深度学习Trick——用权重约束减轻深层网络过拟合|附(Keras)实现代码
在深度学习中,批量归一化(batch normalization)以及对损失函数加一些正则项这两类方法,一般可以提升模型的性能。这两类方法基本上都属于权重约束,用于减少深度学习神经网络模型对训练数据的过拟合,并改善模型对新数据的性能。
目前,存在多种类型的权重约束方法,例如最大化或单位向量归一化,有些方法也必须需要配置超参数。
在本教程中,使用Keras API,用于向深度学习神经网络模型添加权重约束以减少过拟合。
完成本教程后,您将了解:
- 如何使用Keras API创建向量范数约束;
- 如何使用Keras API为MLP、CNN和RNN层添加权重约束;
- 如何通过向现有模型添加权重约束来减少过度拟合;
下面,让我们开始吧。

本教程分为三个部分:
- Keras中的权重约束;
- 图层上的权重约束;
- 权重约束案例研究;
Keras中权重约束
Keras API支持权重约束,且约束可以按每层指定。
使用约束通常涉及在图层上为输入权重设置kernel_constraint参数,偏差权重设置为bias_constraint。通常,权重约束方法不涉及偏差权重。
一组不同的向量规范在keras.constraints模块可以用作约束:
- 最大范数(max_norm):强制权重等于或低于给定限制;
- 非负规范(non_neg):强制权重为正数;
- 单位范数(unit_norm):强制权重为1.0;
- Min-Max范数(min_max_norm):强制权重在一个范围之间;
例如,可以导入和实例化约束:
# import norm
from keras.constraints import max_norm
# instantiate norm
norm = max_norm(3.0)图层上的权重约束
权重规范可用于Keras的大多数层,下面介绍一些常见的例子:
MLP权重约束
下面的示例是在全连接层上设置最大范数权重约束:
# example of max norm on a dense layer
from keras.layers import Dense
from keras.constraints import max_norm
...
model.add(Dense(32, kernel_constraint=max_norm(3), bias_constraint==max_norm(3)))
...CNN权重约束
下面的示例是在卷积层上设置最大范数权重约束:
# example of max norm on a cnn layer
from keras.layers import Conv2D
from keras.constraints import max_norm
...
model.add(Conv2D(32, (3,3), kernel_constraint=max_norm(3), bias_constraint==max_norm(3)))
...RNN权重约束
与其他图层类型不同,递归神经网络允许我们对输入权重和偏差以及循环输入权重设置权重约束。通过图层的recurrent_constraint参数设置递归权重的约束。
下面的示例是在LSTM图层上设置最大范数权重约束:
# example of max norm on an lstm layer
from keras.layers import LSTM
from keras.constraints import max_norm
...
model.add(LSTM(32, kernel_constraint=max_norm(3), recurrent_constraint=max_norm(3), bias_constraint==max_norm(3)))
...基于以上的基本知识,下面进行实例实践。
权重约束案例研究
在本节中,将演示如何使用权重约束来减少MLP对简单二元分类问题的过拟合问题。
此示例只是提供了一个模板,读者可以举一反三,将权重约束应用于自己的神经网络以进行分类和回归问题。
二分类问题
使用标准二进制分类问题来定义两个半圆观察,每个类一个半圆。其中,每个观测值都有两个输入变量,它们具有相同的比例,输出值分别为0或1,该数据集也被称为“ 月亮”数据集,这是由于绘制时,每个类中出现组成的形状类似于月亮。
可以使用make_moons()函数生成观察结果,设置参数为添加噪声、随机关闭,以便每次运行代码时生成相同的样本。
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)可以在图表上绘制两个变量x和y坐标,并将数据点所属的类别的颜色作为观察的颜色。
下面列出生成数据集并绘制数据集的完整示例:
# generate two moons dataset
from sklearn.datasets import make_moons
from matplotlib import pyplot
from pandas import DataFrame
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# scatter plot, dots colored by class value
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))
colors = {0:'red', 1:'blue'}
fig, ax = pyplot.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
pyplot.show()运行该示例会创建一个散点图,可以从图中看到,对应类别显示的图像类似于半圆形或月亮形状。
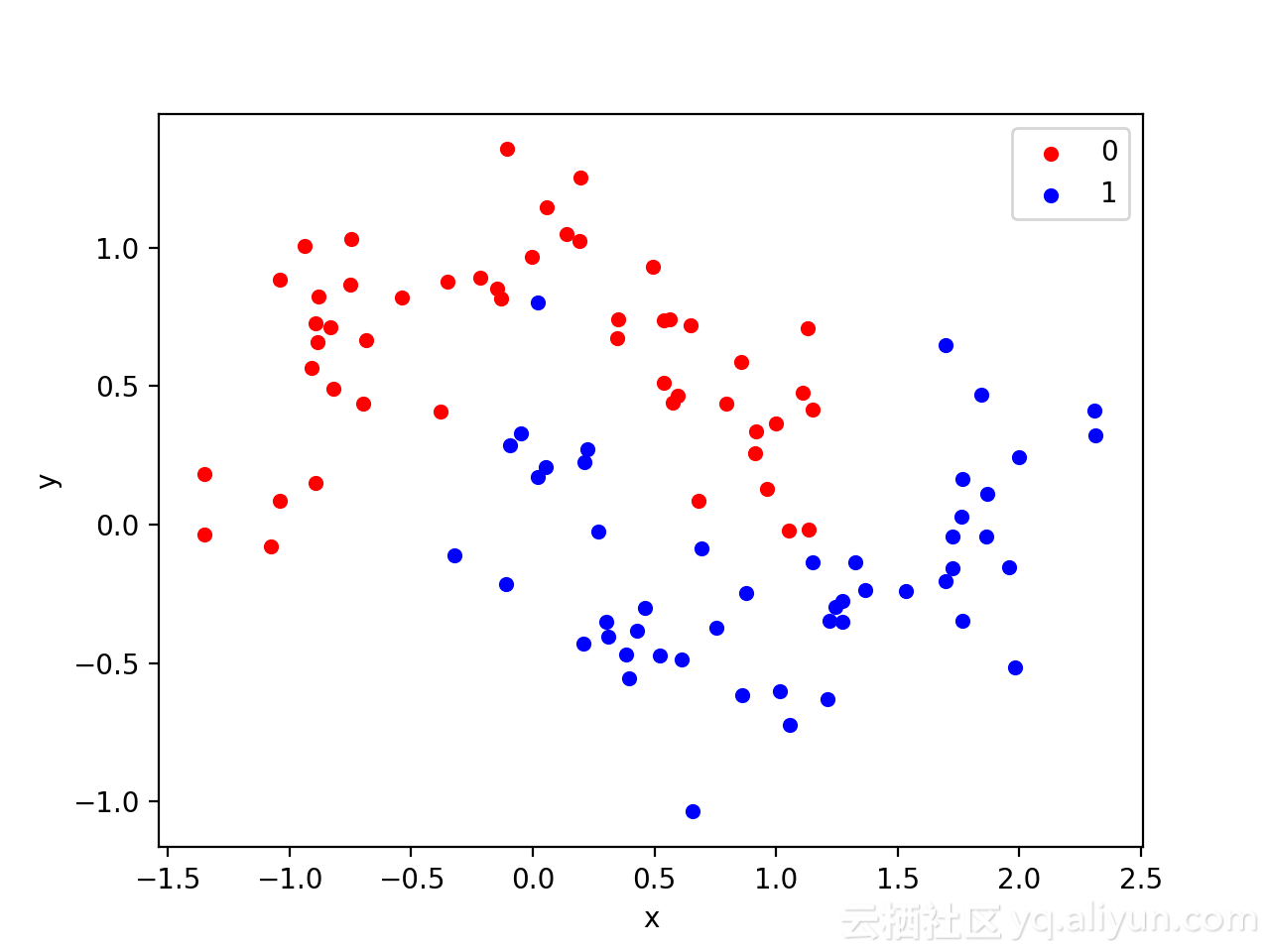
上图的数据集表明它是一个很好的测试问题,因为不能用直线划分,需要非线性方法,比如神经网络来解决。
只生成了100个样本,这对于神经网络而言较小,也提供了过拟合训练数据集的概率,并且在测试数据集上具有更高的误差。因此,也是应用正则化的一个好例子。此外,样本具有噪声,使模型有机会学习不一致的样本的各个方面。
多层感知器过拟合
在机器学习力,MLP模型可以解决这类二进制分类问题。
MLP模型只具有一个隐藏层,但具有比解决该问题所需的节点更多的节点,从而提供过拟合的可能。
在定义模型之前,需要将数据集拆分为训练集和测试集,按照3:7的比例将数据集划分为训练集和测试集。
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]接下来,定义模型。隐藏层的节点数设置为500、激活函数为RELU,但在输出层中使用Sigmoid激活函数以预测输出类别为0或1。
该模型使用二元交叉熵损失函数进行优化,这类激活函数适用于二元分类问题和Adam版本梯度下降方法。
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])然后,设置迭代次数为4,000次,默认批量训练样本数量为32。
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)这里将测试数据集作为验证数据集验证算法的性能:
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))最后,绘制出模型每个时期在训练和测试集上性能。如果模型确实对训练数据集过拟合了,对应绘制的曲线将会看到,模型在训练集上的准确度继续增加,而测试集上的性能是先上升,之后下降。
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()将以上过程组合在一起,列出完整示例:
# mlp overfit on the moons dataset
from sklearn.datasets import make_moons
from keras.layers import Dense
from keras.models import Sequential
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()运行该示例,给出模型在训练数据集和测试数据集上的性能。
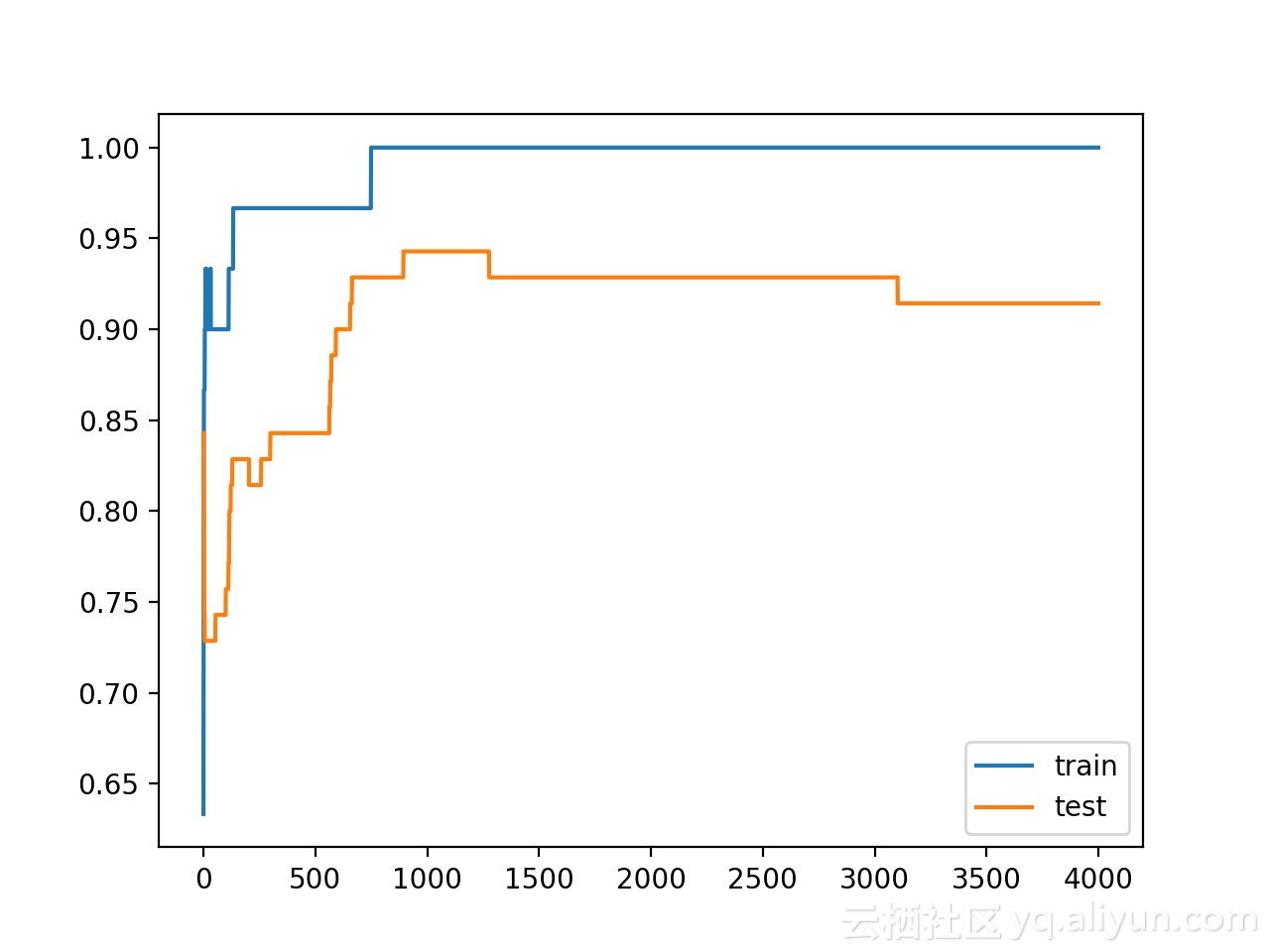
可以看到模型在训练数据集上的性能优于测试数据集,这是发生过拟合的标志。鉴于神经网络和训练算法的随机性,每次仿真的具体结果可能会有所不同。因为模型是过拟合的,所以通常不会期望在相同数据集上能够重复运行得到相同的精度。
Train: 1.000, Test: 0.914创建一个图,显示训练和测试集上模型精度的线图。从图中可以看到模型过拟合时的预期形状,其中测试精度达到一个临界点后再次开始减小。
具有权重约束的多层感知器过拟合
为了和上面做对比,现在对MLP使用权重约束。目前,有一些不同的权重约束方法可供选择。本文选用一个简单且好用的约束——简单地标准化权重,使得其范数等于1.0,此约束具有强制所有传入权重变小的效果。
在Keras中可以通过使用unit_norm来实现,并且将此约束添加到第一个隐藏层,如下所示:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=unit_norm()))此外,也可以通过使用min_max_norm并将min和maximum设置为1.0 来实现相同的结果,例如:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=min_max_norm(min_value=1.0, max_value=1.0)))但是无法通过最大范数约束获得相同的结果,因为它允许规范等于或低于指定的限制; 例如:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=max_norm(1.0)))下面列出具有单位规范约束的完整代码:
# mlp overfit on the moons dataset with a unit norm constraint
from sklearn.datasets import make_moons
from keras.layers import Dense
from keras.models import Sequential
from keras.constraints import unit_norm
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=unit_norm()))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()运行该示例,给出模型在训练数据集和测试数据集上的性能。
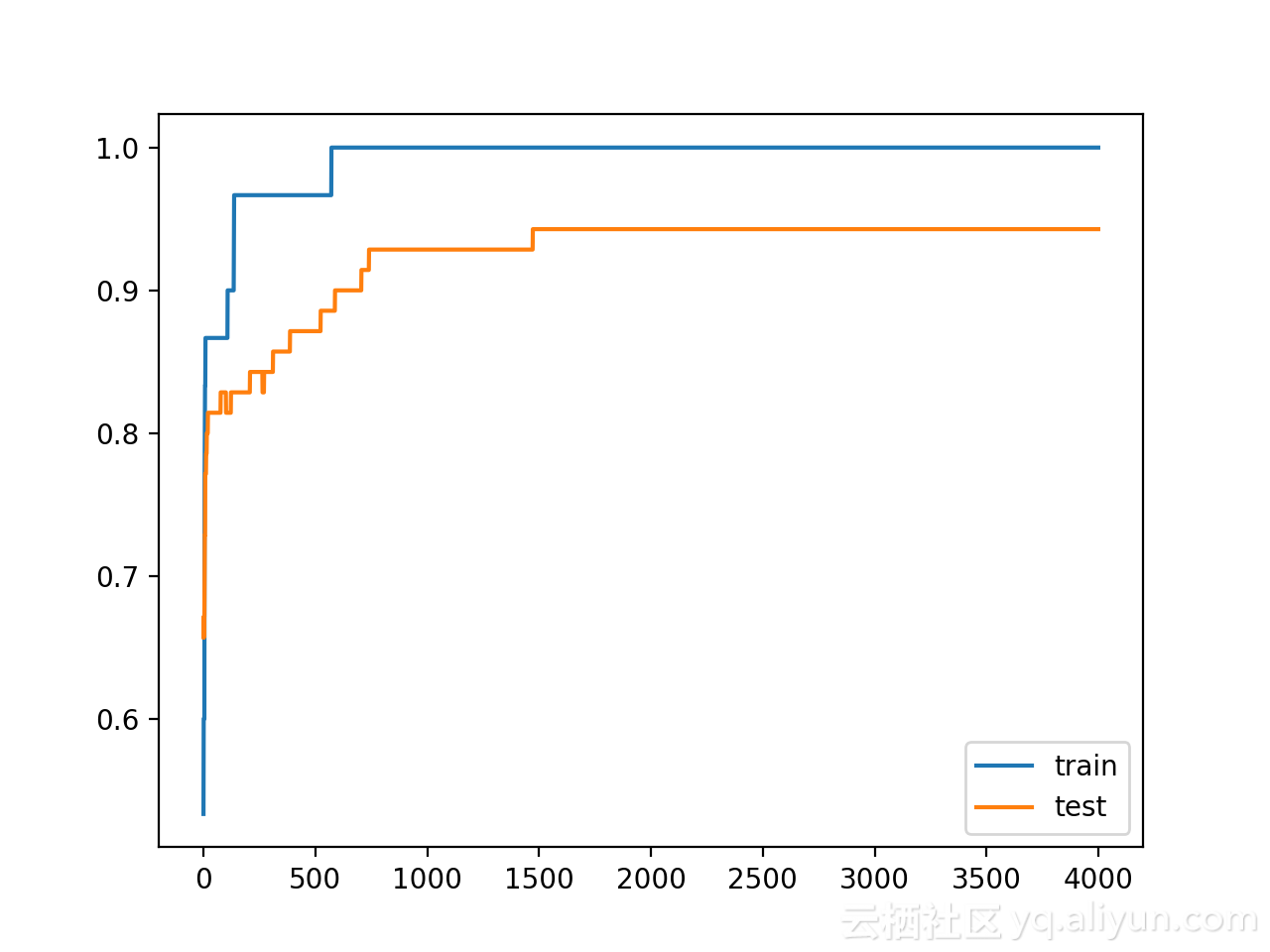
从下图可以看到,对权重进行严格约束确实提高了模型在验证集上的性能,并且不会影响训练集的性能。
Train: 1.000, Test: 0.943从训练和测试精度曲线图来看,模型已经在训练数据集上不再过拟合了,且模型在训练和测试数据集的精度保持在一个稳定的水平。
扩展
本节列出了一些读者可能希望探索扩展的教程:
- 报告权重标准:更新示例以计算网络权重的大小,并证明使用约束后,确实使得幅度更小;
- 约束输出层:更新示例以将约束添加到模型的输出层并比较结果;
- 约束偏置:更新示例以向偏差权重添加约束并比较结果;
- 反复评估:更新示例以多次拟合和评估模型,并报告模型性能的均值和标准差;
原文链接
本文为云栖社区原创内容,未经允许不得转载。
深度学习Trick——用权重约束减轻深层网络过拟合|附(Keras)实现代码的更多相关文章
- 深度学习框架比较TensorFlow、Theano、Caffe、SciKit-learn、Keras
TheanoTheano在深度学习框架中是祖师级的存在.Theano基于Python语言开发的,是一个擅长处理多维数组的库,这一点和numpy很像.当与其他深度学习库结合起来,它十分适合数据探索.它为 ...
- 深度学习环境搭建(CUDA9.0 + cudnn-9.0-linux-x64-v7 + tensorflow_gpu-1.8.0 + keras)
关于计算机的硬件配置说明 推荐配置 如果您是高校学生或者高级研究人员,并且实验室或者个人资金充沛,建议您采用如下配置: 主板:X299型号或Z270型号 CPU: i7-6950X或i7-7700K ...
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- 吴恩达深度学习笔记(八) —— ResNets残差网络
(很好的博客:残差网络ResNet笔记) 主要内容: 一.深层神经网络的优点和缺陷 二.残差网络的引入 三.残差网络的可行性 四.identity block 和 convolutional bloc ...
- 深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.contrib.rnn.MultiRNNCell(堆叠多层LSTM) 4.mlstm_cell.zero_state(state初始化) 5.mlstm_cell(进行LSTM求解)
问题:LSTM的输出值output和state是否是一样的 1. rnn.LSTMCell(num_hidden, reuse=tf.get_variable_scope().reuse) # 构建 ...
- 深度学习(六十二)SqueezeNet网络设计思想笔记
- 【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看 先分析网站内容,红色部分即是网站文章内容div,可以看 ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面 听课笔记
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
随机推荐
- 利用Python生成GIF动图
一.PIL库 1.PIL库的概括: PIL(Python Image Library)是python的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是python官方图像处理库 ...
- http post 请求详解
一步一步了解http post 请求 (大白话版). 1.创建一 个 CloseableHttpClient 对象 CloseableHttpClient client = HttpClients. ...
- C#HTTP请求之POST请求和GET请求
POST请求 /// <summary> /// POST请求获取信息 /// </summary> /// <param name="url"> ...
- Android Stdio的问题
昨天还是可以运行的,今天运行Android Studio,一直提示:Error running app: Instant Run requires 'Tools | android | Enable ...
- 解决windows server在关闭远程桌面后开启的服务也随之关闭的问题
首先远程登录服务器,关闭所有tomcat进程以及所有java进程,使用 netstat命令检查tomcat端口是否仍在监听状态,如仍在监听,使用taskkill杀死进程, 接下来关闭系统tomcat服 ...
- maven 项目快速下载jar方式
maven仓库默认在国外,使用难免很慢,尤其是下载依赖的时候,换为国内镜像,让你感受飞一般的感觉.国内支持maven镜像的有阿里云,开源中国等,这里换为阿里云的. 修改maven配置文件setting ...
- 安全圈玩起了直播,"学霸”带你玩转CTF
[i春秋]安全圈玩起了直播,"学霸”带你玩转CTF 跟着学霸(汪神)打CTF,摸清CTF套路 汪神,是浙江大学电气工程系的“风云人物”,曾因首度破解特斯拉汽车安全系统而名声大噪.本套题目是自 ...
- C++ 基础知识回顾总结
一.前言 为啥要写这篇博客?答:之前学习的C和C++相关的知识,早就被自己忘到一边去了.但是,随着音视频的学习的不断深入,和C/C++打交道的次数越来越多,看代码是没问题的,但是真到自己操刀去写一些代 ...
- Android 图片高级绘图效果---高斯模糊
高斯模糊就是将指定像素变换为其与周边像素加权平均后的值,权重就是高斯分布函数计算出来的值.高斯模糊能够将图片制作成类似磨砂的图片效果,一般这些图片都用来作为背景. 目前使用到的是RenderScrip ...
- CentOS7设置固定IP
在安装完CentOS7后,当我每次启动CentOS并使用SecureCRT链接时,都发现CentOS的IP总是在变,这就很苦恼了,总不能每次链接的时候都先查一下虚拟机的IP吧,所以打算把它设置成固定I ...