Python数据科学手册-机器学习: 支持向量机
support vector machine SVM
是非常强大、 灵活的有监督学习算法, 可以用于分类和回归。
贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签。是属于 生成分类 方法。
判别分类:不再为每类数据建模,而是用一条分割线 或者 流形体 将各种类型分开。
原始数据:
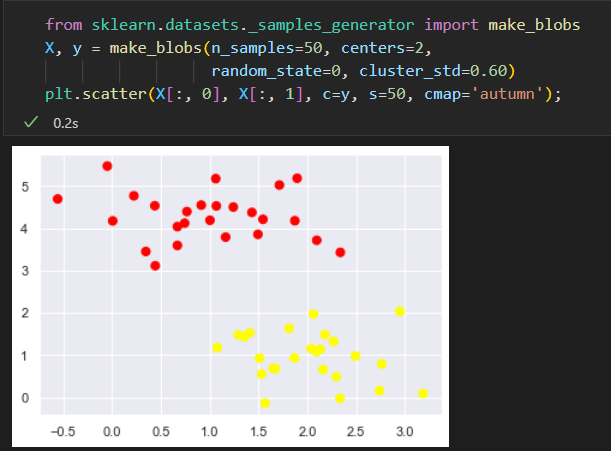
线性判别分类器 尝试 化一条 将数据 分成 俩部分的直线,这样就构成了一个分类模型。
可以发现不止一条直线可以将它们完美分割。
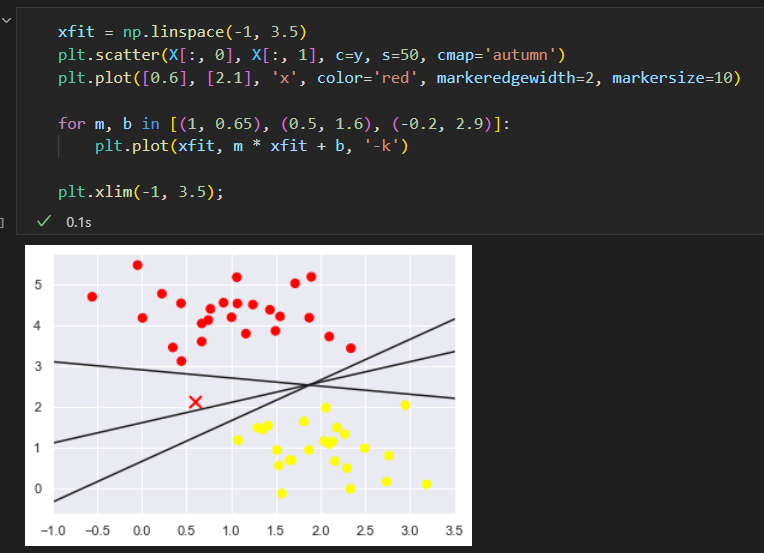
不同的分割线,会让新数据分配到不同的标签。
支持向量机:边界最大化
不是画一条细线来区分,而是画一条到最近点 边界 、有宽度 的线条。
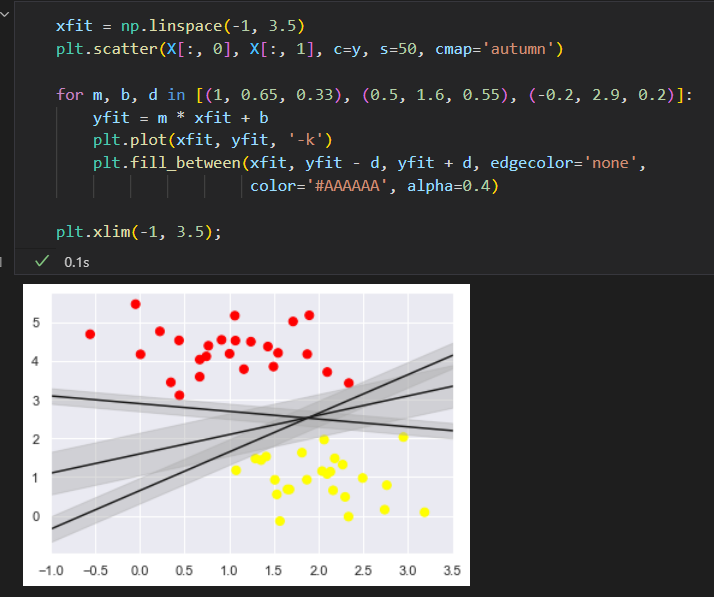
在支持向量机中,选择边界最大的那条线,是模型最优解。 边界最大化评估器。
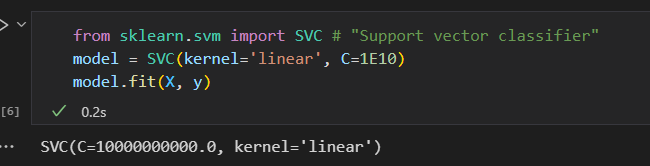
拟合支持向量机
训练一个SVM模型,用一个线性核函数。并将参数C设置为一个很大的数。
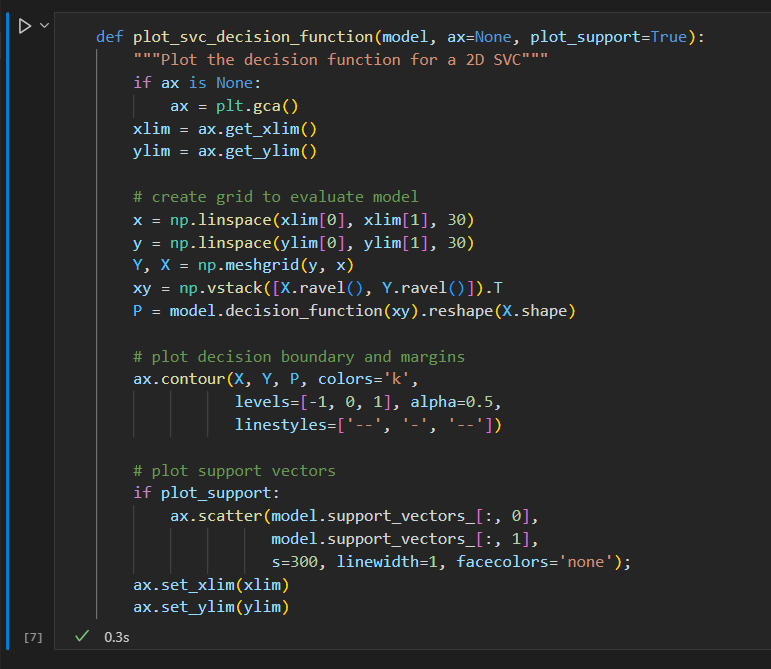
创建一个辅助函数画出SVM的决策边界。
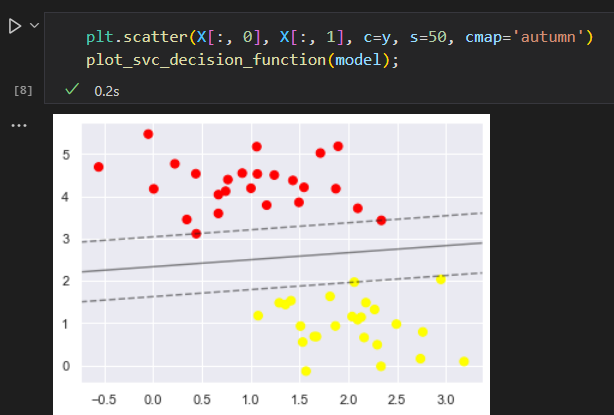
一些点正好在边界线上,这些点是拟合的关键支持点。被称为支持向量
支持向量的左边存放在分类器的support_vectors_ 属性中。
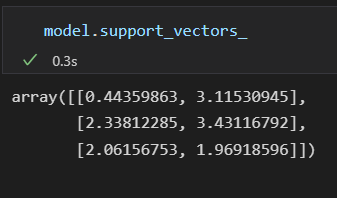
说明:任何在正确分类一侧远离边界线的点都不影响拟合结果。 因为这些点不会对拟合模型的损失函数产生任何影响,只要它们没跨越边界线,位置和数量就都无关紧要。
超越线性边界:核函数 SVM模型
将SVM模型 与 核函数 组合使用。功能会非常强大。
为了应用核函数,引入一些非线性可分数据。
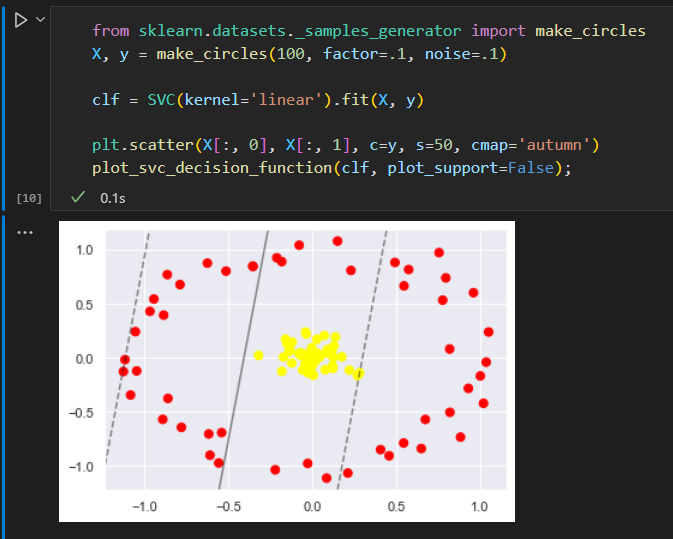
前面学到过,把数据投影到高维空间。从而使线性分割器派上用场。
一个简单的投影方法就是计算一个以 数据圆圈 为中心的径向基函数:
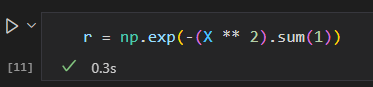
用三维图来可视化新增的维度
增加新的维度后,数据变成了线性可分状态,
通常选择基函数比较困难,我们需要让模型自动 指出 最合适的基函数。
一种 策略是计算基函数在数据集 上每个点的 变换结果,让SVM算法从所有结果中筛选出最优解。
这种基函数变换方式被称为 核变换
问题是:当N不断增大的时候,就会出现维度灾难。计算量巨大,
由于核函数技巧提供的小程序可以隐式计算 核变换数据的拟合。
在Scikit-Learn里面,我们可以应用核函数化的SVM模型,将线性核转变为 RBF (径向基函数)核。 设置kernel模型超参数即可。
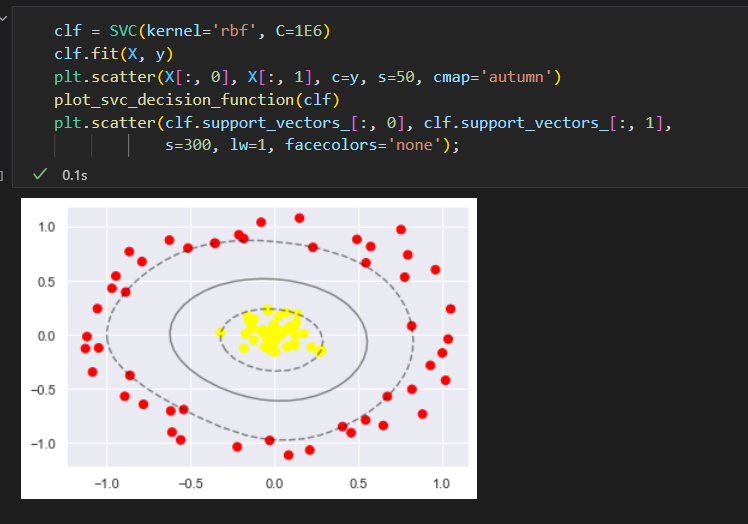
SVM优化:软化边界
如果数据有重叠,SVM实现了一些修正因子来“软化”边界,为了取得更好的拟合效果,允许一些点位于边界线之内。
边界线的硬度可以通过超参数进行控制,通常是C,
如果C很大,边界就会很硬,数据点便不能在边界内生存,
如果C比较小,边界就会较软,有一些数据点就可以穿越边界线。
案例:人脸识别
支持向量机总结
优点:
- 模型依赖的支持向量比较少,说明它们都是非常精致的模型,消耗内存少。
- 一旦模型训练完成,预测阶段速度非常快
- 由于模型只收边界线附近 的 点的影响,因此它们对于高维数据的学习效果非常好
- 与核函数方法的配合 极具通用性,能够适用不同类型的数据
缺点: - 随着样本量N的不断增加,最差的训练时间复杂度会达到O[N^3] .大样本学习的计算成本高
- 训练效果非常依赖于边界软化参数C的选择是否合理,这需要通过交叉检验自行搜索
Python数据科学手册-机器学习: 支持向量机的更多相关文章
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
随机推荐
- 利用噪声构建美妙的 CSS 图形
在平时,我非常喜欢利用 CSS 去构建一些有意思的图形. 我们首先来看一个简单的例子.首先,假设我们实现一个 10x10 的格子: 此时,我们可以利用一些随机效果,优化这个图案.譬如,我们给它随机添加 ...
- 阻塞赋值-非阻塞赋值(LUT,FDC,BUF...)
一.看RTL级综合网络 1.1 FDC FDPE FDRE FDSE均是XILINX FPGA片上资源中四种不同的触发器,具体功能可直接百度 1.2 LUT是实现组合逻辑功能的一张真值表,根据输入值直 ...
- linux系统中Nginx+FFmPeg+vlc实现网页视频播放配置过程
linux系统中Nginx+FFmPeg实现网页监控视频播放配置过程 1.安装好的nginx上添加模块nginx-http-fiv-module-master 此模块是rtmp模块的升级版,有它所有的 ...
- ROS机械臂 Movelt 学习笔记3 | kinect360相机(v1)相关配置
目标是做一个机械臂视觉抓取的demo,在基地里翻箱倒柜,没有找到学长所说的 d435,倒是找到了一个老古董 kinect 360. 前几天就已经在旧电脑上配置好了,现在记录在新电脑上的配置过程. 1. ...
- SpringBoot定时任务 - 集成quartz实现定时任务(单实例和分布式两种方式)
最为常用定时任务框架是Quartz,并且Spring也集成了Quartz的框架,Quartz不仅支持单实例方式还支持分布式方式.本文主要介绍Quartz,基础的Quartz的集成案例本,以及实现基于数 ...
- 日夕如是寒暑不间,基于Python3+Tornado6+APScheduler/Celery打造并发异步动态定时任务轮询服务
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_220 定时任务的典型落地场景在各行业中都很普遍,比如支付系统中,支付过程中因为网络或者其他因素导致出现掉单.卡单的情况,账单变成了 ...
- 不安装运行时运行.NET程序
好久没写文章了,有些同学问我公众号是不是废了?其实并没有.其实想写的东西很多很多,主要是最近公司比较忙,以及一些其他个人原因没有时间来更新文章.这几天抽空写了一点点东西,证明公众号还活着. 长久以来的 ...
- 从零开始Blazor Server(7)--使用Furion权限验证
序 上面两篇我们讲了怎么用OnNavigateAsync来验证权限,又写了怎么用策略来验证权限. 其实我们既然集成了Fution,就可以用Furion带的方式来验证. 创建AdminHandler 我 ...
- jquery转换为同步请求
$.ajax({ async: false, //采用异步的方式提交,不添加默认是异步,布尔值为 true type : 'POST', url : 'https://i-beta.cnblogs.c ...
- Docker Compose安装部署Jenkins
流水线可以让项目发布流程更加清晰,docker可以大大减少Jenkins配置. 1.前言 数据卷挂载到 /var 磁盘目录下,因为该磁盘空间较大,后面需要挂载容器数据卷,以防内存吃紧. 为了可以留存启 ...