吴裕雄 python 爬虫(1)
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm'
o = urlparse(url)
print(o) print("scheme={}".format(o.scheme)) # http
print("netloc={}".format(o.netloc)) # www.pm25x.com
print("port={}".format(o.port)) # None
print("path={}".format(o.path)) # /city/beijing.htm
print("query={}".format(o.query)) # 空

import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="GBK"
print(html.text)

import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="gbk" htmllist = html.text.splitlines()
n=0
for row in htmllist:
if "新概念" in row:
n+=1
print("找到 {} 次!".format(n))
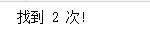
import re
pat = re.compile('[a-z]+') m = pat.match('tem12po')
print(m) if not m==None:
print(m.group())
print(m.start())
print(m.end())
print(m.span())

import re
m = re.match(r'[a-z]+','tem12po')
print(m) if not m==None:
print(m.group())
print(m.start())
print(m.end())
print(m.span())
import re
pat = re.compile('[a-z]+')
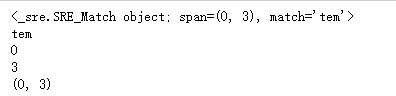
m = pat.search('3tem12po')
print(m) # <_sre.SRE_Match object; span=(1, 4), match='tem'>
if not m==None:
print(m.group()) # tem
print(m.start()) #
print(m.end()) #
print(m.span()) # (1,4)

import re
pat = re.compile('[a-z]+') m = pat.findall('tem12po')
print(m) # ['tem', 'po']
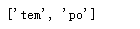
import requests,re
regex = re.compile('[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+')
url = 'http://www.wsbookshow.com/'
html = requests.get(url)
emails = regex.findall(html.text)
for email in emails:
print(email)

吴裕雄 python 爬虫(1)的更多相关文章
- 吴裕雄 python 爬虫(4)
import requests user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, li ...
- 吴裕雄 python 爬虫(3)
import hashlib md5 = hashlib.md5() md5.update(b'Test String') print(md5.hexdigest()) import hashlib ...
- 吴裕雄 python 爬虫(2)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com' html = requests.get(url) ...
- 吴裕雄--python学习笔记:爬虫基础
一.什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息. 二.Python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是调度器.URL管理器.网页下载器.网 ...
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- window系统更新导致很多服务出错
window7,win10,window server各版本系统中,经常会出现下载完成更新补丁后要求重启更新,此时很可能会出现很多服务失效的莫名其妙的问题,比如数据库连不上,IIS某功能不好使等等问题 ...
- Win7 发生验证错误 要求的函数不受支持
今天登陆服务器突然登不上了,给我报了一个错误“发生验证错误 要求的函数不受支持”,用同事的win7电脑和win10电脑都可以,就是我的不行,气死我了,然后我百度百度啊,用了好几种“说用了就OK”的办法 ...
- Django中的ORM相关操作:F查询,Q查询,事物,ORM执行原生SQL
一 F查询与Q查询: 1 . F查询: 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较.如果我们要对两个字段的值做比较,那该怎么做呢? Django 提供 F() 来做这样的 ...
- JVM总结-synchronized
在 Java 程序中,我们可以利用 synchronized 关键字来对程序进行加锁.它既可以用来声明一个 synchronized 代码块,也可以直接标记静态方法或者实例方法. 当声明 synchr ...
- 大小端,memcpy和构造函数
问题:memcpy一段内存到std::bitset里,bitset里的内存数据和被拷贝的内存数据对应不上 代码如下: #include <iostream> #include <bi ...
- 学生管理系统.c
直接贴代码了 另有:python调用c程序的实现 #define _CRT_SECURE_NO_WARNINGS #include<iostream> using namespace st ...
- hive执行报错:Both left and right aliases encountered in JOIN 's1'
原因:两个表join的时候,不支持两个表的字段 非相等 操作. 可以把不相等条件拿到 where语句中. 例如: right JOIN test.dim_month_date p2 on p1.mon ...
- mybatis二(参数处理和map封装及自定义resultMap)
.单个参数 mybatis不会做特殊处理. #{参数名/任意名}:取出参数值. .多个参数 mybatis会做特殊处理. 多个参数会被封装成 一个map. key:param1...paramN,或者 ...
- redis 做默认缓存
配置: server.port= # REDIS (RedisProperties) # Redis\u6570\u636E\u5E93\u7D22\u5F15\uFF08\u9ED8\u8BA4\u ...
- Mysql 预查询处理 事务机制
预处理 PDO支持sql预处理功能,可以有效的防止sql注入的问题 例如: 以下操作会导致数据表中所有数据删除 $host = 'localhost'; $port = 3306; $dbname = ...