Python 项目实践二(下载数据)第三篇
接着上节继续学习,在本章中,你将从网上下载数据,并对这些数据进行可视化。网上的数据多得难以置信,且大多未经过仔细检查。如果能够对这些数据进行分析,你就能发现别人没有发现的规律和关联。我们将访问并可视化以两种常见格式存储的数据:CSV和JSON。我们将使用Python模块csv来处理以CSV(逗号分隔的值)格式存储的天气数据,找出两个不同地区在一段时间内的最高温度和最低温度。然后,我们将使用matplotlib根据下载的数据创建一个图表,展示两个不同地区的气温变化:阿拉斯加锡特卡和加利福尼亚死亡谷。在本章的后面,我们将使用模块json来访问以JSON格式存储的人口数据,并使用Pygal绘制一幅按国别划分的人口地图。
一 CSV格式
要在文本文件中存储数据,最简单的方式是将数据作为一系列以逗号分隔的值(CSV)写入文件。这样的文件称为CSV文件。例如,下面是一行CSV格式的天气数据:
2014-1-5,61,44,26,18,7,-1,56,30,9,30.34,30.27,30.15,,,,10,4,,0.00,0,,195
二 分析CSV文件头
csv模块包含在Python标准库中,可用于分析CSV文件中的数据行,让我们能够快速提取感兴趣的值。下面先来查看这个文件的第一行,其中包含一系列有关数据的描述:
import csv
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f :
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
(1)调用csv.reader(),并将前面存储的文件对象作为实参传递给它,从而创建一个与该文件相关联的阅读器(reader)对象。我们将这个阅读器对象存储在reader中。
(2)模块csv包含函数next(),调用它并将阅读器对象传递给它时,它将返回文件中的下一行。在前面的代码中,我们只调用了next()一次,因此得到的是文件的第一行,
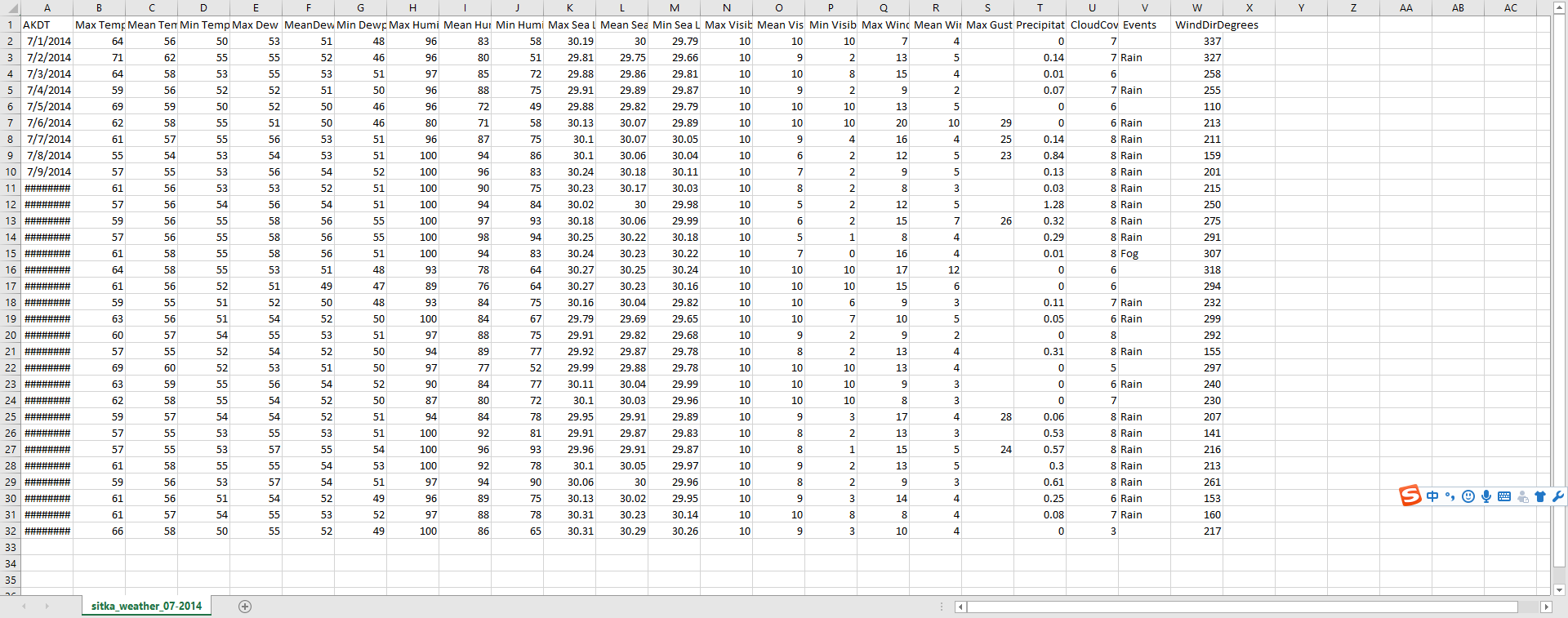
结果如下:['AKDT', 'Max TemperatureF', 'Mean TemperatureF', 'Min TemperatureF', 'Max Dew PointF', 'MeanDew PointF', 'Min DewpointF', 'Max Humidity', ' Mean Humidity', ' Min Humidity', ' Max Sea Level PressureIn', ' Mean Sea Level PressureIn', ' Min Sea Level PressureIn', ' Max VisibilityMiles', ' Mean VisibilityMiles', ' Min VisibilityMiles', ' Max Wind SpeedMPH', ' Mean Wind SpeedMPH', ' Max Gust SpeedMPH', 'PrecipitationIn', ' CloudCover', ' Events', ' WindDirDegrees']
这个csv文件时这样的。
三 打印头文件以及其位置
为让文件头数据更容易理解,将列表中的每个文件头及其位置打印出来:
import csv
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f :
reader = csv.reader(f)
header_row = next(reader)
for index,column_header in enumerate(header_row):
print(index,column_header)
结果如下:

四 提取并读取数据
知道需要哪些列中的数据后,我们来读取一些数据。首先读取每天的最高气温:
import csv
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f :
reader = csv.reader(f)
header_row = next(reader)
#for index,column_header in enumerate(header_row):
# print(index,column_header)
highs=[]
for row in reader :
high = int(row[1])
highs.append(high)
print(highs)
结果如下图:
[64, 71, 64, 59, 69, 62, 61, 55, 57, 61, 57, 59, 57, 61, 64, 61, 59, 63, 60, 57, 69, 63, 62, 59, 57, 57, 61, 59, 61, 61, 66]
五 绘制气温图标
import csv
from matplotlib import pyplot as plt
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f :
reader = csv.reader(f)
header_row = next(reader)
#for index,column_header in enumerate(header_row):
# print(index,column_header)
highs=[]
for row in reader :
high = int(row[1])
highs.append(high)
print(highs)
fig = plt.figure(dpi=128,figsize=(10,6))
plt.plot(highs,c="red")
#设置图形的格式
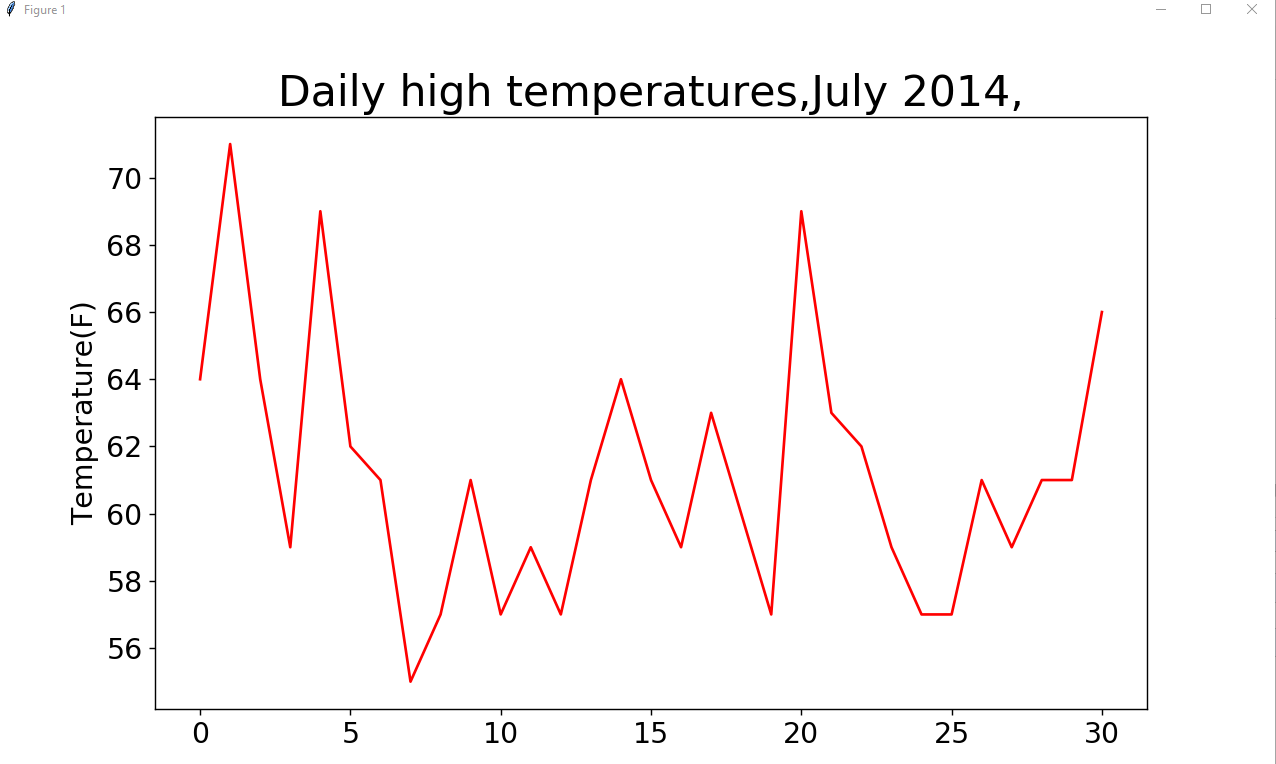
plt.title("Daily high temperatures,July 2014,", fontsize=24)
plt.xlabel("",fontsize=16)
plt.ylabel("Temperature(F)",fontsize=16)
plt.tick_params(axis="both",which ="major",labelsize=16)
plt.show()
结果如下图:
六 模块datetime
首先导入了模块datetime中的datetime类,然后调用方法strptime(),并将包含所需日期的字符串作为第一个实参。第二个实参告诉Python如何设置日期的格式。在这个示例中,'%Y-'让Python将字符串中第一个连字符前面的部分视为四位的年份;'%m-'让Python将第二个连字符前面的部分视为表示月份的数字;而'%d'让Python将字符串的最后一部分视为月份中的一天(1~31)。
方法strptime()可接受各种实参,并根据它们来决定如何解读日期。一下列出了其中一些这样的实参:

七 在图表中添加日期
知道如何处理CSV文件中的日期后,就可对气温图形进行改进了,即提取日期和最高气温,并将它们传递给plot(),如下所示:
import csv
from matplotlib import pyplot as plt
from datetime import datetime
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f :
reader = csv.reader(f)
header_row = next(reader)
#for index,column_header in enumerate(header_row):
# print(index,column_header)
#从文件中获取日期和最高气温
dates,highs=[],[]
for row in reader :
current_date = datetime.strptime(row[0],"%m/%d/%Y")
dates.append(current_date)
high = int(row[1])
highs.append(high)
print(highs)
fig = plt.figure(dpi=128,figsize=(10,6))
plt.plot(dates,highs,c="red")
#设置图形的格式
plt.title("Daily high temperatures,July 2014,", fontsize=24)
plt.xlabel("",fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)",fontsize=16)
plt.tick_params(axis="both",which ="major",labelsize=16)
plt.show()
我们创建了两个空列表,用于存储从文件中提取的日期和最高气温(见)。然后,我们将包含日期信息的数据(row[0])转换为datetime对象,并将其附加到列表dates末尾。我们将日期和最高气温值传递给plot()。我们调用了fig.autofmt_xdate()来绘制斜的日期标签,以免它们彼此重叠。下图显示了改进后的图表。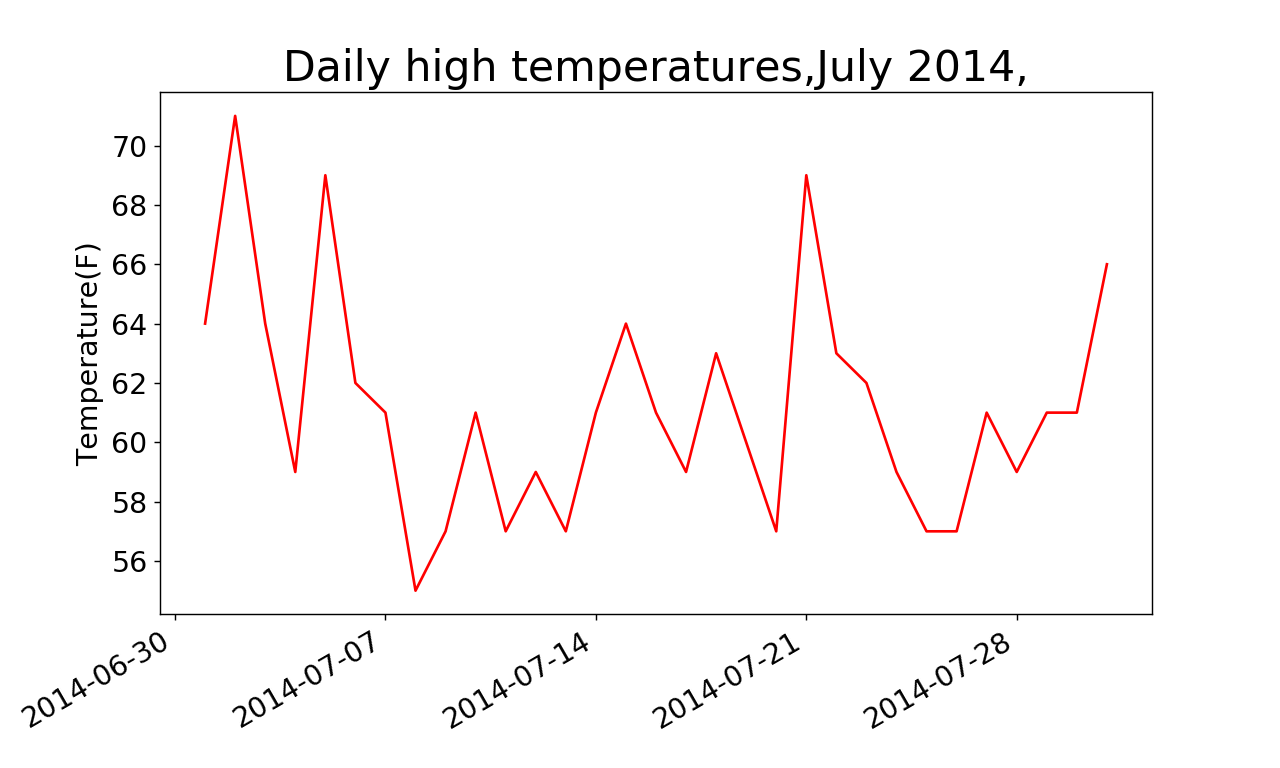
八 再绘制一个数据系列
改进后的图表显示了大量意义深远的数据,但我们可以在其中再添加最低气温数据,使其更有用。为此需要从数据文件中提取最低气温,并将它们添加到图表中,如下所示:
import csv
from matplotlib import pyplot as plt
from datetime import datetime
filename = 'sitka_weather_2014.csv'
with open(filename) as f :
reader = csv.reader(f)
header_row = next(reader)
#for index,column_header in enumerate(header_row):
# print(index,column_header)
#从文件中获取日期和最高气温,最低气温
dates,highs,lows=[],[],[]
for row in reader :
current_date = datetime.strptime(row[0],"%Y-%m-%d")
dates.append(current_date)
low=int(row[3])
lows.append(low)
high = int(row[1])
highs.append(high)
# print(highs)
fig = plt.figure(dpi=128,figsize=(10,6))
plt.plot(dates,highs,c="red")
plt.plot(dates,lows,c="blue")
#设置图形的格式
plt.title("Daily high temperatures - 2014,", fontsize=24)
plt.xlabel("",fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)",fontsize=16)
plt.tick_params(axis="both",which ="major",labelsize=16)
plt.show()
效果图如下:

九 给图标区域着色
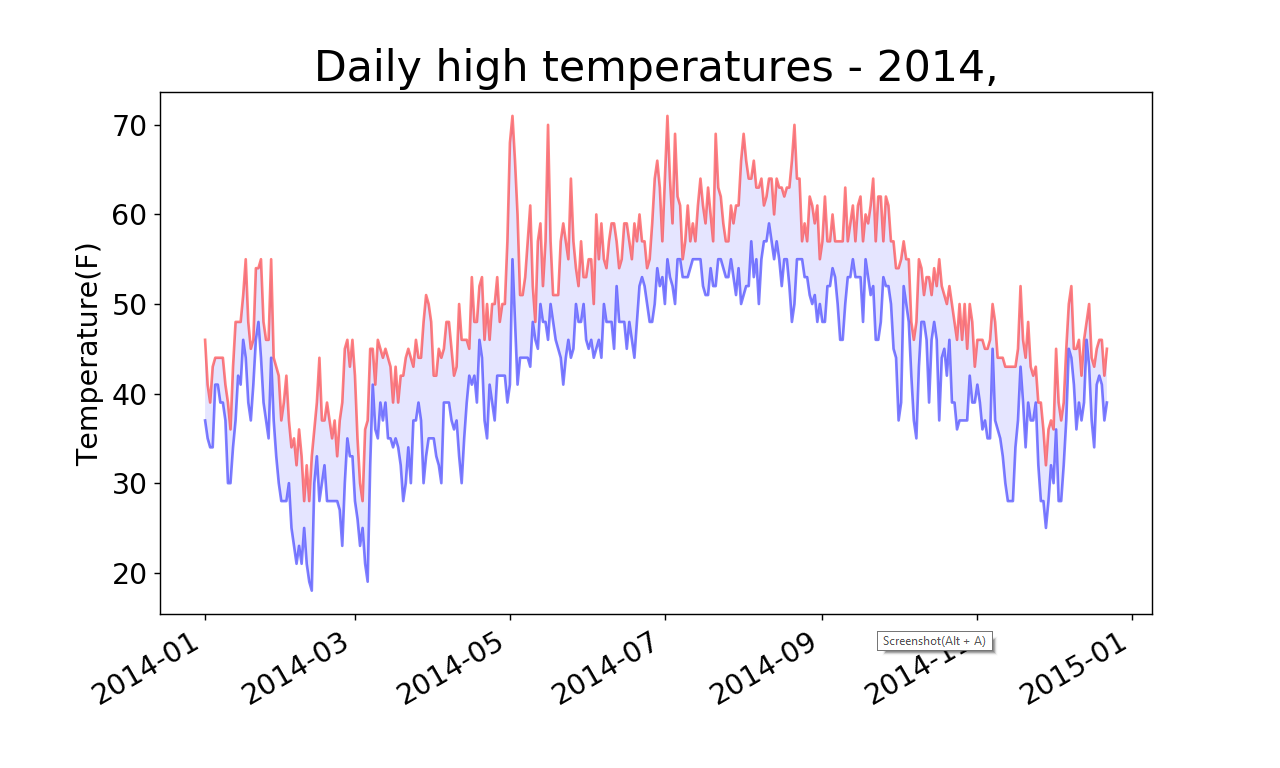
添加两个数据系列后,我们就可以了解每天的气温范围了。下面来给这个图表做最后的修饰,通过着色来呈现每天的气温范围。为此,我们将使用方法fill_between(),它接受一个x值系列和两个y值系列,并填充两个y值系列之间的空间:
plt.plot(dates,highs,c="red",alpha=0.5) plt.plot(dates,lows,c="blue",alpha=0.5) plt.fill_between(dates,highs,lows,facecolor="blue",alpha=0.1)
(1)实参alpha指定颜色的透明度。Alpha值为0表示完全透明,1(默认设置)表示完全不透明。通过将alpha设置为0.5,可让红色和蓝色折线的颜色看起来更浅。
(2)我们向fill_between()传递了一个x值系列:列表dates,还传递了两个y值系列:highs和lows。
(3)实参facecolor指定了填充区域的颜色,我们还将alpha设置成了较小的值0.1,让填充区域将两个数据系列连接起来的同时不分散观察者的注意力。
(4)显示了最高气温和最低气温之间的区域被填充的图表如下:
未完待续!元旦三天小长假已经来了,祝大家元旦快乐!
Python 项目实践二(下载数据)第三篇的更多相关文章
- Python 项目实践二(生成数据)第二篇之随机漫步
接着上节继续学习,在本节中,我们将使用Python来生成随机漫步数据,再使用matplotlib以引人瞩目的方式将这些数据呈现出来.随机漫步是这样行走得到的路径:每次行走都完全是随机的,没有明确的方向 ...
- Python 项目实践二(生成数据)第二篇
接着上节继续学习,在本节中,我们将使用Python来生成随机漫步数据,再使用matplotlib以引人瞩目的方式将这些数据呈现出来.随机漫步是这样行走得到的路径:每次行走都完全是随机的,没有明确的方向 ...
- Python 项目实践二(生成数据)第一篇
上面那个小游戏教程写不下去了,以后再写吧,今天学点新东西,了解的越多,发现python越强大啊! 数据可视化指的是通过可视化表示来探索数据,它与数据挖掘紧密相关,而数据挖掘指的是使用代码来探索数据集的 ...
- Python 项目实践二(下载数据)第四篇
接着上节继续学习,在本节中,你将下载JSON格式的人口数据,并使用json模块来处理它们.Pygal提供了一个适合初学者使用的地图创建工具,你将使用它来对人口数据进行可视化,以探索全球人口的分布情况. ...
- Python 项目实践一(外星人入侵)第一篇
python断断续续的学了一段实践,基础课程终于看完了,现在跟着做三个小项目,第一个是外星人入侵的小游戏: 一 Pygame pygame 是一组功能强大而有趣的模块,可用于管理图形,动画乃至声音,让 ...
- Python 项目实践一(外星人入侵)第二篇
接着上次的继续学习. 一 创建一个设置类 每次给游戏添加新功能时,通常也将引入一些新设置.下面来编写一个名为settings的模块,其中包含一个名为Settings的类,用于将所有设置存储在一个地方, ...
- MySQL行(记录)的详细操作一 介绍 二 插入数据INSERT 三 更新数据UPDATE 四 删除数据DELETE 五 查询数据SELECT 六 权限管理
MySQL行(记录)的详细操作 阅读目录 一 介绍 二 插入数据INSERT 三 更新数据UPDATE 四 删除数据DELETE 五 查询数据SELECT 六 权限管理 一 介绍 MySQL数据操作: ...
- [转]ionic项目之上传下载数据
本文转自:http://blog.csdn.net/superjunjin/article/details/44158567 一,首先是上传数据 记得在angularjs的controller中注入$ ...
- windows使用python调用wget批处理下载数据
wget是linux/unix下通常使用的下载http/ftp的数据,使用非常方便,其实wget目前经过编译,也可在windows下使用.最近需要下载大量的遥感数据,使用了python写了批处理下载程 ...
随机推荐
- 用Python写一款属于自己的 简易zip压缩软件 附完成图(适合初学者)
一.软件描述 用Python tkinter模块写一款属于自己的压缩软件.zip文件格式是通用的文档压缩标准,在ziplib模块中,使用ZipFile来操作zip文件,具有功能:zip压缩功能,zip ...
- JQuery之事件冒泡
JQuery 提供了两种方式来阻止事件冒泡. 方法一:event.stopPropagation(); $("#div1").mousedown(function(event){ ...
- 二、Hadoop学习笔记————架构学习
1.成百上千台服务器组成集群,需要时刻检测服务器是否故障 2.用流读取数据更加高效快速 3.存储节点具有运算功能,省略了服务器之间来回传数据的网络带宽限制 4.一次写入,多次访问,不修改数据 5.多平 ...
- jsp运行原理及运行过程
JSP的执行过程主要可以分为以下几点: 1)客户端发出请求. 2)Web容器将JSP转译成Servlet源代码. 3)Web容器将产生的源代码进行编译. 4)Web容器加载编译后的代码并执行. 5)把 ...
- CentOS环境下Docker私有仓库搭建
本文讲述如何搭建docker私有仓库. 有了docker hub,为什么还要搭建docker私有仓库? 1.性能考虑:docker hub的访问要通过互联网,性能太低. 2.安全性:更多的时候,镜像不 ...
- 调用支付宝第三方接口(沙箱环境) SpringMVC+Maven
一.蚂蚁金服开放平台的操作 网址:https://open.alipay.com/platform/home.htm 支付宝扫码登陆
- Python 串口通信操作
下载 pyserial包 https://pypi.python.org/packages/source/p/pyserial/pyserial-2.7.tar.gz#md5=794506184df ...
- 【微服务】之五:轻松搞定SpringCloud微服务-调用远程组件Feign
上一篇文章讲到了负载均衡在Spring Cloud体系中的体现,其实Spring Cloud是提供了多种客户端调用的组件,各个微服务都是以HTTP接口的形式暴露自身服务的,因此在调用远程服务时就必须使 ...
- 第六届河南省赛 River Crossing 简单DP
1488: River Crossing Time Limit: 1 Sec Memory Limit: 128 MB Submit: 83 Solved: 42 SubmitStatusWeb ...
- CDH集群搭建部署
1. 硬件准备 使用了五台机器,其中两台8c16g,三台4c8g.一台4c8g用于搭建cmServer和NFS服务端,另外4台作为cloudera-manager agent部署CDH集群. ...