Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架
Scrapy是python下实现爬虫功能的框架,能够将数据解析、数据处理、数据存储合为一体功能的爬虫框架。
2. Scrapy安装
1. 安装依赖包
yum install gcc libffi-devel python-devel openssl-devel -y
yum install libxslt-devel -y
2. 安装scrapy
pip install scrapy
pip install twisted==13.1.0
注意事项:scrapy和twisted存在兼容性问题,如果安装twisted版本过高,运行scrapy startproject project_name的时候会提示报错,安装twisted==13.1.0即可。
3. 基于Scrapy爬取数据并存入到CSV
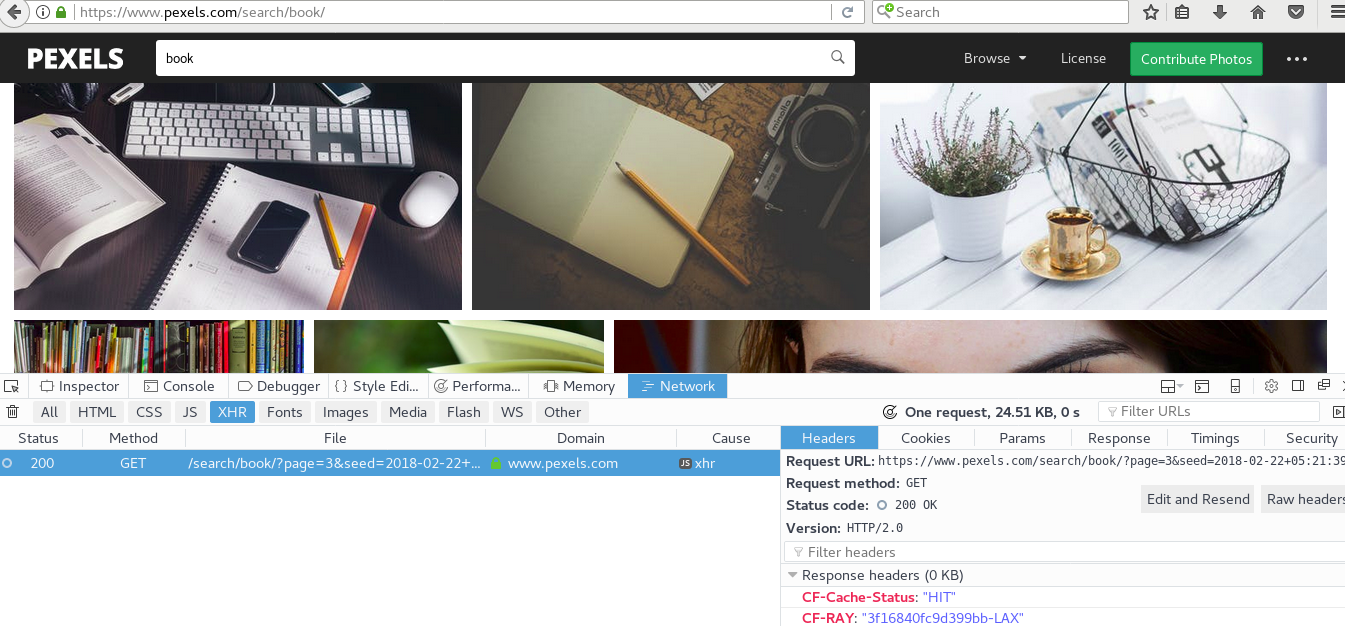
3.1. 爬虫目标,获取简书中热门专题的数据信息,站点为https://www.jianshu.com/recommendations/collections,点击"热门"是我们需要爬取的站点,该站点使用了AJAX异步加载技术,通过F12键——Network——XHR,并翻页获取到页面URL地址为https://www.jianshu.com/recommendations/collections?page=2&order_by=hot,通过修改page=后面的数值即可访问多页的数据,如下图:
3.2. 爬取内容
需要爬取专题的内容包括:专题内容、专题描述、收录文章数、关注人数,Scrapy使用xpath来清洗所需的数据,编写爬虫过程中可以手动通过lxml中的xpath获取数据,确认无误后再将其写入到scrapy代码中,区别点在于,scrapy需要使用extract()函数才能将数据提取出来。
3.3 创建爬虫项目
[root@HappyLau jianshu_hot_topic]# scrapy startproject jianshu_hot_topic #项目目录结构如下:
[root@HappyLau python]# tree jianshu_hot_topic
jianshu_hot_topic
├── jianshu_hot_topic
│ ├── __init__.py
│ ├── __init__.pyc
│ ├── items.py
│ ├── items.pyc
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── pipelines.pyc
│ ├── settings.py
│ ├── settings.pyc
│ └── spiders
│ ├── collection.py
│ ├── collection.pyc
│ ├── __init__.py
│ ├── __init__.pyc
│ ├── jianshu_hot_topic_spider.py #手动创建文件,用于爬虫数据提取
│ └── jianshu_hot_topic_spider.pyc
└── scrapy.cfg 2 directories, 16 files
[root@HappyLau python]#
3.4 代码内容
1. items.py代码内容,定义需要爬取数据字段
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy
from scrapy import Item
from scrapy import Field class JianshuHotTopicItem(scrapy.Item):
'''
@scrapy.item,继承父类scrapy.Item的属性和方法,该类用于定义需要爬取数据的子段
'''
collection_name = Field()
collection_description = Field()
collection_article_count = Field()
collection_attention_count = Field() 2. piders/jianshu_hot_topic_spider.py代码内容,实现数据获取的代码逻辑,通过xpath实现
[root@HappyLau jianshu_hot_topic]# cat spiders/jianshu_hot_topic_spider.py
#_*_ coding:utf8 _*_ import random
from time import sleep
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from scrapy.http import Request
from jianshu_hot_topic.items import JianshuHotTopicItem class jianshu_hot_topic(CrawlSpider):
'''
简书专题数据爬取,获取url地址中特定的子段信息
'''
name = "jianshu_hot_topic"
start_urls = ["https://www.jianshu.com/recommendations/collections?page=2&order_by=hot"] def parse(self,response):
'''
@params:response,提取response中特定字段信息
'''
item = JianshuHotTopicItem()
selector = Selector(response)
collections = selector.xpath('//div[@class="col-xs-8"]')
for collection in collections:
collection_name = collection.xpath('div/a/h4/text()').extract()[0].strip()
collection_description = collection.xpath('div/a/p/text()').extract()[0].strip()
collection_article_count = collection.xpath('div/div/a/text()').extract()[0].strip().replace('篇文章','')
collection_attention_count = collection.xpath('div/div/text()').extract()[0].strip().replace("人关注",'').replace("· ",'')
item['collection_name'] = collection_name
item['collection_description'] = collection_description
item['collection_article_count'] = collection_article_count
item['collection_attention_count'] = collection_attention_count yield item urls = ['https://www.jianshu.com/recommendations/collections?page={}&order_by=hot'.format(str(i)) for i in range(3,11)]
for url in urls:
sleep(random.randint(2,7))
yield Request(url,callback=self.parse) 3. pipelines文件内容,定义数据存储的方式,此处定义数据存储的逻辑,可以将数据存储载MySQL数据库,MongoDB数据库,文件,CSV,Excel等存储介质中,如下以存储载CSV为例:
[root@HappyLau jianshu_hot_topic]# cat pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import csv class JianshuHotTopicPipeline(object):
def process_item(self, item, spider):
f = file('/root/zhuanti.csv','a+')
writer = csv.writer(f)
writer.writerow((item['collection_name'],item['collection_description'],item['collection_article_count'],item['collection_attention_count']))
return item 4. 修改settings文件,
ITEM_PIPELINES = {
'jianshu_hot_topic.pipelines.JianshuHotTopicPipeline': 300,
}
3.5 运行scrapy爬虫
返回到项目scrapy项目创建所在目录,运行scrapy crawl spider_name即可,如下:
[root@HappyLau jianshu_hot_topic]# pwd
/root/python/jianshu_hot_topic
[root@HappyLau jianshu_hot_topic]# scrapy crawl jianshu_hot_topic
2018-02-24 19:12:23 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: jianshu_hot_topic)
2018-02-24 19:12:23 [scrapy.utils.log] INFO: Versions: lxml 3.2.1.0, libxml2 2.9.1, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 13.1.0, Python 2.7.5 (default, Aug 4 2017, 00:39:18) - [GCC 4.8.5 20150623 (Red Hat 4.8.5-16)], pyOpenSSL 0.13.1 (OpenSSL 1.0.1e-fips 11 Feb 2013), cryptography 1.7.2, Platform Linux-3.10.0-693.el7.x86_64-x86_64-with-centos-7.4.1708-Core
2018-02-24 19:12:23 [scrapy.crawler] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'jianshu_hot_topic.spiders', 'SPIDER_MODULES': ['jianshu_hot_topic.spiders'], 'ROBOTSTXT_OBEY': True, 'USER_AGENT': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0', 'BOT_NAME': 'jianshu_hot_topic'}
查看/root/zhuanti.csv中的数据,即可实现。
4. 遇到的问题总结
1. twisted版本不见容,安装过新的版本导致,安装Twisted (13.1.0)即可
2. 中文数据无法写入,提示'ascii'错误,通过设置python的encoding为utf即可,如下:
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
>>> reload(sys)
<module 'sys' (built-in)>
>>> sys.setdefaultencoding('utf8')
>>> sys.getdefaultencoding()
'utf8'
3. 爬虫无法获取站点数据,由于headers导致,载settings.py文件中添加USER_AGENT变量,如:
USER_AGENT="Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"
Scrapy使用过程中可能会遇到结果执行失败或者结果执行不符合预期,其现实的logs非常详细,通过观察日志内容,并结合代码+网上搜索资料即可解决。
Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)的更多相关文章
- 爬虫必知必会(6)_提升scrapy框架爬取数据的效率之配置篇
如何提升scrapy爬取数据的效率:只需要将如下五个步骤配置在配置文件中即可 增加并发:默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_ ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- python利用scrapy框架爬取起点
先上自己做完之后回顾细节和思路的东西,之后代码一起上. 1.Mongodb 建立一个叫QiDian的库,然后建立了一个叫Novelclass(小说类别表)Novelclass(可以把一级类别二级类别都 ...
- 提升Scrapy框架爬取数据效率的五种方式
1.增加并发线程开启数量 settings配置文件中,修改CONCURRENT_REQUESTS = 100,默认为32,可适当增加: 2.降低日志级别 运行scrapy时会产生大量日志占用CPU,为 ...
- 爬虫第六篇:scrapy框架爬取某书网整站爬虫爬取
新建项目 # 新建项目$ scrapy startproject jianshu# 进入到文件夹 $ cd jainshu# 新建spider文件 $ scrapy genspider -t craw ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
随机推荐
- es6变量声明和解构赋值
/*声明: * 本文内容多为学习借鉴性内容,大部分非原创 * 特别感谢阮一峰的 ECMAScript6 入门,推荐大家学习 */ 一.es5变量声明的不足 1.变量提升和函数声明提升 es5的代码加载 ...
- Asp.Net Core 基于QuartzNet任务管理系统
之前一直想搞个后台任务管理系统,零零散散的搞到现在,也算完成了. 这里发布出来,请园里的dalao批评指导! 废话不多说,进入正题. github地址:https://github.com/YANGK ...
- 从零开始学习前端JAVASCRIPT — 11、Ajax-前后端异步交互以及Promise-异步编程的改进
(注:本章讲解涉及部分后端知识,将以php提供数据的方式进行相应的demo实现) 1:ajax的概念 全称:Asynchronous Javascript And Xml AJAX不是一种新的编程语言 ...
- Egret学习笔记 (Egret打飞机-2.开始游戏)
打开 Egret Wing,新建一个Egret游戏项目,然后删掉默认生成的createGameScene方法里面的东西 然后新建一个BeginScene.ts的文件,作为我们的游戏的第一个场景 cla ...
- Vscode 插件
HTML Snippets Markdown All in One Markdown PDF Markdown Priview Enhanced Markdown TOC Open HTML in D ...
- POJ - 1426 暴力枚举+同余模定理 [kuangbin带你飞]专题一
完全想不到啊,同余模定理没学过啊,想起上学期期末考试我问好多同学'≡'这个符号什么意思,都说不知道,你们不是上了离散可的吗?不过看了别人的解法我现在会了,同余模定理介绍及运用点这里点击打开链接 简单说 ...
- float 与 display:inline-block
float: 1.会导致高度塌陷 <style type="text/css"> li{ float:left; height:200px; width:200px; ...
- js处理时间戳显示的问题
function getDate(tm){ ); var year = date.getFullYear(); var month = date.getMonth()+1; var day = dat ...
- 网络基础tcp/ip协议三
数据链路层:(位于网络层与物理层之间) 数据链路层的功能: 数据链路的建立,维护. 帧包装,帧传输,帧同步. 帧的差错恢复. 流量的控制. 以太网:(工作在数据链路层) CSMA/CD(带冲突检测的载 ...
- Unable to find the ncurses libraries的解决办法
我们在更新CentOS或者Ubuntu的内核时,执行make menuconfig可能看如这样的错误: *** Unable to find the ncurses libraries or the* ...