ELK学习之Logstash篇
Logstash在ELK这一整套解决方案中作为数据采集终端,支持对接Kafka、数据库(MySQL、Oracle)、文件等等。
而在Logstash内部的数据流转,主要经过三个环节:input -> filter -> output,顾名思义就是输入、过滤(处理)以及输出。接下来通过一个实际的操作案例来感受一下Logstash内部的数据流转过程。
首先在官网下载Logstash的运行包,https://www.elastic.co/fr/downloads/logstash,由于我本地是Windows环境,因此选择下载Windows对应的包:

将下载完毕的压缩包logstash-7.14.1-windows-x86_64.zip进行解压之后进入bin目录并创建logstash.conf文件用于对input、filter以及output进行相应的配置:

接下来在配置文件中进行响应的配置,直接给出完整的例子并在后文进行详解:
input {
file {
path => "D:/logstash-7.14.1/test-log/test.log"
start_position => beginning
}
}
filter {
grok {
match => { "message" => "(?<Time>[0-9]{6}\.[0-9]{3})\[(?<LogLevel>\d)\]\[(?<ThreadNo>[0-9]*)\].*(?<Tag>FindResponseByPage)\[fund\_account\=(?<FundAccount>[0-9]*)" }
}
if [Tag] != "FindResponseByPage" {
drop {}
}
}
output {
file {
path => "D:/logstash-7.14.1/test-log/logstash.log"
codec => line {
format => "Time: %{Time}, LogLevel: %{LogLevel}, ThreadNo: %{ThreadNo}, Tag: %{Tag}, FundAccount: %{FundAccount}"
}
}
}
input 中添加 file 项表示通过文件进行输入,path 为文件的绝对路径(如果配置非绝对路径,Logstash会给出报错提示),start_position => beginning 表示每次从文件头开始读取。
filter中则进行对输入数据的相关处理进行配置(filter可以不配置,效果是原样输出)。
grok是Logstash的核心插件之一,可以根据配置的表达式进行数据筛选并存入指定的变量名中。grok提供了一系列标准的匹配模板,不过由于grok底层也是基于正则表达式,因此也可以直接输入正则表达式进行匹配。
这里搬运一个官网上的例子:
55.3.244.1 GET /index.html 15824 0.043
针对上述格式的数据,可以通过grok提供的标准表达式模板进行匹配:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
示例中,IP为预定义的模板,client为准备存入的变量名。很容易看出,grok的标准语法如下:
%{SYNTAX:SEMANTIC}
SYNTAX:匹配值的类型,例如15824可以用NUMBER类型所匹配,55.3.244.1可以使用IP类型匹配。
SEMANTIC:存储该值的一个变量名,例如GET可能代表的是REST请求中指定的方法,那么用method来进行保存。
当然,像上方的配置文件示例中一样,通过原生的正则表达式来进行匹配也可以,不使用预定义模板的格式如下:
(?<field_name>the pattern here)
其中field_name表示保存匹配到内容的变量名,后面部分则是表达式,例如:
093124.597[0][30100]
对应的匹配表达式为:
?<Time>[0-9]{6}\.[0-9]{3})\[(?<LogLevel>\d)\]\[(?<ThreadNo>[0-9]*)\]
根据匹配到的值可以通过drop进行一个筛选,例如只需要LogLevel值为error的数据,可以在filter中添加如下配置:
if [LogLevel] != "error" {
drop {}
}
output这里同样配置了file,也就是将输入的数据经过处理后输出到另一个指定文件中,path为输出文件的绝对路径,format则指定了输出的格式。
接下来启动Logstash来观察一下效果,在bin目录打开命令行并输入启动命令:
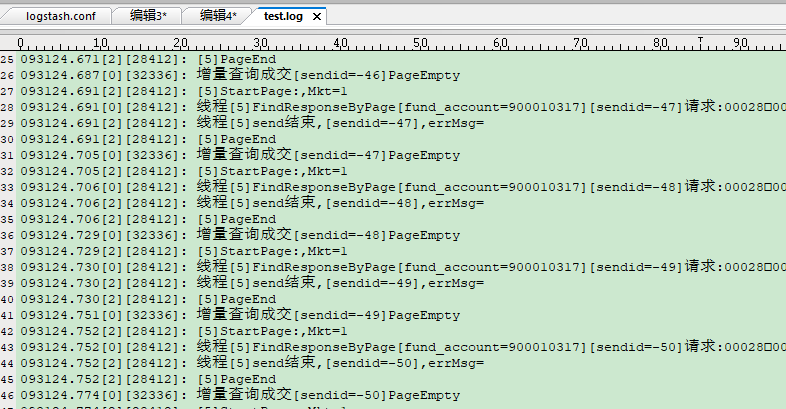
再看一下输入文件和输出文件中的效果,首先是输入文件test.log:
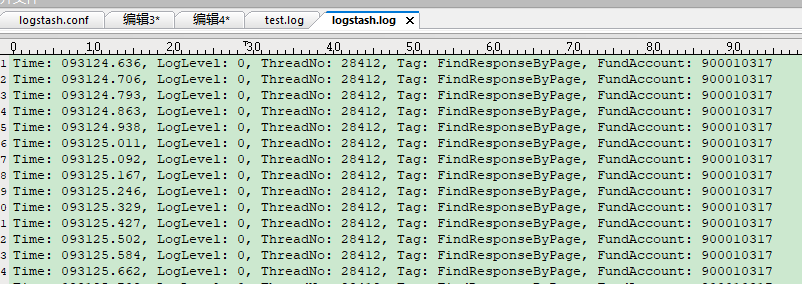
接下来是输出文件logstash.log,成功达到了了字段匹配以及筛选的效果:
最后补充一点,Logstash的插件非常多,配置项也非常多。建议直接在官网进行学习,再介绍下如何阅读官网的配置详解:
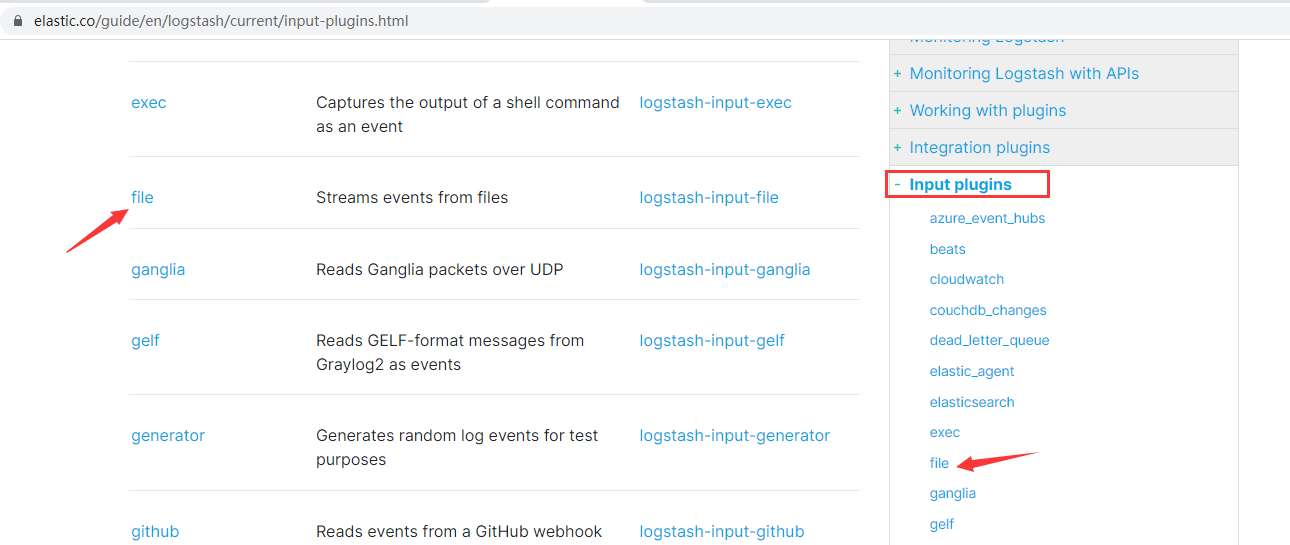
导航栏右侧有input、filter、output等插件的栏目,通过点击导航栏或者左侧正文部分的具体配置项,可以点击进一步查看配置详情:
ELK学习之Logstash篇的更多相关文章
- ELK学习之Logstash+Kafka篇
上一篇介绍了一下Logstash的数据处理过程以及一些基本的配置功能,同时也提到了Logstash作为一个数据采集端,支持对接多种输入数据源,其中就包括Kafka.那么这次的学习不妨研究一下Logst ...
- ELK学习笔记之Logstash详解
0x00 Logstash概述 官方介绍:Logstash is an open source data collection engine with real-time pipelining cap ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
- Java工程师学习指南 完结篇
Java工程师学习指南 完结篇 先声明一点,文章里面不会详细到每一步怎么操作,只会提供大致的思路和方向,给大家以启发,如果真的要一步一步指导操作的话,那至少需要一本书的厚度啦. 因为笔者还只是一名在校 ...
- ELK 性能(1) — Logstash 性能及其替代方案
ELK 性能(1) - Logstash 性能及其替代方案 介绍 当谈及集中日志到 Elasticsearch 时,首先想到的日志传输(log shipper)就是 Logstash.开发者听说过它, ...
- 一步步学习javascript基础篇(0):开篇索引
索引: 一步步学习javascript基础篇(1):基本概念 一步步学习javascript基础篇(2):作用域和作用域链 一步步学习javascript基础篇(3):Object.Function等 ...
- 一步步学习javascript基础篇(3):Object、Function等引用类型
我们在<一步步学习javascript基础篇(1):基本概念>中简单的介绍了五种基本数据类型Undefined.Null.Boolean.Number和String.今天我们主要介绍下复杂 ...
- Python3学习(3)-高级篇
Python3学习(1)-基础篇 Python3学习(2)-中级篇 Python3学习(3)-高级篇 文件读写 源文件test.txt line1 line2 line3 读取文件内容 f = ope ...
- Python3学习(2)-中级篇
Python3学习(1)-基础篇 Python3学习(2)-中级篇 Python3学习(3)-高级篇 切片:取数组.元组中的部分元素 L=['Jack','Mick','Leon','Jane','A ...
随机推荐
- 【LeetCode】133. 克隆图
133. 克隆图 知识点:图:递归;BFS 题目描述 给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆). 图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[No ...
- Vue学习笔记(二)动态绑定、计算属性和事件监听
目录 一.为属性绑定变量 1. v-bind的基本使用 2. v-bind动态绑定class(对象语法) 3. v-bind动态绑定class(数组语法) 4. v-bind动态绑定style(对象语 ...
- CF474D Flowers 题解
题目:CF474D Flowers 传送门 DP?递推? 首先可以很快看出这是一道 DP 的题目,但与其说是 DP,还不如说是递推. 大家还记得刚学递推时教练肯定讲过的一道经典例题吗?就是爬楼梯,一个 ...
- fastbin attack学习小结
fastbin attack学习小结 之前留在本地的一篇笔记,复习一下. 下面以glibc2.23为例,说明fastbin管理动态内存的细节.先看一下释放内存的管理: if ((unsigned ...
- 1549页Android最新面试题含答案
在今年年初的疫情中,成了失业人员之一,于是各种准备面试,发现面试题网上很多,但是都是很凌乱的,而且一个地方一点,没有一个系统的面试题库,有题库有的没有答案或者是答案很简洁,没有达到面试的要求.所以一直 ...
- nagios介绍和安装
官方support文献: https://support.nagios.com/kb/ 1.Nagios的监控模式: 主动式检查:NCPA.NRPE nagios安装后默认使用主动检查方式,远程执行代 ...
- Git-07-分支管理
创建与合并分支 为什么要创建分支? 假设你准备开发一个新功能,但是需要两周才能完成, 第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了. 如果等代码全部写完 ...
- 神经网络:numpy实现神经网络框架
欢迎访问个人博客网站获取更多文章: https://beityluo.space 本文用numpy从零搭建了一个类似于pytorch的深度学习框架 可以用于前面文章提到的MINST数据集的手写数字识别 ...
- JVM-超全图
- Pikachu-URL重定向、目录遍历、敏感信息泄露模块
一.不安全的URL跳转 1.概述 不安全的url跳转问题可能发生在一切执行了url地址跳转的地方.如果后端采用了前端传进来的(可能是用户传参,或者之前预埋在前端页面的url地址)参数作为了跳转的目的地 ...