量化预测质量之分类报告 sklearn.metrics.classification_report
classification_report的调用为:classification_report(y_true, y_pred, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False)
y_true : 真实值
y_pred : 预测值
from sklearn.metrics import classification_report truey = np.array([0,0,1,1,0,0])
prey = np.array([1,0,1,0,0,0])
print(classification_report(truey,prey,target_names=['zhen','jia']))
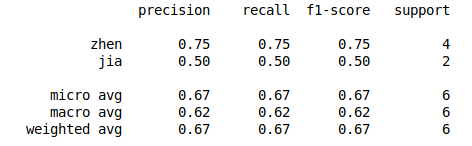
1)fraction of true positives/false positive/false negative/true negative
True Positive (真正, TP)被模型预测为正的正样本;
True Negative(真负 , TN)被模型预测为负的负样本 ;
False Positive (假正, FP)被模型预测为正的负样本;
False Negative(假负 , FN)被模型预测为负的正样本;
2)precision/recall,准确率和召回率
系统检索到的相关文档(A)
系统检索到的不相关文档(B)
相关但是系统没有检索到的文档(C)
不相关但是被系统检索到的文档(D)
召回率R:R=A/(A+C)
精度P: P=A/(A+B).
3)F1-score
F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0。

量化预测质量之分类报告 sklearn.metrics.classification_report的更多相关文章
- scikit-learn - 分类模型的评估 (classification_report)
使用说明 参数 sklearn.metrics.classification_report(y_true, y_pred, labels=None, target_names=None, sample ...
- 机器学习笔记,使用metrics.classification_report显示精确率,召回率,f1指数
sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息. 主要参数: y_true:1维数组,或标签指示器数组 ...
- 线性回归 - LinearRegression - 预测糖尿病 - 量化预测的质量
线性回归是分析一个变量与另外一个或多个变量(自变量)之间,关系强度的方法. 线性回归的标志,如名称所暗示的那样,即自变量与结果变量之间的关系是线性的,也就是说变量关系可以连城一条直线. 模型评估:量化 ...
- sklearn.metrics.roc_curve使用说明
roc曲线是机器学习中十分重要的一种学习器评估准则,在sklearn中有完整的实现,api函数为sklearn.metrics.roc_curve(params)函数. 官方接口说明:http://s ...
- sklearn.metrics中的评估方法
https://www.cnblogs.com/mindy-snail/p/12445973.html 1.confusion_matrix 利用混淆矩阵进行评估 混淆矩阵说白了就是一张表格- 所有正 ...
- Python Sklearn.metrics 简介及应用示例
Python Sklearn.metrics 简介及应用示例 利用Python进行各种机器学习算法的实现时,经常会用到sklearn(scikit-learn)这个模块/库. 无论利用机器学习算法进行 ...
- sklearn.metrics中的评估方法介绍(accuracy_score, recall_score, roc_curve, roc_auc_score, confusion_matrix)
1 accuracy_score:分类准确率分数是指所有分类正确的百分比.分类准确率这一衡量分类器的标准比较容易理解,但是它不能告诉你响应值的潜在分布,并且它也不能告诉你分类器犯错的类型.常常误导初学 ...
- 2016 移动应用质量大数据报告--转自腾讯Bugly
2016年,在“互联网+”战略的推动下,移动互联网与越来越多传统行业的结合更加紧密,用户使用移动互联网的工作场景.生活场景.消费场景都在悄然发生着改变, 移动互联网产品在智能硬件.医疗.汽车.旅游.教 ...
- sklearn.metrics.roc_curve
官方网址:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics 首先认识单词:metrics: ['mɛ ...
随机推荐
- nginx如何一个域名多个端口?
方法一 写三个 listen server { listen 80; listen 81; listen 82; server_name www.sifou.com; ... 方法二 写三个serve ...
- 吴裕雄--天生自然 PHP开发学习:While 循环
<html> <body> <?php $i=1; while($i<=5) { echo "The number is " . $i . &q ...
- Dynamics CRM - 不同类型字段在 Plugin 里的赋值方式
在编写 Plugin 代码之前,我们可以需要用 SDK bin 目录下的 CrmSvcUtil.exe 来将 CRM Site 上所有的 Entity 转换成类,而 Entity 里的 Field 也 ...
- TCP/IP通信过程
一.参考网址 1.以太网帧格式.IP数据报格式.TCP段格式+UDP段格式 详解 2. 二.TCP的建立过程 1.例子: 192.168.22.66 telenet到192.168.22.74的tcp ...
- 浅谈对RabbitMQ的认识
一.什么是消息队列?什么时候使用它? 在传统的web架构中(此处特指Java SSM架构),用户在web中进行了某项需要和后台产生交互的操作后,一般都要开启一个session,从view层开始,由co ...
- day65-CSS选择器和样式优先级
1. CSS CSS(Cascading Style Sheet,层叠样式表)定义如何显示HTML元素. 当浏览器读到一个样式表,它就会按照这个样式表来对文档进行格式化(渲染). 2.CSS语法 每个 ...
- python格式化输出的三种形式
法一: list_a = [1, 2, 3] str_b = 'aaa' string = "There are two contents:%s, %s" % (list_a, s ...
- 小白学习之pytorch框架(6)-模型选择(K折交叉验证)、欠拟合、过拟合(权重衰减法(=L2范数正则化)、丢弃法)、正向传播、反向传播
下面要说的基本都是<动手学深度学习>这本花书上的内容,图也采用的书上的 首先说的是训练误差(模型在训练数据集上表现出的误差)和泛化误差(模型在任意一个测试数据集样本上表现出的误差的期望) ...
- vi——终端中的编辑器
vi--终端中的编辑器 目标 vi 简介 打开和新建文件 三种工作模式 常用命令 分屏命令 常用命令速查图 01. vi 简介 1.1 学习 vi 的目的 在工作中,要对 服务器 上的文件进行 简单 ...
- POJ 3585 Accumulation Degree【换根DP】
传送门:http://poj.org/problem?id=3585 题意:给定一张无根图,给定每条边的容量,随便取一点使得从这个点出发作为源点,发出的流量最大,并且输出这个最大的流量. 思路:最近开 ...