日志收集之--将Kafka数据导入elasticsearch
最近需要搭建一套日志监控平台,结合系统本身的特性总结一句话也就是:需要将Kafka中的数据导入到elasticsearch中。那么如何将Kafka中的数据导入到elasticsearch中去呢,总结起来大概有如下几种方式:
- Kafka->logstash->elasticsearch->kibana(简单,只需启动一个代理程序)
- Kafka->kafka-connect-elasticsearch->elasticsearch->kibana(与confluent绑定紧,有些复杂)
- Kafka->elasticsearch-river-kafka-1.2.1-plugin->elasticsearch->kibana(代码很久没更新,后续支持比较差)
elasticsearch-river-kafka-1.2.1-plugin插件的安装及配置可以参考:http://hqiang.me/2015/08/将kafka的数据导入至elasticsearch/
根据以上情况,项目决定采用方案一将Kafka中的数据存入到elasticsearch中去。
一、拓扑图
项目拓扑图如下所示:
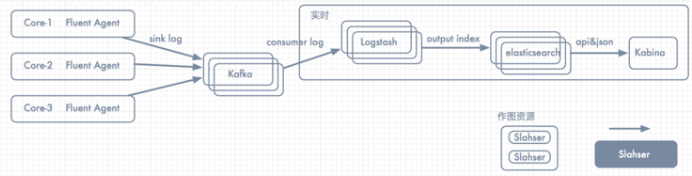
此时消息的整体流向为:日志/消息整体流向Flume => kafka => logstash => elasticsearch => kibana
A.Flume日志收集
agent.sources = r1
agent.channels = c1
agent.sinks = s1 agent.sources.r1.type = exec
agent.sources.r1.command = tail -F -n 0 /data01/monitorRequst.log
agent.sources.r1.restart = true //解决tail -F进程被杀死问题 agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100 agent.sinks.s1.type = avro
agent.sinks.s1.port = 50001
agent.sinks.s1.hostname = IP
agent.sources.r1.channels = c1
agent.sinks.s1.channel = c1
Flume日志收集过程中踩过的坑可以参考:http://www.digitalsdp.com/Experiencebbs/maintenance/506.jhtml
B.Kafka Sink
agent.sources = r1
agent.channels = c2
agent.sinks = s2 agent.sources.r1.type = avro
agent.sources.r1.bind = IP
agent.sources.r1.port = 50001 agent.channels.c2.type = memory
agent.channels.c2.capacity = 1000
agent.channels.c2.transactionCapacity = 100 agent.sinks.s2.type = org.apace.flume.sink.kafka.KafkaSink
agent.sinks.s2.topic = XXX
agent.sinks.s2.brokerList = IP:9091,IP:9092
agent.sinks.s2.batchSize = 20 agent.sources.r1.channels = c2
agent.sinks.s2.channel = c2
二、环境搭建
关于Kafka及Flume的搭建在这里不再详细论述,如有需要请参见本文其它说明。在这里重点说明logstash的安装及配置。
A.下载logstash的安装包;
B.新建kafka-logstash-es.conf置于logstash/conf目录下;
C.配置kafka-logstash-es.conf如下:
logstash的配置语法如下:
input {
...#读取数据,logstash已提供非常多的插件,可以从file、redis、syslog等读取数据
}
filter{
...#想要从不规则的日志中提取关注的数据,就需要在这里处理。常用的有grok、mutate等
}
output{
...#输出数据,将上面处理后的数据输出到file、elasticsearch等
}
示例:
input {
kafka {
zk_connect => "c1:2181,c2:2181,c3:2181"
group_id => "elasticconsumer" ---随意取
topic_id => "xxxlog" ---与flume中的Channel保持一致
reset_beginning => false
consumer_threads => 5
decorate_events => true
codec => "json"
}
}
output {
elasticsearch {
hosts => ["c4:9200","c5:9200"]
index => "traceid"--与Kafka中json字段无任何关联关系,注意:index必须小写
index => "log-%{+YYYY-MM-dd}"
workers => 5
codec => "json"
}
}
运行logstash命令为:nohup bin/logstash -f /XXX/logstash/conf/kafka-logstash-es.conf &
三、调测过程中遇到的一些坑
A.在集成ELK过程中总以为head插件是必须的,其实head插件为非必需品。elasticsearch仅提供了一个数据存储的煤介,head为了让大家更方便的去查看数据;
B.采用以上方案进行布署时,当系统正常运行时,可以在elasticsearch服务器上http://IP:9200/*中搜索index是否创建成功
参考:https://www.slahser.com/2016/04/21/日志监控平台搭建-关于Flume-Kafka-ELK/
http://www.jayveehe.com/2017/02/01/elk-stack/
http://wdxtub.com/2016/11/19/babel-log-analysis-platform-1/
日志收集之--将Kafka数据导入elasticsearch的更多相关文章
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- 通过logstash-input-mongodb插件将mongodb数据导入ElasticSearch
目的很简单,就是将mongodb数据导入es建立相应索引.数据是从特定的网站扒下来,然后进行二次处理,也就是数据去重.清洗,接着再保存到mongodb里,那么如何将数据搞到ElasticSearch中 ...
- Hive数据导入Elasticsearch
Elasticsearch Jar包准备 所有节点导入elasticsearch-hadoop-5.5.1.jar /opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12 ...
- 日志收集ELK+kafka相关博客
SpringBoot+kafka+ELK分布式日志收集 使用 logstash + kafka + elasticsearch 实现日志监控 Kibana 安装 与 汉化 windows系统安装运行f ...
- ABP 使用ElasticSearch、Kibana、Docker 进行日志收集
ABP 使用ElasticSearch.Kibana.Docker 进行日志收集 后续会根据公司使用的技术,进行技术整理分享,都是干货哦别忘了关注我!!! 最近领导想要我把项目日志进行一个统一收集,因 ...
- 【大数据实战】将普通文本文件导入ElasticSearch
以<刑法>文本.txt为例. 一.格式化数据 1,首先,ElasticSearch只能接收格式化的数据,所以,我们需要将文本文件转换为格式化的数据---json. 下图为未处理的文本文件. ...
- 安装配置elasticsearch、安装elasticsearch-analysis-ik插件、mysql导入数据到elasticsearch、安装yii2-elasticsearch及使用
一.安装elasticsearch 获取elasticsearch的rpm:wget https://download.elastic.co/elasticsearch/release/org/ela ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
- SpringBoot使用Graylog日志收集
本文介绍SpringBoot如何使用Graylog日志收集. 1.Graylog介绍 Graylog是一个生产级别的日志收集系统,集成Mongo和Elasticsearch进行日志收集.其中Mongo ...
随机推荐
- GIF添加3D加速
由于浏览器内核对Gif格式的图片会产生卡的情况,所以我们需要告诉浏览器,开启一下加速,方法很简单,就是利用css3的特性,强制告诉浏览器,这是个元素,需要3D转换,请务必开启加速效果 方法1 给gif ...
- oracle 嵌套查询
select dat.id, dat.voucher_id, dat.type, dat.state, dat.start_point, dat.start_floor, dat.end_point, ...
- [Git] Move some commits to a separate branch that I have accidentally committed to master
Gosh no, I just added all of these commits to master. They were thought to be peer reviewed first in ...
- 鼠标上下滚动支持combobox选中
首先需要jquery插件来支持: 1.代码SVN检出https://github.com/jquery/jquery-mousewheel 2.点击这里下载jquery.mousewheel.zip ...
- js undefined易错分析
undefined 以下是错误写法: data = undefined; alert(undefined==false);//这样判断会输出false; if(data!=undefined || d ...
- 谷哥的小弟学前端(10)——JavaScript基础知识(1)
探索Android软键盘的疑难杂症 深入探讨Android异步精髓Handler 具体解释Android主流框架不可或缺的基石 站在源代码的肩膀上全解Scroller工作机制 Android多分辨率适 ...
- 使用visual studio code调试php代码
这回使用visual studio code折腾php代码的调试,又是一顿折腾,无论如何都进不了断点.好在就要放弃使用visual studio code工具的时候,折腾好了,汗~ 这里把步骤记录下来 ...
- sqlAlchemy学习 001
研究学习主题 sqlAlchemy架构图 测试练习代码编写 连接数据库 看代码 db_config = { 'host': 'xxx.xxx.xxx.xx', 'user': 'root', 'pas ...
- hadoop multipleoutputs
http://grepalex.com/2013/05/20/multipleoutputs-part1/ http://grepalex.com/2013/07/16/multipleoutputs ...
- Spring Boot 之 RESTfull API简单项目的快速搭建(一)
1.创建项目 2.创建 controller IndexController.java package com.roncoo.example.controller; import java.util. ...