语音笔记:CTC
CTC全称,Connectionist temporal classification,可以理解为基于神经网络的时序类分类。语音识别中声学模型的训练属于监督学习,需要知道每一帧对应的label才能进行有效的训练,在训练的数据准备阶段必须要对语音进行强制对齐。对于语音的一帧数据,很难给出一个label,但是几十帧数据就容易判断出对应的发音label。CTC的引入可以放宽了这种逐一对应的要求,只需要一个输入序列和一个输出序列即可以训练。CTC解决这一问题的方法是,在标注符号集中加一个空白符号blank,然后利用RNN进行标注,最后把blank符号和预测出的重复符号消除。比如有可能预测除了一个"--a-bb",就对应序列"ab",这样就让RNN可以对长度小于输入序列的标注序列进行预测了。RNN的训练需要用到前向后向算法(Forward-backward algorithm),大概思路是:对于给定预测序列,比如“ab”,在各个字符间插入空白符号,建立起篱笆网络(Trellis),然后对将所有可能映射到给定预测的序列都穷举出来求和。
CTC有两点好处:不需要对数据对齐和一一标注;CTC直接输出序列预测的概率,不需要外部的后处理。
在端到端的语音识别中有以下问题:
1).输入语音序列和标签(即文字结果)的长度不一致
2).标签和输入序列的位置是不确定的(对齐问题)
即长度问题和对齐问题,多个输入帧对应一个输出或者一个输入对多个输出。
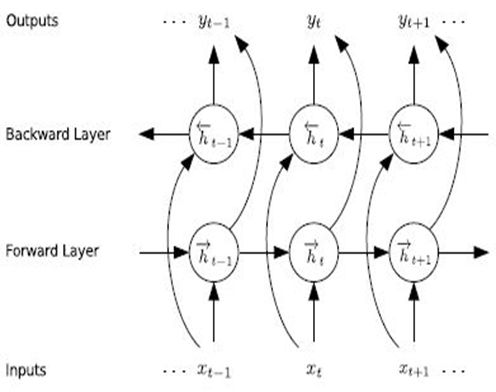
1.结构
系统可以通过双向rnn进行建模。RNN用来训练得到每个时刻不同音素的概率分布。
输入:按时序输入的每一帧的特征。
输出:每一个时刻的输出,是一个softmax,表示K+1个类别的不同概率,K表示音素的个数,1表示blank。(分类问题,是某个音素or空白)
对于给定时序长度为T的输入特征序列和任意一个输出标签序列π={π1,π2,π3,….,πT}。输出为该序列的概率为每个时刻相应标签的概率乘积:

把上式中的pr概率写成y,就变为论文中的原始公式(y表示softmax输出的概率):
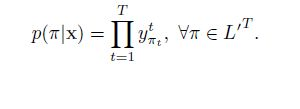
2.损失函数
因为输出序列和最后的训练标签一般不等长,我们用x表示输入序列,y表示对于的标签,a表示我们之前预测的序列:采用一个many-to-one的对应准则β(去除blank和重复),使上述的输出序列与给定的标签序列对应,比如(a,-,b,c,-,-)和(-,-,a,-,b,c)都映射成标签y(a,b,c)。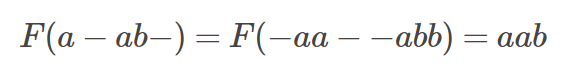
表示β的逆过程,即one-to-many,也就是把(a,b,c)映射成有重复和blank的所有可能,所以最终的标签y为给定输入序列x在LSTM模型下各个序列标签的概率之和:
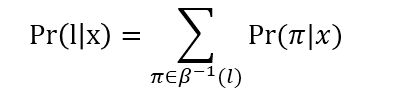
所以给定一个输入序列x和一个标注l*,上式为给定输入x,输出序列为 l 的概率。LSTM的目标函数最大化上述概率值(最小化负对数)。
CTC的损失函数定义如下所示:
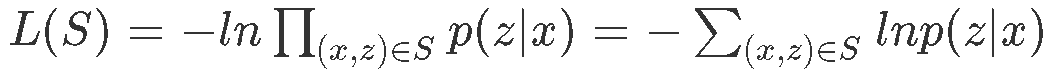
其中 p(z|x)p(z|x) 代表给定输入x,输出序列 zz 的概率,S为训练集。损失函数可以解释为:给定样本后输出正确label的概率的乘积,再取负对数就是损失函数了。取负号之后我们通过最小化损失函数,就可以使输出正确的label的概率达到最大了。
由于上述定义的损失函数是可微的,因此我们可以求出它对每一个权重的导数,然后就可以使用梯度下降、Adam等优化算法来进行求解。
语音笔记:CTC的更多相关文章
- 语音笔记:MFCC
一,传统语音识别体系结构 二,MFCC特征提取 MFCC(Mel-frequency cepstral coefficients):梅尔频率倒谱系数.梅尔频率是基于人耳听觉特性提出来的, 它与Hz频率 ...
- 论文笔记:语音情感识别(三)手工特征+CRNN
一:Emotion Recognition from Human Speech Using Temporal Information and Deep Learning(2018 InterSpeec ...
- 语音识别中的CTC算法的基本原理解释
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文作者:罗冬日 目前主流的语音识别都大致分为特征提取,声学模型,语音模型几个部分.目前结合神经网络的端到端的声学模型训练方法主要CTC和基 ...
- 测试使用wiz来发布blog
晚上尝试了下用wiz写随笔并发布,貌似成功了,虽然操作体验和方便性上不如word,但起码它集成了这个简单的功能可以让我用:如果能让我自动新建blog文章并自动定时更新发布就完美了.2013年7月5日1 ...
- M2阶段事后总结报告
会议照片: 设想和目标 1. 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 开发一个快捷方便的记事本App.从用户体验角度出发,在一般记事本App的基础上进行创新 ...
- 孤荷凌寒自学python第八十六天对selenium模块进行较详细的了解
孤荷凌寒自学python第八十六天对selenium模块进行较详细的了解 (今天由于文中所阐述的原因没有进行屏幕录屏,见谅) 为了能够使用selenium模块进行真正的操作,今天主要大范围搜索资料进行 ...
- 孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1
孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1 (完整学习过程屏幕记录视频地址在文末) 要模拟进行浏览器操作,只用requests是不行的,因此今天了解到有专门的解决方案 ...
- 孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块
孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块 (完整学习过程屏幕记录视频地址在文末) 由于本身tesseract模块针对普通的验证码图片的识别率并不高 ...
- 孤荷凌寒自学python第八十三天初次接触ocr配置tesseract环境
孤荷凌寒自学python第八十三天初次接触ocr配置tesseract环境 (完整学习过程屏幕记录视频地址在文末) 学习Python我肯定不会错过图片文字的识别,当然更重要的是简单的验证码识别了,今天 ...
随机推荐
- windows系统安装python3.6.3和python3.7.0
一.装备好从官网下载的python软件包(3.6.3和3.7.0) 二.先安装python3.6.3 1.运行python3.6.3文件 2.选择默认 3.下一步,等待安装 4.检查是否安装成功 ,安 ...
- MySQL 1130 - Host 127.0.0.1 is not allowed to connect to this MySQL server
在开发中为了让开发更方便,在本地配置环境,希望可以直接访问服务器上的MySQL数据库,更方便的管理数据库, 需要在本地远程连接linux服务器的本地数据库,直接用数据库管理工具连接出现如下报错1130 ...
- 在excel中将缺失数据全部用0补齐
先ctrl+H ,出现如下对话框 点击“定位”,选择“空值” 在表格中空的位置上编辑栏输入0,CTRL+ENTER,即可将缺失数据全部用0补齐.
- JavaScript中遍历数组和对象的方法
js数组遍历和对象遍历 针对js各种遍历作一个总结分析,从类型用处,分析数组和对象各种遍历使用场景,优缺点等 JS数组遍历: 1,普通for循环,经常用的数组遍历 var arr = [1,2,0,3 ...
- 17秋 软件工程 团队第五次作业 Alpha Scrum12
各个成员今日完成的任务 Alpha版本完成. 项目的发布说明 本版本的新功能 1.部门人员管理,包括纳新申请与审核: 2.部门活动发布与查看: 3.部门活动相册: 4.子部门信息录入. 软件对运行环境 ...
- Go学习笔记01-环境搭建
最近想学学Go语言,就在笔记本上配置了Go的环境. 本人的运行环境为:Windows 10 1709. 1.下载安装包 到官网下载安装包,官网网址为:Go安装包下载地址 现在Go的最新版本为1.9.2 ...
- 周杰伦的2000w个故事
http://m.v.qq.com/play/play.html?coverid=g0p1mhz5c52ogla&vid=g0025u7k36z&ptag=2_5.8.6.13321_ ...
- PAT A1147 Heaps (30 分)——完全二叉树,层序遍历,后序遍历
In computer science, a heap is a specialized tree-based data structure that satisfies the heap prope ...
- https安全协议原理
那么什么是HTTPS? HTTPS(Hypertext Transfer Protocol Secure)是一种通过计算机网络进行安全通信的传输协议.HTTPS经由HTTP进行通信,但利用TLS来加密 ...
- Android Studio复制项目作为一个新的工程
Android Studio复制项目作为一个新的工程 等待..... 好了 可能会安装失败 Failed to finalize session : INSTALL_FAILED_INVALID_AP ...