Logstash实践
转载请注明出处:https://www.cnblogs.com/shining5/p/9542710.html
Logstash简介
一个开源的数据收集引擎,具有实时数据传输能力,可以统一过滤来自不同源的数据,并按照开发者制定的规范输出到目的地。
顾名思义,Logstash 收集数据对象就是日志文件,由于日志文件来源众多(如,系统日志,服务器日志等),且内容杂乱,不便于人类进行观察。因此,可以使用Logstash对日志文件进行收集和统一过滤,变成可读性高的内容。
组成结构
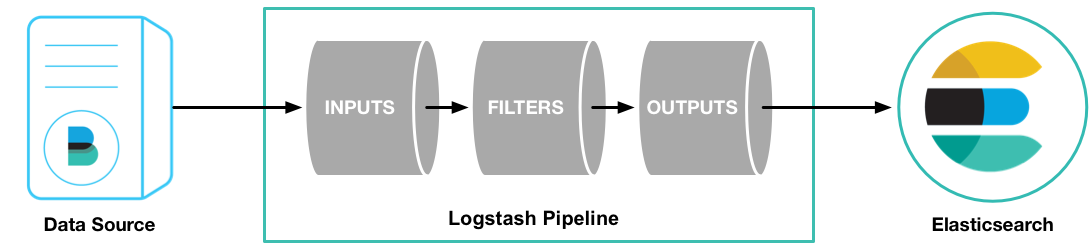
Logstash 通过管道进行运作,管道有两个必需的元素,输入和输出,还有一个可选的元素:过滤器
输入插件从数据源读取数据,过滤器插件根据用户指定的数据格式修改数据,输出插件则将数据写入到目的地,如下图
接下来讲解一个工作中的实例。
需求概述
本次需求如下:
- 统一各语言日志格式
- 将各个项目生成的日志进行过滤分析存入Elasticsearch
解决方案
统一log格式
因小组内测试代码语言较多(go/java/shell/python等),为了简化更确切的应该是统一过滤规则,首先需要统一日志格式。
熟悉java语言的童鞋对log4j一定不陌生,log4j可以控制日志信息输送的目的地,控制日志的输出格式,日志级别,而且这些只需一个配置文件即可灵活配置,无需修改代码。
那么go,python,shell是否有类似的框架呢,答案是肯定的,它们分别是log4go,log4p,log4sh
我们先来统一日志格式,根据以往经验及今后扩展,日志格式如下:
时间 - 日志级别 - 日志logid- 文件名及行数 - 日志内容
2018-07-09 15:50:35,907 [DEBUG] logid:000 demo.py:fun1:10 Type some log.
此处对各语言log4日志框架不详细说明,可参见本人实现的demo:https://github.com/tianruiMM/log4pgoshj 查看各语言日志模版
其他说明:本项目中的bin/init.sh可以根据给定的语言初始化log4相关的项目,可参考脚本中的说明
应用logstash
添加过滤规则
2018-07-09 15:50:35,907 [DEBUG] logid:000 demo.py:fun1:10 Type some log.
统一日志格式后,接下来将每行日志转换成结构化的日志,在Logstash中,这项工作由logstash-filter-grok来完成,它有超过200个可用的,大家都认为比较有用的Grok模式,例如IPv6地址,UNIX路径等。
使用Grok库,我们可以很容易的就完成日志格式化提取的任务
%{TIMESTAMP_ISO8601:timestamp}\s+\[%{LOGLEVEL:loglevel}\]\s+%{DATA:logid}\s+%{DATA:method}\s+%{GREEDYDATA:msg}
提取后的数据格式如下:
{
"timestamp": [
"2018-07-09 15:50:35,907"
],
"loglevel": [
"DEBUG"
],
"logid": [
"logid:000"
],
"method": [
"demo.py:fun1:10"
],
"msg": [
"Type some log."
]
}
Grok部分模式对应的正则如下:
TIMESTAMP_ISO8601:%{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?
LOGLEVEL:([A-a]lert|ALERT|[T|t]race|TRACE|[D|d]ebug|DEBUG|[N|n]otice|NOTICE|[I|i]nfo|INFO|[W|w]arn?(?:ing)?|WARN?(?:ING)?|[E|e]rr?(?:or)?|ERR?(?:OR)?|[C|c]rit?(?:ical)?|CRIT?(?:ICAL)?|[F|f]atal|FATAL|[S|s]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)
DATA:.*?
SPACE:\s* 其中\s+匹配一个或多个空格
grok其它模式说明请参考:http://grokdebug.herokuapp.com/patterns#
备注:可以使用在线调试器Grok Debugger进行调试
生成配置文件
在生产环境中,Logstash的管道要复杂很多,可能需要配置多个输入,过滤器和输出插件。
因此需要一个配置文件管理输入,过滤器和输出相关的配置,配置文件内容格式如下:
# 输入
input {
...
}
# 过滤器
filter {
...
}
# 输出
output {
...
}
在实际测试过程中,日志目录往往配置在当前项目路径下。对于收集单一项目日志,这没有什么问题,但当收集多个项目日志或增加新项目时,每次都需要手动更新input、output内容。为了解决上述问题,首先统一日志放置目录,其次根据目录自动生成配置文件。
本人实现了一个shell脚本:
- 根据给定目录,遍历当前路径下最深子目录;
- 根据子目录列表生成Logstash配置文件
- 根据配置文件及最深子目录列表,启动Logstash Docker容器以启动Logstash服务
精简后的代码如下:
#!/usr/bin/env bash
# 存储最深子目录列表
dir_list=()
# 给定的log根目录
base_dir="/data0/dorylus/local/gitlab/logs"
# logstash目录
conf_path="/data0/dorylus/pipeline"
conf_file="$conf_path/logstash.conf"
# elasticsearch服务
address="127.0.0.1:9200"
# logstash docker image
docker_file="docker.elastic.co/logstash/logstash:6.3.2"
# container name
container_name="logstash"
# 递归读取最深子目录
function read_dir(){
# echo -e $1
if [ "`ls $1`" = "" ] || [ `ls -l $1|grep ^d|wc -l` -eq 0 ]
then
dir_list[${#dir_list[@]}]=$1
else
for file in `ls $1`
do
if [ -d $1"/"$file ]
then
read_dir $1"/"$file
fi
done
fi
}
# 将根目录下所有最深文件夹写入配置文件
function write_conf_file(){
# 写入input配置
echo -e "input {" > $conf_file
for dir in ${dir_list[@]}
do
path=$dir
# 除根路径的子目录
obj_dir=${dir:((${#base_dir}+1))}
# 将/替换成-,type为索引名
type=${obj_dir//\//-}
echo " file {
path => [\"$path/*.log*\"]
type => \"$type\"
start_position => "beginning"
}" >> $conf_file done
echo -e "}" >> $conf_file
# 写入filter配置,过滤日志信息
echo "filter {
grok {
match => [
\"message\", \"%{TIMESTAMP_ISO8601:logtime}\s+\[%{LOGLEVEL:loglevel}\]\s+%{DATA:logid}\s+%{DATA:method}\s+%{GREEDYDATA:msg}\",
\"message\", \"\[%{DATA:logtime}\] *\[%{LOGLEVEL:loglevel}\] *%{DATA:method} * %{GREEDYDATA:msg}\"
]
}
}" >> $conf_file
# 写入output配置
echo -e "output {" >> $conf_file
for dir in ${dir_list[@]}
do
obj_dir=${dir:((${#base_dir}+1))}
type=${obj_dir//\//-}
echo " if [type] == \"$type\" {
elasticsearch {
hosts => [\"$address\"]
index => \"$type-%{+YYYY.MM.dd}\"
}
}" >> $conf_file done
echo "}" >> $conf_file }
function conf(){
if [ ! -d $conf_path ];then
mkdir -p $conf_path
fi
read_dir $base_dir
write_conf_file $dir_list
}
# 启动logstash服务
function start(){
conf $1
# echo ${dir_list[*]}
v_conf=""
# 根据获取的子目录列表,挂载各子目录
for dir in ${dir_list[@]}
do
v_conf=$v_conf" -v $dir/:$dir/"
done
command="sudo docker run --name $container_name --net=host -d --env XPACK.MONITORING.ELASTICSEARCH.URL=http://$address -v $conf_path/:/usr/share/logstash/pipeline/ $v_conf $docker_file"
$command
# sudo docker run --name $container_name --net=host --rm -ti -v $conf_path/:/usr/share/logstash/pipeline/ -v /data0/dorylus/config/logstash.yml:/usr/share/logstash/config/logstash.yml $docker_file
}
完整版参见:https://github.com/tianruiMM/log4pgoshj/blob/master/bin/operateLogstash.sh
举例说明:日志目录如下:
├── durian
│ └── case
│ ├── 20180822-065527_deploy.log
│ ├── 20180823-032739_deploy.log
│ ├── 20180824-041952_deploy.log
│ ├── 20180824-085657_deploy.log
│ ├── 20180824-091059_deploy.log
│ ├── consul.log
│ ├── debug.log
│ ├── error.log
│ ├── FailedCaseId.txt
│ ├── nginx.log
│ └── result.log
└── fig
└── case
├── error.log
└── info.log通过脚本生成的配置文件如下:
input {
file {
path => ["/data0/dorylus/local/gitlab/logs/durian/case/*.log*"]
type => "durian-case"
start_position => beginning
}
file {
path => ["/data0/dorylus/local/gitlab/logs/fig/case/*.log*"]
type => "fig-case"
start_position => beginning
}
}
filter {
grok {
match => [
"message", "%{TIMESTAMP_ISO8601:logtime}\s+\[%{LOGLEVEL:loglevel}\]\s+%{DATA:logid}\s+%{DATA:method}\s+%{GREEDYDATA:msg}",
"message", "\[%{DATA:logtime}\] *\[%{LOGLEVEL:loglevel}\] *%{DATA:method} * %{GREEDYDATA:msg}"
]
}
}
output {
if [type] == "durian-case" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "durian-case-%{+YYYY.MM.dd}"
}
}
if [type] == "fig-case" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "fig-case-%{+YYYY.MM.dd}"
}
}
}
启动Logstash容器后,通过kibana可以查看格式化日志结果:
参考文档:
https://www.jianshu.com/p/86133dd66ca4
https://www.elastic.co/guide/en/logstash/current/index.html
Logstash实践的更多相关文章
- Logstash实践: 分布式系统的日志监控
文/赵杰 2015.11.04 1. 前言 服务端日志你有多重视? 我们没有日志 有日志,但基本不去控制需要输出的内容 经常微调日志,只输出我们想看和有用的 经常监控日志,一方面帮助日志微调,一方面及 ...
- Logstash过滤插件
filter初级 Logstash安装 ### 设置YUM源 # rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch # t ...
- Elasticsearch优化 & filebeat配置文件优化 & logstash格式配置 & grok实践
Elasticsearch优化 & filebeat配置文件优化 & logstash格式配置 & grok实践 编码转换问题(主要就是中文乱码) (1)input 中的cod ...
- ELK——Logstash 2.2 date 插件【翻译+实践】
官网地址 本文内容 语法 测试数据 可配置选项 参考资料 date 插件是日期插件,这个插件,常用而重要. 如果不用 date 插件,那么 Logstash 将处理时间作为时间戳.时间戳字段是 Log ...
- ELK——Logstash 2.2 mutate 插件【翻译+实践】
官网地址 本文内容 语法 测试数据 可选配置项 mutate 插件可以在字段上执行变换,包括重命名.删除.替换和修改.这个插件相当常用. 比如: 你已经根据 Grok 表达式将 Tomcat 日志的内 ...
- 使用ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践--转载
原文地址:https://wsgzao.github.io/post/elk/ 另外可以参考:https://www.digitalocean.com/community/tutorials/how- ...
- Centos6.5使用ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践
Centos6.5安装Logstash ELK stack 日志管理系统 概述: 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的 ...
- logstash的各个场景应用(配置文件均已实践过)
场景: 1) datasource->logstash->elasticsearch->kibana 2) datasource->filebeat->logstash- ...
- Logstash生产环境实践手册(含grok规则示例和ELKF应用场景)
ELKF应用场景: 1) datasource->logstash->elasticsearch->kibana 2) datasource->filebeat->log ...
随机推荐
- python中安装surprise中出现error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools":
pip安装 安装之前要先进行numpy的安装 pip install numpy pip install surprise 安装出错: 安装surprise需要Microsoft visual c++ ...
- iOS燃烧动画、3D视图框架、天气动画、立体相册、微信朋友圈小视频等源码
iOS精选源码 iOS天气动画,包括太阳,云,雨,雷暴,雪动画. 较为美观的多级展开列表 3D立体相册,可以旋转的立方体 一个仪表盘Demo YGDashboardView 一个基于UIScrollV ...
- XRichText
XRichText是一个可以显示Html富文本的TextView.可以用于显示新闻.商品详情等场景.欢迎star.fork,提出意见. 使用 Gradle : compile 'cn.droidlov ...
- spring web项目中整合netty, akka
spring web项目中整合netty, akka 本身的web项目仍然使用tomcat/jetty8080端口, 在org.springframework.beans.factory.Initia ...
- )ASCII比较大小
有一个注意点: 就是在字符输入时,要用getchar诋毁那个回车键 几个比较重要的error .听了学长的没有再用void main,结果结尾忘了return ,但是竟然也编译运行成功并提交了,ole ...
- 解密优秀博士成长史 ——微软亚洲研究院首届博士生学术论坛Panel讨论经验总结
--微软亚洲研究院首届博士生学术论坛Panel讨论经验总结" title="解密优秀博士成长史 --微软亚洲研究院首届博士生学术论坛Panel讨论经验总结"> 编者 ...
- sqlserver多表联查分页
select * from(select H_order.Id ,H_order.userID, ROW_NUMBER() over (order by H_order.Id Desc) as row ...
- 百度AI技术
利用百度提供接口,实现智能语音 语音合成 -- TTS(text to speech) 注册 在 ai.baidu.com 页面中点击 控制台 ,弹出登陆 / 注册页面 创建应用 登陆成功后,点击左侧 ...
- Android目录结构(详解)
Android目录结构(详解) 下面是HelloAndroid项目在eclipse中的目录层次结构: 由上图可以看出项目的根目录下共有九个文件(夹),下面就这九个文件(夹)进行详解: 1.1src文件 ...
- 公式化学习urllib(第一卷)
Import urllib.request 正常爬取网页: url=网址 +代表 下面测试一下: 结果我就不显示了 令html为读取后的对象 先用正则表达式抓取数据 Import re 令rule是抓 ...