Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点。
简单线性回归
将数据拟合成一条直线。
y = ax + b , a 是斜率, b是直线截距
原始数据如下:
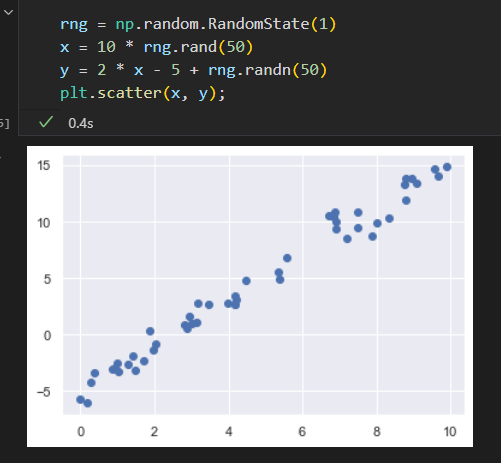
使用LinearRegression评估器来拟合数据

除了简单的直线拟合,还可以处理多维度的线性回归模型。
基函数回归
使用基函数 对原始数据进行变换,从而将变量间的线性回归模型 转换为非线性回归模型。
一维的输入变量x 转换成了 三维变量 x1 x2 x3.
转换后的模型仍然是一个线性模型。将一维的x投影到了高维空间
- 多项式基函数
多项式投影非常有用。 使用PloynomialFeatures转换器。
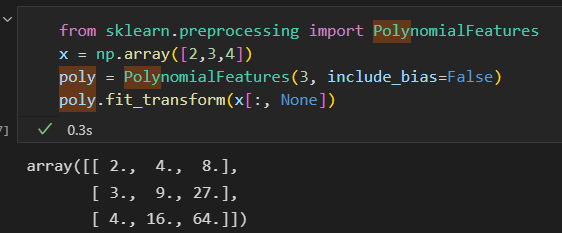
转换器通过指数函数,将一维数组转换成了三维数组,这个新的高维数组之后可以放在多项式回归模型中。
使用管道实现这些过程。
- 高斯基函数
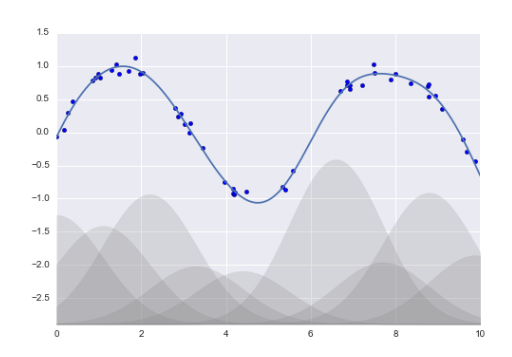
阴影部分代表不同规模的基函数。把他们放在一起是就会产生平滑的曲线。
正则化
在线性回归引入基函数会让模型变得灵活,但是也更容易过拟合,
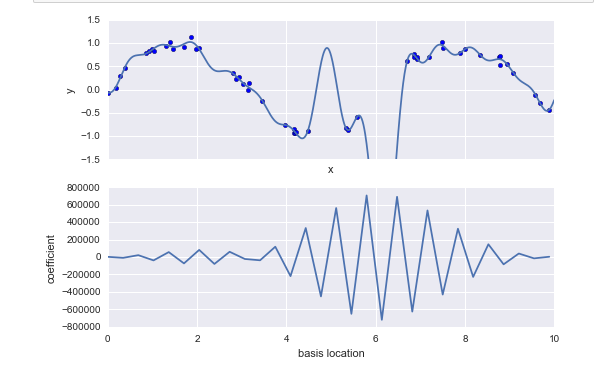
当 基函数 重叠的时候,通常就表明出现了过拟合: 相邻基函数的系数相互抵消。 这显然是有问题的。如果对较大的模型参数进行惩罚, penalize .从而一直模型的剧烈波动。这个惩罚机制 被称为 正则化。
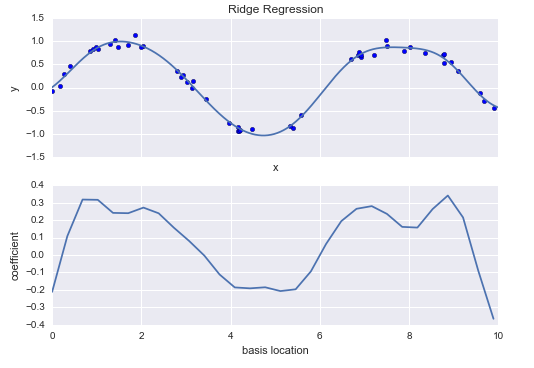
- 岭回归 L2范数正则化
正则化最常见的形式就是 岭回归 ridge regression. 处理方法是 对模型系数 平方和进行惩罚,
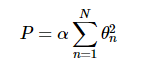
a 是一个自由参数,用来控制惩罚力度,这种带惩罚项的模型内置在Scikit-Learn的Ridge评估器中。

- Lasso正则化
其处理方法是堆模型系数绝对值的和 进行惩罚。
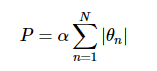
通过lasso回归惩罚,大多数基函数的系数都变成了0. 所以模型变成了原来基函数的一小部分
案列:预测自行车流量
数据源自不同天气 季节和其他条件通过 美国 西雅图 的一座桥的自行车流量
Python数据科学手册-机器学习:线性回归的更多相关文章
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
随机推荐
- 上传几张.NET5之后的机器人logo
上传几张.NET5之后的机器人logo
- 更强的 JsonPath 兼容性及性能测试之2022版(Snack3,Fastjson2,jayway.jsonpath)
2022年了,重新做了一份json path的兼容性与性能测试.三个市面上流行框架比较性测试. 免责声明:可能测试得方式不对而造成不科学的结果(另外,机器不同结果会有不同),可以留言指出来.以下测试数 ...
- vue 项目知识
Vue使用 Vue 源码解析 Vue SSR 如何调试Vue 源码 如何学习开源框架---> 从它的第一次commit 开始看 国外的文章 大致了解写框架的过程(英文关键字) 找到关键---&g ...
- SpringBoot快速整合通用Mapper
前言 后端业务开发,每个表都要用到单表的增删改查等通用方法,而配置了通用Mapper可以极大的方便使用Mybatis单表的增删改查操作. 通用mapper配置 1.添加maven: <depen ...
- 新型MPP的Doris数据库:数据模型和数据分区使用详解
Apache Doris是一个现代化的MPP分析性数据库产品.是一个由百度开源,在2018年贡献给Apache基金会,成为有顶级开源项目.仅需要亚秒级响应时间即可获得查询结果,可以有效地支持实时数据分 ...
- 无痕模式下 this.StorageManager.setItem) 本地存储丢失
在无痕模式下,存的this.StorageManager.setItem("recharge", JSON.stringify(recharge))本地存储会丢失,所以我们改成使用 ...
- BZOJ3037 创世纪(基环树DP)
基环树DP,攻的当受的儿子,f表选,g表不选.并查集维护攻受关系.若有环则记录,DP受的后把它当祖宗,再DP攻的. #include <cstdio> #include <iostr ...
- Luogu3904 三只小猪 (组合数学,第二类斯特林数,高精)
即使\(n<=50\),斯特林数也会爆long long. #include <iostream> #include <cstdio> #include <cstr ...
- 数据结构与算法【Java】03---栈
前言 数据 data 结构(structure)是一门 研究组织数据方式的学科,有了编程语言也就有了数据结构.学好数据结构才可以编写出更加漂亮,更加有效率的代码. 要学习好数据结构就要多多考虑如何将生 ...
- html弹出二选一窗口,然后根据点击执行对应的js方法
html弹出二选一窗口,然后根据点击执行对应的js方法 layer.confirm("我是弹出来的字", {btn:['确认','取消']}, function(){ ...方法1 ...