Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型
朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集。因为运行速度快,可调参数少。是一个快速粗糙的分类基本方案。
naive Bayes classifiers
贝叶斯分类
朴素贝叶斯分类器建立在贝叶斯分类方法的基础上。数学基础是贝叶斯定理。 一个描述统计量条件概率关系的公式。
在贝叶斯分类中,我们希望确定一个具有某些特征的样本 属于 某类标签的概率。 通常记为 P(L|特征)
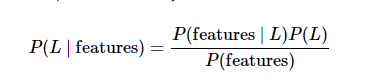
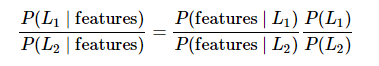
需要确定俩种标签,定义为L1和L2. 计算俩个标签的后验概率的比值
现在需要一种模型。帮我们计算每个标签的P(特征|Li).这种模型被称为生成模型。
因为它可以训练处生成输入数据的假设随机过程(概率分布)
为每中标签设置生成模型 是贝叶斯分类器训练过程的主要部分。
之所以称为朴素 。是因为 如果对每种标签的生成模型进行非常简单的假设,就能找到每种类型 生成模型的近似解,然后就可以使用贝叶斯分类。
不同类型的朴素贝叶斯分类器是有对数据的不同假设决定的。
高斯朴素贝叶斯
Gaussian naive Bayes 。 假设每个标签的数据都服从简单的高斯分布。
原始数据如下:
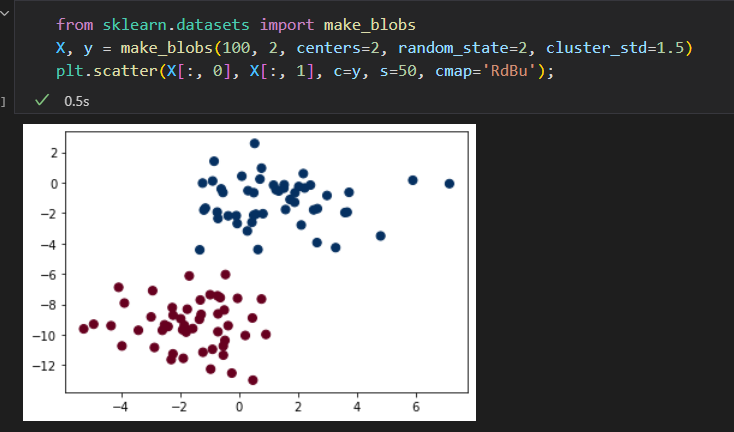
假设数据服从高斯分布,且变量无协方差 (线性无关)
只需要找出每个标签的所有样本点均值 和 标准差。再定义一个高斯分布。就可以拟合模型了。
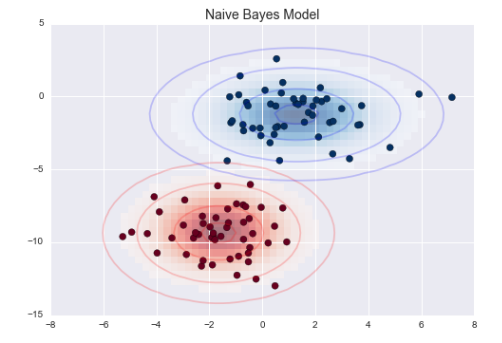
每个椭圆曲线表示每个标签的高斯生成模型。 越靠近椭圆中心的可能性越大。
通过每种类型的生成模型,可以计算出任意数据点的似然估计 P (特征|L1) 。
然后根据贝叶斯定理计算出 后验概率比值, 从而确定每个数据点可能性最大的标签。
评估器 GaussianNB实现:
预测标签:
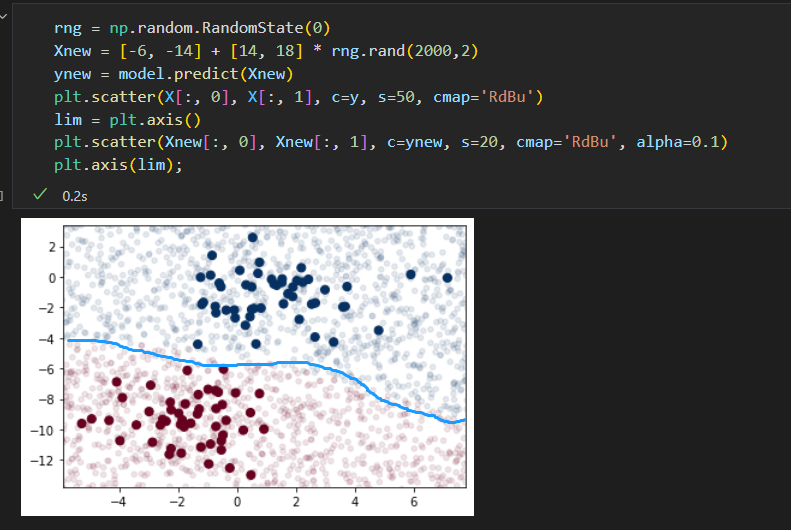
可以在分类结果中看到一条稍显 弯曲 的边界
通常:高斯朴素贝叶斯的边界 是二次方曲线。
多项式朴素贝叶斯
假设特征是由一个简单多项式分布 生成的。 多项分布式可以描述 各种类型样本 出现次数的概率。
- 文本分类
特征:分类文本的单词出现次数。
执行了15分钟。。。淦。
选择四类新闻,下载训练集和测试集
看其中一篇新闻:

为了让这些数据能用于机器学习,需要将每个字符串的内容转换成数值向量。
将模型应用到训练数据上。
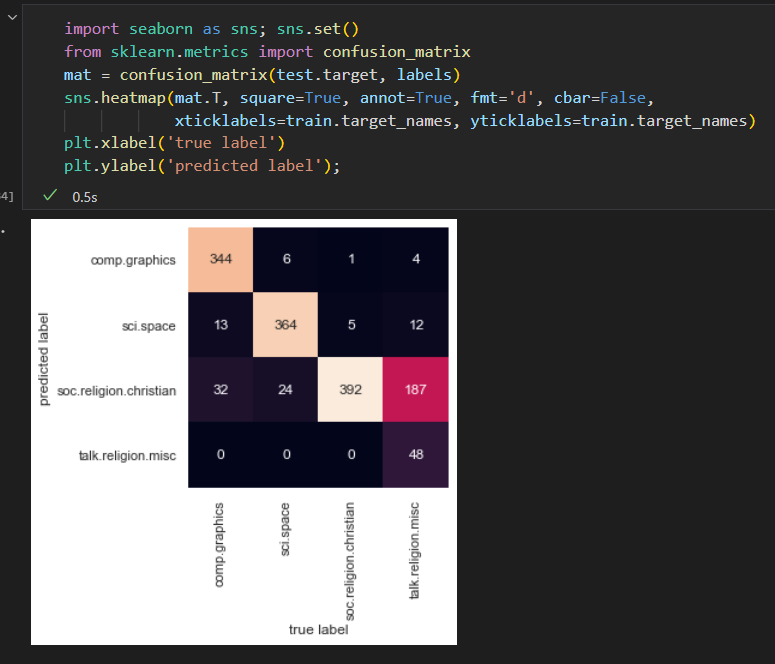
用混淆矩阵 统计 结果。
Python数据科学手册-机器学习:朴素贝叶斯分类的更多相关文章
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
随机推荐
- Python之枚举法解数学题
作为初二的学生,数学题总是令我苦恼的问题.尤其是我们这里的预备班考试(即我们这里最好的两所高中提前一年招生,选拔尖子生的考试)将近,我所面对的数学题越发令人头疼. 这不,麻烦来了: 如图,在正方形AB ...
- C语言求100以内的和的4种方式
C语言的一个很经典的例子,帮助熟练运行几个循环的写法 * 方法一(do---while语句) #include main () { int i,sum=0; do { sum=sum+i; i++; ...
- 深入理解Apache Hudi异步索引机制
在我们之前的文章中,我们讨论了多模式索引的设计,这是一种用于Lakehouse架构的无服务器和高性能索引子系统,以提高查询和写入性能.在这篇博客中,我们讨论了构建如此强大的索引所需的机制,异步索引机制 ...
- 论文阅读 Inductive Representation Learning on Temporal Graphs
12 Inductive Representation Learning on Temporal Graphs link:https://arxiv.org/abs/2002.07962 本文提出了时 ...
- 面试突击64:了解 HTTP 协议吗?
HTTP(Hyper Text Transfer Protocol)超文本传输协议,下文简称 HTTP,它的作用是用于实现服务器端和客户端的数据传输的.它可以传输任意的数据类型,如文本.HTML.图片 ...
- 编译安装Python出现“pip is configured with locations that require TLS/SSL, however the ssl.....”
ubuntu: sudo apt-get install libssl-dev Cenos: sudo yum install openssl-devel 重新编译: ./configure --en ...
- Idea 的Test测试报错:java.lang.IllegalStateException: Failed to load ApplicationContext
因为在Test里面使用了注解@Autowired 引入来至bean.xml文件的内容 ,而在Test没有没有办法自动引入,需要在Test类上加上注解 @ContextConfiguration(loc ...
- vivo官网APP全机型UI适配方案
vivo 互联网客户端团队- Xu Jie 日益新增的机型,给开发人员带来了很多的适配工作.代码能不能统一.apk能不能统一.物料如何选取.样式怎么展示等等都是困扰开发人员的问题,本方案就是介绍不同机 ...
- 7.5 The Morning after Halloween
本题主要是存储的问题,在存储上笔者原先的代码占用了大量的内存空间 这边笔者采用暴力的思想直接硬开所有情况的16^6的数组来存储该问题,当然这在时间上是十分浪费的,因为初始化实在太慢了,剩下的就是状态转 ...
- docker Compose 部署springboot+vue前端端分离项目
温馨提示:如果有自己的服务器最好不过了,这样部署网项目就可以上线了.没有的话,只能使用localhost 本机访问啦,记得替换 ngixn 中的ip地址.域名为localhost. (一) 准备工作 ...