【python3】爬取新浪的栏目分类
目标地址: http://www.sina.com.cn/
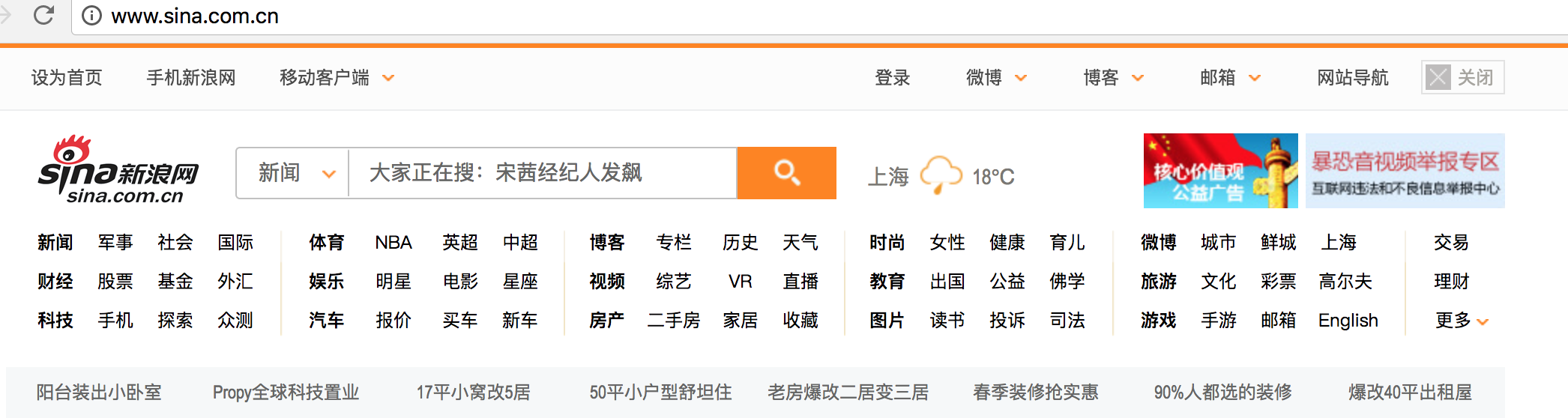
查看源代码,分析:
1 整个分类 在 div main-nav 里边包含
2 分组情况:1,4一组 、 2,3一组 、 5 一组 、6一组
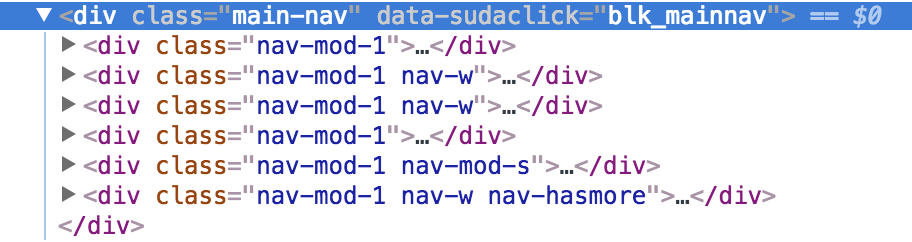
实现源码:
# coding=utf-8
import urllib.request
import ssl
from lxml import etree # 获取html内容
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
html = html.decode('utf-8')
return html # 获取内容
def get_title(arr, html, pathrole, sumtimes):
selector = etree.HTML(html)
content = selector.xpath(pathrole)
i = 0
while i <= sumtimes:
result = content[i].xpath('string(.)').strip()
arr.append(result)
i += 1
return arr # 创建ssl证书
ssl._create_default_https_context = ssl._create_unverified_context
url = "http://www.sina.com.cn/"
html = getHtml(url)
# 第一次获取
arr = []
pathrole1 = '//div[@class="main-nav"]/div[@class="nav-mod-1 nav-w"]/ul/li'
retult1 = get_title(arr, html, pathrole=pathrole1, sumtimes=23) # 第二次获取
if retult1:
pathrole2 = '//div[@class="main-nav"]/div[@class="nav-mod-1"]/ul/li'
retult2 = get_title(retult1, html, pathrole=pathrole2, sumtimes=23)
else:
print("error") # 第三次获取
if retult2:
pathrole3 = '//div[@class="main-nav"]/div[@class="nav-mod-1 nav-mod-s"]/ul/li'
retult3 = get_title(retult2, html, pathrole3, sumtimes=11)
else:
print("error") # 第四次获取
if retult3:
pathrole4 = '//div[@class="main-nav"]/div[@class="nav-mod-1 nav-w nav-hasmore"]/ul/li'
retult4 = get_title(retult3, html, pathrole4, sumtimes=1)
else:
print("error") # 第五次获取:更多列表
if retult4:
pathrole5 = '//div[@class="main-nav"]/div[@class="nav-mod-1 nav-w nav-hasmore"]/ul/li/ul[@class="more-list"]/li'
retult5 = get_title(retult4, html, pathrole5, sumtimes=6)
print(retult5)
else:
print("error")
以上代码,还可以继续优化,比如 xpath 的模糊匹配。可以把前四组合为一个,继续学习!
【python3】爬取新浪的栏目分类的更多相关文章
- Python3:爬取新浪、网易、今日头条、UC四大网站新闻标题及内容
Python3:爬取新浪.网易.今日头条.UC四大网站新闻标题及内容 以爬取相应网站的社会新闻内容为例: 一.新浪: 新浪网的新闻比较好爬取,我是用BeautifulSoup直接解析的,它并没有使用J ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- python3 爬取boss直聘职业分类数据(未完成)
import reimport urllib.request # 爬取boss直聘职业分类数据def subRule(fileName): result = re.findall(r'<p cl ...
- python3爬虫-爬取新浪新闻首页所有新闻标题
准备工作:安装requests和BeautifulSoup4.打开cmd,输入如下命令 pip install requests pip install BeautifulSoup4 打开我们要爬取的 ...
- python3使用requests爬取新浪热门微博
微博登录的实现代码来源:https://gist.github.com/mrluanma/3621775 相关环境 使用的python3.4,发现配置好环境后可以直接使用pip easy_instal ...
- Python 爬虫实例(7)—— 爬取 新浪军事新闻
我们打开新浪新闻,看到页面如下,首先去爬取一级 url,图片中蓝色圆圈部分 第二zh张图片,显示需要分页, 源代码: # coding:utf-8 import json import redis i ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- python爬取新浪股票数据—绘图【原创分享】
目标:不做蜡烛图,只用折线图绘图,绘出四条线之间的关系. 注:未使用接口,仅爬虫学习,不做任何违法操作. """ 新浪财经,爬取历史股票数据 ""&q ...
- xpath爬取新浪天气
参考资料: http://cuiqingcai.com/1052.html http://cuiqingcai.com/2621.html http://www.cnblogs.com/jixin/p ...
随机推荐
- JDBC PrepareStatement对象执行批量处理实例
以下是使用PrepareStatement对象进行批处理的典型步骤顺序 - 使用占位符创建SQL语句. 使用prepareStatement()方法创建PrepareStatement对象. 使用se ...
- 成都传智播客java就业班(14.04.01班)就业快报(Java程序猿薪资一目了然)
这是成都传智播客Java就业班的就业情况,很多其它详情请见成都传智播客官网:http://cd.itcast.cn?140812ls 姓名 入职公司 入职薪资(¥) 方同学 安**软件成都有限公司(J ...
- image 和 barplot 的组合
代码示例: par(mfrow = c(1, 2)) par(mar = c(1, 10, 1, 0), las = 1, ann = F) image(1:10, 1:10, matrix(samp ...
- YII2 搭建redis拓展
安装redis扩展: 1.通过composer进行安装,到项目根目录cmd运行(推荐) php composer.phar require --prefer-dist yiisoft/yii2-red ...
- 小程序笔记三:幻灯片swiper 和图片自定义高度
滑动组件:scroll-view wxml代码 <view> <scroll-view scroll-x="true" class="tab-h&quo ...
- Java学习之——Java Serializable
1.什么是Serializable接口? http://en.wikipedia.org/wiki/Serialization Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个 ...
- 文字描边css
-webkit-text-stroke: 3.3px #2A75BF; -webkit-text-fill-color:#fff; 该方法在安卓端貌似不支持,显示为一团 或: -webkit-text ...
- TensorFlow安装,升级,基本操作
一. 安装 ubuntu 16 python 2.7 pip install tensorflow 测试安装完成效果: 查看tensorFlow版本python import tensorflow a ...
- [OpenCV] Samples 15: Background Subtraction and Gaussian mixture models
不错的草稿.但进一步处理是必然的,也是难点所在. Extended: 固定摄像头,采用Gaussian mixture models对背景建模. OpenCV 中实现了两个版本的高斯混合背景/前景分割 ...
- ios7注意事项随笔
1,修改状态栏的样式和隐藏. 首先,需要在Info.plist配置文件中,增加键:UIViewControllerBasedStatusBarAppearance,并设置为YES: 然后,在UIVie ...