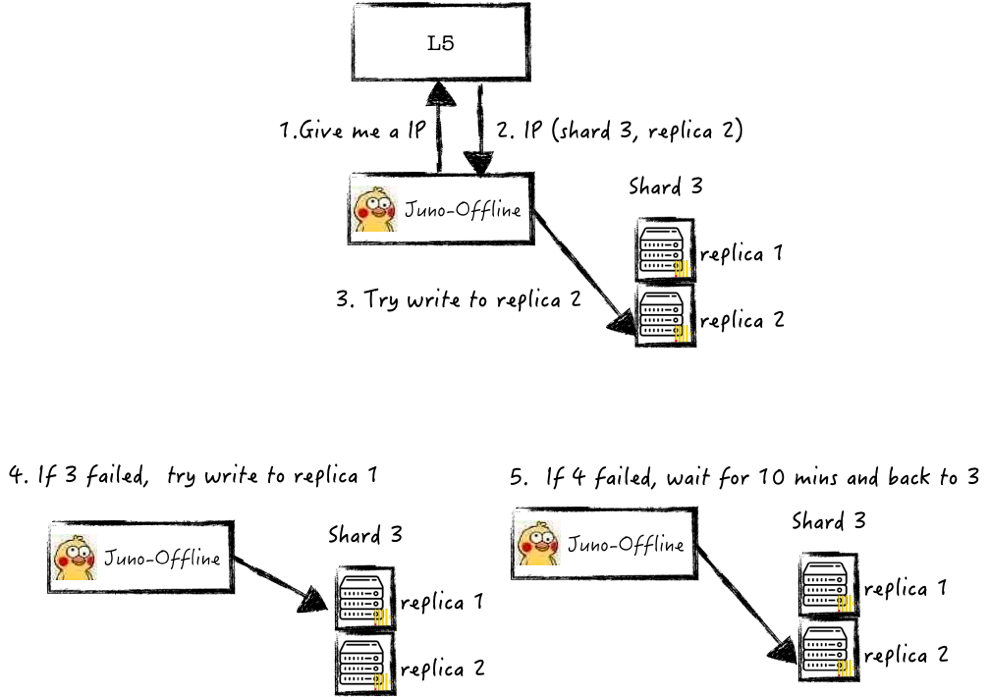
解决方案:基于统一全局的负载均衡调度策略,完成数据失败后仍然可写入同一Shard,实现数据幂等写入,从而保证在ClickHouse中数据一致性。
(3)实时离线数据写入
ClickHouse数据主要来自实时流水上报数据和离线数据中间分析结果数据,如何在架构中完成上万亿基本数据的高效安全写入,是一个巨大的挑战。
解决方案:基于Tube消息队列,完成统一数据的分发消费,基于上述的一致性策略实现数据幂同步,做到实时和离线数据的高效写入。
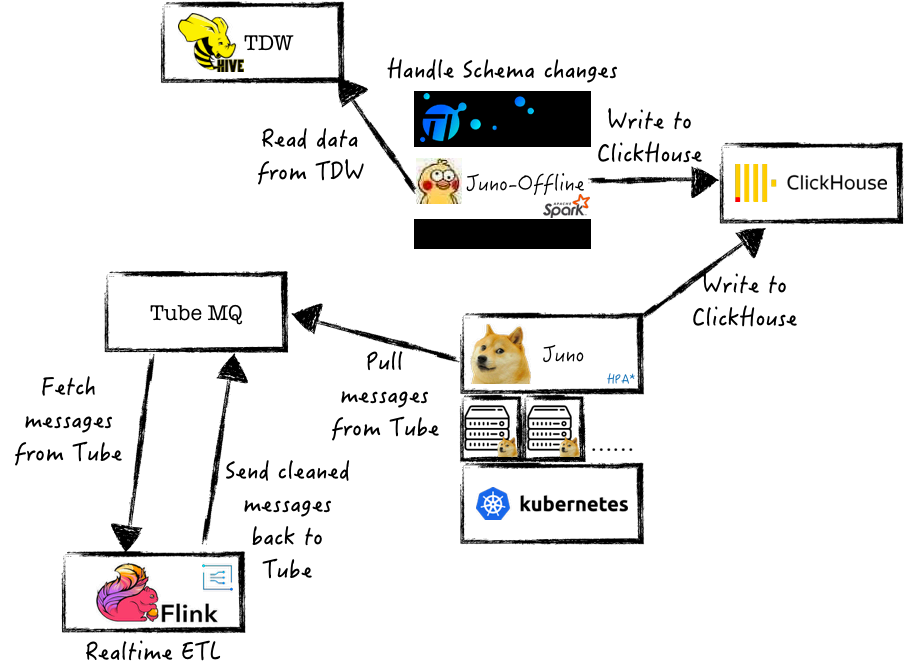
(4)表分区数优化
部分离线数据仓库采用按小时落地分区,如果采用原始的小时分区更新同步,会造成ClickHouse中Select查询打开大量文件及文件描述符,进而导致性能低下。
解决方案:ClickHouse官方也建议,表分区的数量建议不超过10000,上述的数据同步架构完成小时分区转换为天分区,同时程序中完成数据幂等消费。

(5)读/写分离架构
频繁的写动作,会消耗大量CPU/内存/网卡资源,后台合并线程得不到有效资源,降低Merge Parts速度,MergeTree构建不及时,进而影响读取效率,导致集群性能降低。
解决方案:ClickHouse临时节点预先完成数据分区文件构建,动态加载到线上服务集群,缓解ClickHouse在大量并发写场景下的性能问题,实现高效的读/写分离架构,具体步骤和架构如下:
a)利用K8S的弹性构建部署能力,构建临时ClickHouse节点,数据写入该节点完成数据的Merge、排序等构建工作;
b)构建完成数据按MergeTree结构关联至正式业务集群。
当然对一些小数据量的同步写入,可采用10000条以上批量的写入。 
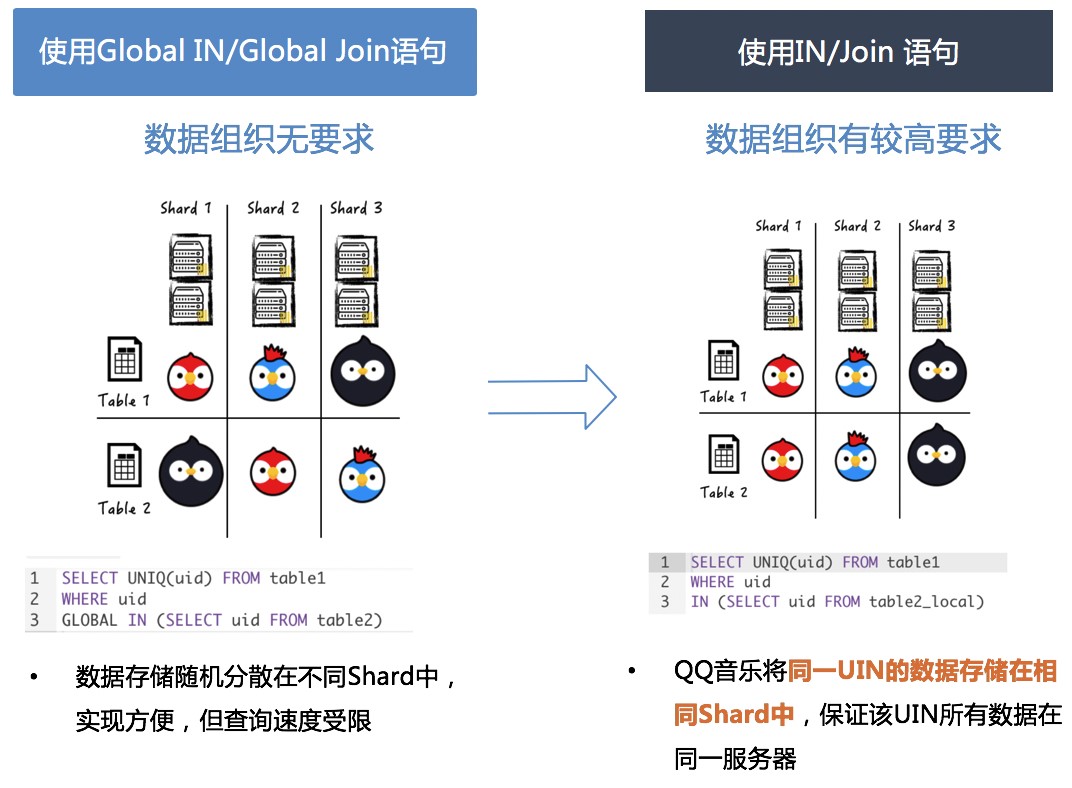
(6)跨表查询本地化
在ClickHouse集群中跨表进行Select查询时,采用Global IN/Global Join语句性能较为低下。分析原因,是在此类操作会生成临时表,并跨设备同步该表,导致查询速度慢。
解决方案:采用一致性hash,将相同主键数据写入同一个数据分片,在本地local表完成跨表联合查询,数据均来自于本地存储,从而提高查询速度。
这种优化方案也有一定的潜在问题,目前ClickHouse尚不提供数据的Reshard能力,当Shard所存储主键数据量持续增加,达到磁盘容量上限需要分拆时,目前只能根据原始数据再次重建CK集群,有较高的成本。
3. 基于Superset的自助数据分析可视化平台
Apache Superset(孵化)是一个现代的、企业级的商业智能Web应用程序,为业务提供处理PB级数据的高性能的OLAP在线数据分析服务,提供丰富的数据可视化集,支持包括ClickHouse、Spark、Hive等多个组件的接口。
QQ音乐大数据团队结合自身业务特点丰富完善功能,结合腾讯云EMR云端弹性能力,深入参与Superset开源共建:
https://github.com/apache/incubator-superset
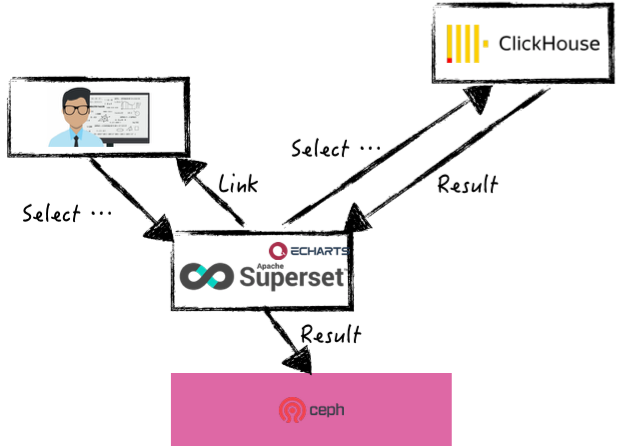
ClickHouse在实时分析领域拥有诸多优势,在OLAP分析场景下,搭配在数据可视化领域表现抢眼的Superset组件,在对QQ音乐业务指标概览以及二维变量分析中,提供丰富的数据可视化集以供数据分析处理。
当前Superset上万个图表中,超60%由产品、研发、运营、研究员、财务等非数据人员创建,做到全民数据分析,数据平民化。
四、QQ音乐与腾讯云EMR共建云端OLAP
在即席分析以及数据可视化等方面,开源社区版本,有着生态支持丰富、开源保证稳定性、软件安全性等诸多优势。但同时,开源版本也存在着技术复杂度高、周期长、组件运维复杂、缺少实际商业化应用的经验积累等缺点和不足。
腾讯云EMR支持开源社区版本OLAP,提供成熟数据能力。开箱即用ClickHouse+Superset组合方案,使用社区的最新稳定版本,同时简化了繁杂的配置和运维操作,保障集群高可用与数据安全。

相比直接使用社区开源组件,产品化的ClickHouse+Superset有着诸多的优势:
快速构建,10分钟创建上百节点的大数据集群,避免复杂的配置。
弹性伸缩,10分钟进行横向扩展。
自动化基础运维设施,百余监控指标覆盖,异常事件秒级触达。
专业云售后团队7*24小时支持,提高技术抗风险能力。
腾讯云EMR商业化产品既保留了开源社区组件的优势,又弥补了存在的不足,是商业化应用的趋势之选。
目前,QQ音乐业务在自建架构的基础上,配合腾讯云EMR产品弹性能力、自动化管理,以及业务商业化的持续支持,对PB级数据进行实时OLAP分析,查询性能优异,广泛应用在实时分析与查询的业务场景,管理更轻松,更专注业务。
QQ音乐也与EMR其它组件,以及大数据矩阵进行更多合作,结合开源与深度二次开发,以混合架构的模式,贴合业务场景,共同打造大数据生态。在推荐场景下, QQ音乐灵活地选用腾讯EMR产品中的HBase组件集群,使用多个组件协作,用于支持标签存储的频繁更新与读取,满足不同大数据业务场景的需求。
结语
云端大数据基础设施产品以其技术开放性、全链路覆盖、灵活性获得了互联网企业数据IT团队的一致认可,越来越多的企业也逐步意识到云厂商雄厚技术保障所带来的隐性价值认同。借助于云端大数据基础设施进行以数据驱动的业务创新、运营创新已成为新一代互联网企业的业界共识和主流趋势。
QQ音乐大数据团队与腾讯云EMR产品深入探索业务合作,从大数据基础设施、全链路数据工具链、领域数据价值应用在内的各个环节,互利共赢,释放多元数据价值。腾讯云EMR将持续打磨ClickHouse+Superset,致力于为更多行业和业务场景提供云端数据能力。
点击:https://cloud.tencent.com/product/emr,了解腾讯云EMR更多信息~
腾讯云EMR大数据实时OLAP分析案例解析的更多相关文章
- Impala简介PB级大数据实时查询分析引擎
1.Impala简介 • Cloudera公司推出,提供对HDFS.Hbase数据的高性能.低延迟的交互式SQL查询功能. • 基于Hive使用内存计算,兼顾数据仓库.具有实时.批处理.多并发等优点 ...
- 使用Oracle Stream Analytics 21步搭建大数据实时流分析平台
概要: Oracle Stream Analytics(OSA)是企业级大数据流实时分析计算平台.它可以通过使用复杂的关联模式,扩充和机器学习算法来自动处理和分析大规模实时信息.流式传输的大数据可以源 ...
- 唯品会海量实时OLAP分析技术升级之路
本文转载自公众号 DBAplus社群 , 作者:谢麟炯 谢麟炯,唯品会大数据平台高级技术架构经理,主要负责大数据自助多维分析平台,离线数据开发平台及分析引擎团队的开发和管理工作,加入唯品会以来还曾负责 ...
- 阿里云DataWorks正式推出Stream Studio:为用户提供大数据实时计算的数据中台
5月15日 阿里云DataWorks正式推出Stream Studio,正式为用户提供大数据的实时计算能力,同时标志着DataWorks成为离线.实时双计算领域的数据中台. 据介绍,Stream St ...
- Storm 实战:构建大数据实时计算
Storm 实战:构建大数据实时计算(阿里巴巴集团技术丛书,大数据丛书.大型互联网公司大数据实时处理干货分享!来自淘宝一线技术团队的丰富实践,快速掌握Storm技术精髓!) 阿里巴巴集团数据平台事业部 ...
- HP PCS 云监控大数据解决方案
——把数据从分散统一集中到数据中心 基于HP分布式并行计算/存储技术构建的云监控系统即是通过“云高清摄像机”及IaaS和PaaS监控系统平台,根据用户所需(SaaS)将多路监控数据流传送给“云端”,除 ...
- Druid:一个用于大数据实时处理的开源分布式系统——大数据实时查询和分析的高容错、高性能开源分布式系统
转自:http://www.36dsj.com/archives/28590 Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分 ...
- 一文让你彻底了解大数据实时计算引擎 Flink
前言 在上一篇文章 你公司到底需不需要引入实时计算引擎? 中我讲解了日常中常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算.随着这些年大数据的飞速发展,也出现了不少计算的框架 ...
- Lambda plus: 云上大数据解决方案
本文会简述大数据分析场景需要解决的技术挑战,讨论目前主流大数据架构模式及其发展.最后我们将介绍如何结合云上存储.计算组件,实现更优的通用大数据架构模式,以及该模式可以涵盖的典型数据处理场景. 大数据处 ...
随机推荐
- SAP登录消息提醒
1功能说明 在相应用户登录时,给其提示相关信息. 2功能实现 2.1函数实现 在函数NAVIGATION_SET_START_TCODE中注册要监听的用户和程序的事务代码,当用户登录时,将自动运行 ...
- Linux内核驱动学习(八)GPIO驱动模拟输出PWM
文章目录 前言 原理图 IO模拟输出PWM 设备树 驱动端 调试信息 实验结果 附录 前言 上一篇的学习中介绍了如何在用户空间直接操作GPIO,并写了一个脚本可以产生PWM.本篇的学习会将写一个驱动操 ...
- Js 事件基础
一:js中常见得事件 (1) : 鼠标事件 click :点击事件 dblclick :双击事件 contextmenu : 右键单击事件 ...
- [NBUT 1224 Happiness Hotel 佩尔方程最小正整数解]连分数法解Pell方程
题意:求方程x2-Dy2=1的最小正整数解 思路:用连分数法解佩尔方程,关键是找出√d的连分数表示的循环节.具体过程参见:http://m.blog.csdn.net/blog/wh2124335/8 ...
- search(13)- elastic4s-histograms:聚合直方图
在聚合的分组统计中我们会面临两种分组元素类型:连续型如时间,自然数等.离散型如地点.产品等.离散型数据本身就代表不同的组别,但连续型数据则需要手工按等长间隔进行切分了.下面是一个按价钱段聚合的例子: ...
- 你不知道的事---SringCloud的feign的继承特性
前言 说起SpringChoud的feign大家用过的都说好.Feign是Netflix开发的声明式.模板化的HTTP客户端.对于我们微服务来说,微服务之间的api调用,使用feign来说是再方便不过 ...
- Redux:Reducers
action只是描述了“发生了什么事情(导致state需要更新)”,但并不直接参与更新state的操作.state的更新由reducer函数执行. 其基本模式是:(state,action)=> ...
- SSH三大框架知识点
Hibernate ****************************************************************************************** ...
- 梳理继承中的has a和is a
面向对象中的继承问题,研究了一天 ,简单梳理下其中最重要的has a和is a 1.has a 一个类中使用了另一个类中的自定义的类型 这里Student中使用了Book 和 computer2.类型 ...
- 201771010128王玉兰《面向对象程序设计(Java)》第十二周学习总结
第一部分:理论知识 1.AWT与Swing简介 (1)Swing用户界面库是非基于对等体的GUI工具箱. Swing具有更丰富并且更方便的用户界面元素集合. Swing对底层平台的依赖很少,因此与 ...