tensorflow笔记(三)之 tensorboard的使用
tensorflow笔记(三)之 tensorboard的使用
版权声明:本文为博主原创文章,转载请指明转载地址
http://www.cnblogs.com/fydeblog/p/7429344.html
前言
这篇博客将介绍tensorflow当中一个非常有用的可视化工具tensorboard的使用,它将对我们分析训练效果,理解训练框架和优化算法有很大的帮助。
还记得我的第一篇tensorflow博客上的的例子吗?这篇博客会以第一篇tensorflow博客的tensorboard图为例进行展开。
我会把这篇博客的相关代码(代码也会贴在博客上,可以直接copy生成py文件用)和notebook放在文后的百度云链接上,欢迎下载!
1. 实践1--矩阵相乘
相应的代码
import tensorflow as tf
with tf.name_scope('graph') as scope:
matrix1 = tf.constant([[3., 3.]],name ='matrix1') #1 row by 2 column
matrix2 = tf.constant([[2.],[2.]],name ='matrix2') # 2 row by 1 column
product = tf.matmul(matrix1, matrix2,name='product')
sess = tf.Session()
writer = tf.summary.FileWriter("logs/", sess.graph)
init = tf.global_variables_initializer()
sess.run(init)
这里相对于第一篇tensorflow多了一点东西,tf.name_scope函数是作用域名,上述代码斯即在graph作用域op下,又有三个op(分别是matrix1,matrix2,product),用tf函数内部的name参数命名,这样会在tensorboard中显示,具体图像还请看下面。
很重要:运行上面的代码,查询当前目录,就可以找到一个新生成的文件,已命名为logs,我们需在终端上运行tensorboard,生成本地链接,具体看我截图,当然你也可以将上面的代码直接生成一个py文档在终端运行,也会在终端当前目录生成一个logs文件,然后运行tensorboard --logdir logs指令,就可以生成一个链接,复制那个链接,在google浏览器(我试过火狐也行)粘贴显示,对于tensorboard 中显示的网址打不开的朋友们, 请使用 http://localhost:6006 (如果这个没有成功,我之前没有安装tensorboard,也出现链接,但那个链接点开什么都没有,所以还有一种可能就是你没有安装tensorboard,使用pip install tensorboard安装tensorboard,python3用pip3 install tensorboard)
具体运行过程如下(中间的警告请忽略,我把上面的代码命名为1.py运行的)
可以看到最后一行出现了链接,复制那个链接,推荐用google浏览器打开(火狐我试过也行),也可以直接打开链接http://localhost:6006,这样更方便!
如果出现下图,则证明打开成功
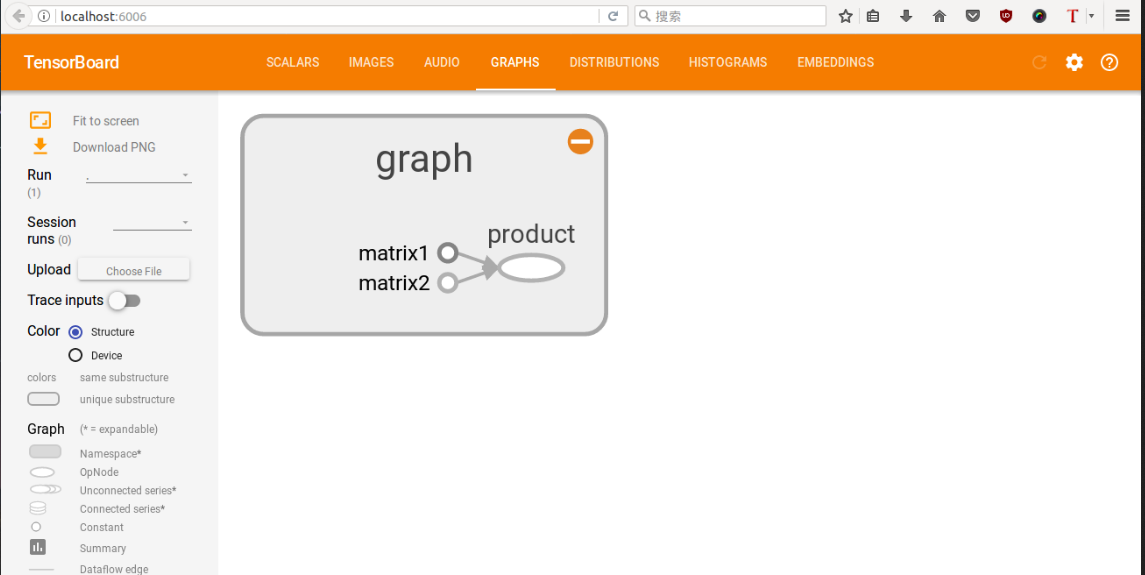
2. 实践2---线性拟合(一)
上面那一个是小试牛刀,比较简单,没有任何训练过程,下面将第一篇tensorflow笔记中的第二个例子来画出它的流动图(哦,对了,之所有说是流动图,这是由于tensorflow的名字就是张量在图形中流动的意思)
代码如下:(命名文件2.py)
import tensorflow as tf
import numpy as np ## prepare the original data
with tf.name_scope('data'):
x_data = np.random.rand(100).astype(np.float32)
y_data = 0.3*x_data+0.1
##creat parameters
with tf.name_scope('parameters'):
weight = tf.Variable(tf.random_uniform([1],-1.0,1.0))
bias = tf.Variable(tf.zeros([1]))
##get y_prediction
with tf.name_scope('y_prediction'):
y_prediction = weight*x_data+bias
##compute the loss
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.square(y_data-y_prediction))
##creat optimizer
optimizer = tf.train.GradientDescentOptimizer(0.5)
#creat train ,minimize the loss
with tf.name_scope('train'):
train = optimizer.minimize(loss)
#creat init
with tf.name_scope('init'):
init = tf.global_variables_initializer()
##creat a Session
sess = tf.Session()
##initialize
writer = tf.summary.FileWriter("logs/", sess.graph)
sess.run(init)
## Loop
for step in range(101):
sess.run(train)
if step %10==0 :
print step ,'weight:',sess.run(weight),'bias:',sess.run(bias)
运行这个程序会打印一些东西,看过第一篇tensorflow笔记的人应该知道
具体输出如下:

具体的运行过程如下图,跟第一个差不多
打开链接后,会出现下图
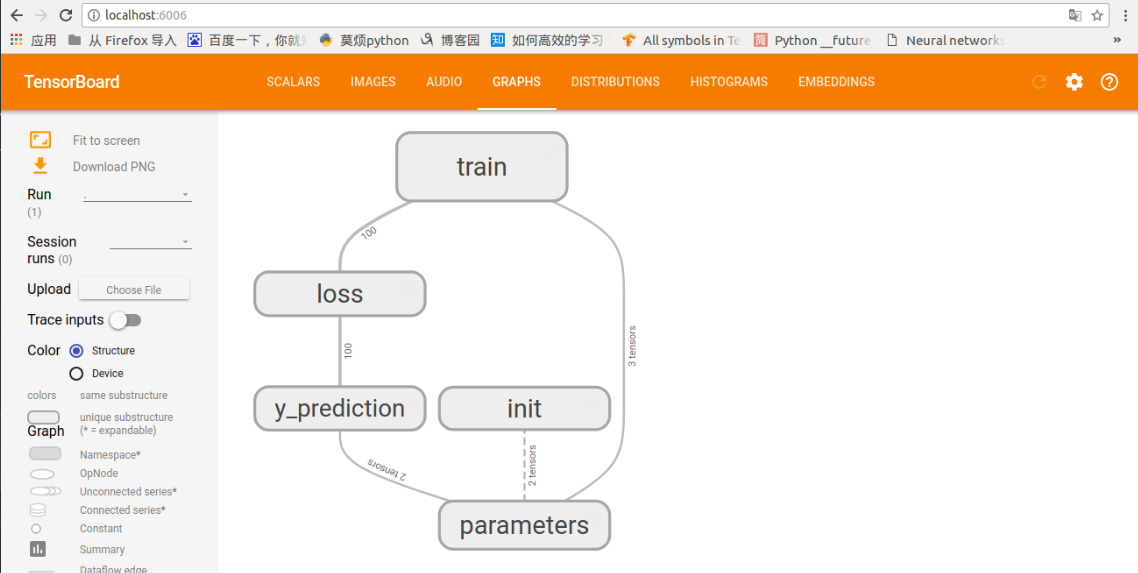
这个就是上面代码的流动图,先初始化参数,算出预测,计算损失,然后训练,更新相应的参数。
当然这个图还可以进行展开,里面有更详细的流动(截图无法全面,还请自己运行出看看哦)
Parameters部分

y_prediction部分和init部分
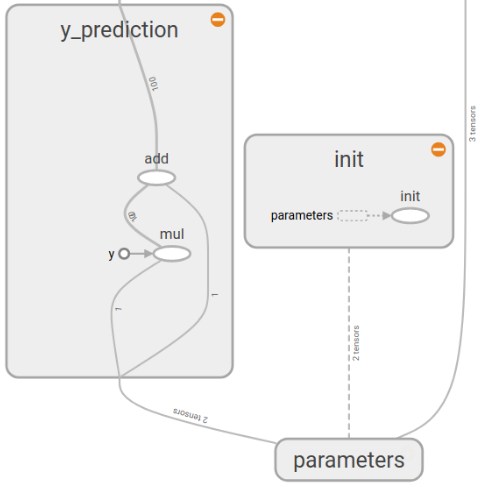
loss部分

还有最后的train部分
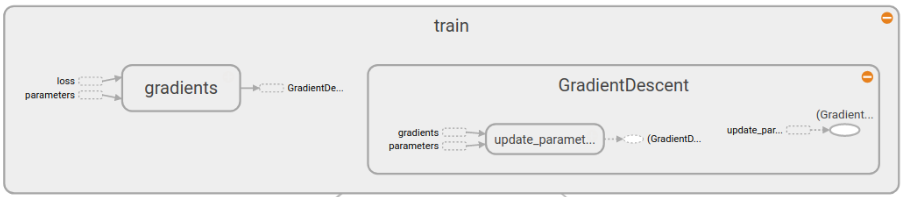
具体东西还请自己展开看看,不难理解
2. 实践2---线性拟合(二)
我们在对上面的代码进行再修改修改,试试tensorboard的其他功能,例如scalars,distributions,histograms,它们对我们分析学习算法的性能有很大帮助。
代码如下:(命名文件3.py)
import tensorflow as tf
import numpy as np ## prepare the original data
with tf.name_scope('data'):
x_data = np.random.rand(100).astype(np.float32)
y_data = 0.3*x_data+0.1
##creat parameters
with tf.name_scope('parameters'):
with tf.name_scope('weights'):
weight = tf.Variable(tf.random_uniform([1],-1.0,1.0))
tf.summary.histogram('weight',weight)
with tf.name_scope('biases'):
bias = tf.Variable(tf.zeros([1]))
tf.summary.histogram('bias',bias)
##get y_prediction
with tf.name_scope('y_prediction'):
y_prediction = weight*x_data+bias
##compute the loss
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.square(y_data-y_prediction))
tf.summary.scalar('loss',loss)
##creat optimizer
optimizer = tf.train.GradientDescentOptimizer(0.5)
#creat train ,minimize the loss
with tf.name_scope('train'):
train = optimizer.minimize(loss)
#creat init
with tf.name_scope('init'):
init = tf.global_variables_initializer()
##creat a Session
sess = tf.Session()
#merged
merged = tf.summary.merge_all()
##initialize
writer = tf.summary.FileWriter("logs/", sess.graph)
sess.run(init)
## Loop
for step in range(101):
sess.run(train)
rs=sess.run(merged)
writer.add_summary(rs, step)
闲麻烦,我把打印的去掉了,这里多了几个函数,tf.histogram(对应tensorboard中的scalar)和tf.scalar函数(对应tensorboard中的distribution和histogram)是制作变化图表的,两者差不多,使用方式可以参考上面代码,一般是第一项字符命名,第二项就是要记录的变量了,最后用tf.summary.merge_all对所有训练图进行合并打包,最后必须用sess.run一下打包的图,并添加相应的记录。
运行过程与上面两个一样
下面来看看tensorboard中的训练图吧
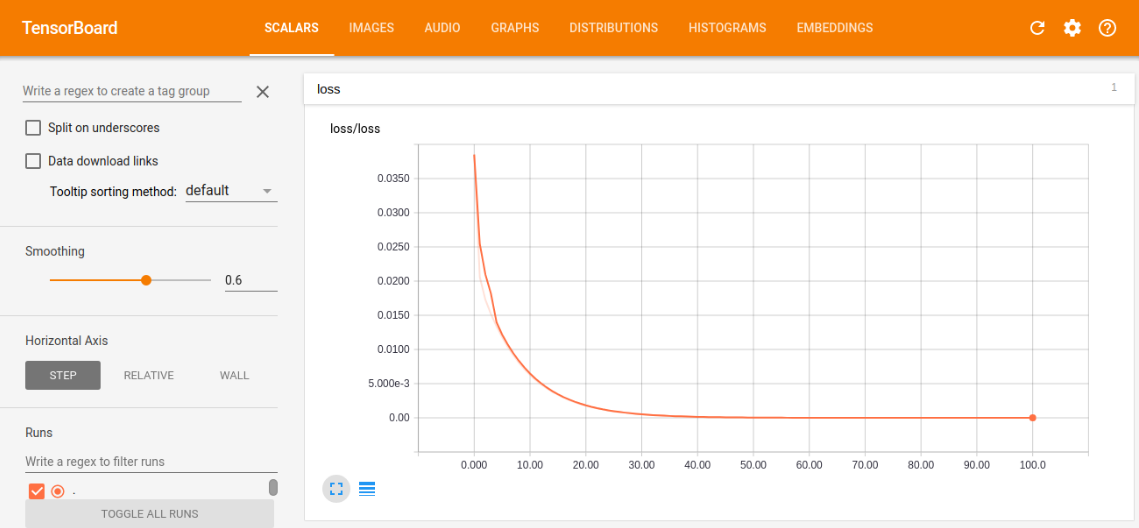
scalar中的loss训练图
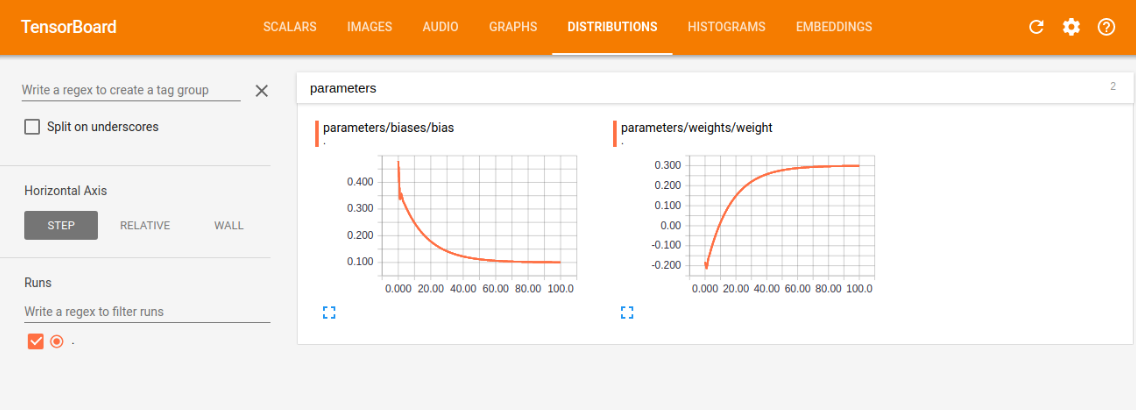
distribution中的weight和bias的训练图
histogram中的weight和bias的训练图
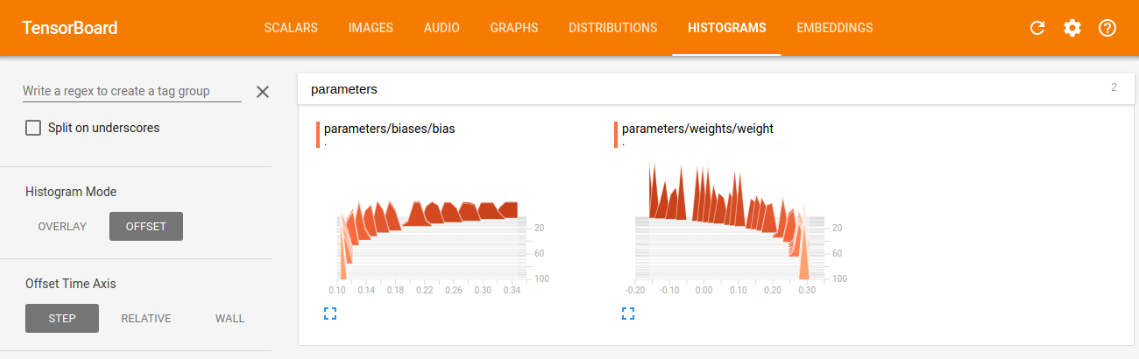
我们可以根据训练图,对学习情况进行评估,比如我们看损失训练图,可以看到现在是一条慢慢减小的曲线,最后的值趋近趋近于0(这里趋近于0是由于我选的模型太容易训练了,误差可以逼近0,同时又能很好的表征系统的模型,在现实情况,往往都有误差,趋近于0反而是过拟合),这符合本意,就是要最小化loss,如果loss的曲线最后没有平滑趋近一个数,则说明训练的力度还不够,还有加大次数,如果loss还很大,说明学习算法不太理想,需改变当前的算法,去实现更小的loss,另外两幅图与loss类似,最后都是要趋近一个数的,没有趋近和上下浮动都是有问题的。
结尾
tensorboard的博客结束了,我写的只是基础部分,更多东西还请看官方的文档和教程,希望这篇博客能对你学习tensorboard有帮助!
notebook链接: https://pan.baidu.com/s/1o8lzN1g 密码: mbv8
tensorflow笔记(三)之 tensorboard的使用的更多相关文章
- TensorFlow笔记三:从Minist数据集出发 两种经典训练方法
Minist数据集:MNIST_data 包含四个数据文件 一.方法一:经典方法 tf.matmul(X,w)+b import tensorflow as tf import numpy as np ...
- tensorflow笔记2:TensorBoard
Tensorboard中的参数 Summary:所有需要在TensorBoard上展示的统计结果. tf.name_scope():为Graph中的Tensor添加层级,TensorBoard会按照代 ...
- Tensorflow 笔记 -- tensorboard 的使用
Tensorflow 笔记 -- tensorboard 的使用 TensorFlow提供非常方便的可视化命令Tensorboard,先上代码 import tensorflow as tf a = ...
- tensorflow笔记(一)之基础知识
tensorflow笔记(一)之基础知识 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7399701.html 前言 这篇no ...
- tensorflow笔记:使用tf来实现word2vec
(一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 (四) tensorflow笔 ...
- tensorflow笔记:模型的保存与训练过程可视化
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- tensorflow笔记(二)之构造一个简单的神经网络
tensorflow笔记(二)之构造一个简单的神经网络 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7425200.html ...
- tensorflow笔记(四)之MNIST手写识别系列一
tensorflow笔记(四)之MNIST手写识别系列一 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7436310.html ...
- 【TensorFlow篇】--Tensorflow框架可视化之Tensorboard
一.前述 TensorBoard是tensorFlow中的可视化界面,可以清楚的看到数据的流向以及各种参数的变化,本文基于一个案例讲解TensorBoard的用法. 二.代码 设计一个MLP多层神经网 ...
随机推荐
- JavaScript一个鼠标滚动事件的实例
<script type="text/javascript" src="./whenReady.js"></script> <!- ...
- 事务之使用JDBC进行事务的操作
本篇讲述数据库中非常重要的事务概念和如何使用MySQL命令行窗口来进行数据库的事务操作.下一篇会讲述如何使用JDBC进行数据库的事务操作. 事务是指数据库中的一组逻辑操作,这个操作的特点就是在该组逻辑 ...
- Ambari安装之Ambari安装前准备(CentOS6.5)(一)
优秀博客 <Ambari--大数据平台的搭建利器> Ambari安装前准备 (一)机器准备 192.168.80.144 ambari01 (部署Ambari-server和Mirro ...
- MySQL系列(二)---MySQL事务
MySql 事务 目录 MySQL系列(一):基础知识大总结 MySQL系列(二):MySQL事务 什么是事务(transaction) 保证成批操作要么完全执行,要么完全不执行,维护数据的完整性.也 ...
- 一个爬取Bing每日壁纸的python脚本
1. 背景 Bing搜索每天的背景图片有些比较适合做桌面,但是有的提供下载有的不提供下载.每天去点击下载又不太方便,所以第一次学习了一下python爬虫怎么写,写的很简单. 2. 相关技术 2.1 P ...
- angular JS中使用jquery datatable添加ng-click事件
'use strict'; app.controller('DataTableCtrl', function ($scope, $compile) { $scope.show = function ( ...
- 快速搭建MySQL复制集
快速搭建MySQL复制集 1 环境说明 MySQL版本 5.6 basedir :/u01/my3306 #MySQL软件目录 数据目录 :/u01/mysql/[实例名]/data 日志目录 :/u ...
- <EffectiveJava>读书笔记--02泛型数组
1, java中可以申明泛型类型的数组引用; 2, 但是不能实例化一个泛型数组对象; 3, 针对第二点, 可以曲线救国, 实例化一个Object数组, 再进行类型强转; 见代码如下: public c ...
- ASP.NET-页面间的数据传递
暑假期间做项目时遇到相关问题,总结如下,与大家分享 1.通过查询字符串传递 这种方式是将参数附加在网址的后面,传递数据简单,但容易暴露,一般用于传递一些简单的数据. 例如,在Default1.aspx ...
- 报错:No identifier specified for entity: main.java.com.sy.entity.User的解决办法
自己也没怎么搭建过框架,更何况还是spring mvc的,最近在带两个实习生,正好教他们怎么搭建一个spring mvc的框架,然而我在映射表的时候,提示报错了. 实体基类: public class ...