大数据专栏 - 基础1 Hadoop安装配置
Hadoop安装配置
环境
1, JDK8 --> 位置: /opt/jdk8
2, Hadoop2.10: --> 位置: /opt/bigdata/hadoop210
3, CentOS 7虚拟机试验集群规划
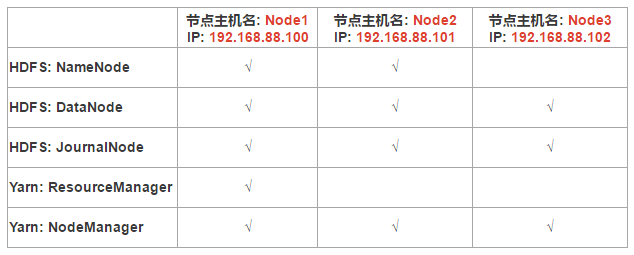
一,安装步骤
1, 解压缩
cd /opt/bigdata
tar -zxvf hadoop-2.10.1.tar.gz
mv ./hadoop-2.10.1 hadoop210
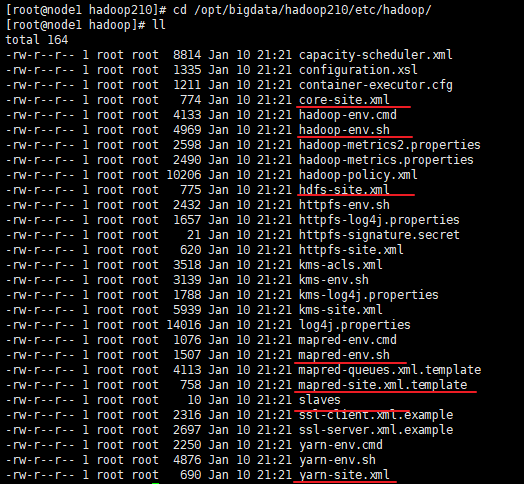
2, 配置
cd /opt/bigdata/hadoop210/etc/hadoop/
2.1 修改hadoop-env.sh
[root@node1 hadoop27]# echo $JAVA_HOME
/opt/jdk8
vim hadoop-env.sh
export JAVA_HOME=/opt/jdk8
2.2 修改core-site.xml
[root@node1 hadoop210]# pwd
/opt/bigdata/hadoop210
[root@node1 hadoop210]# mkdir hadoopDatas
[root@node1 hadoop210]# cd /opt/bigdata/hadoop210/etc/hadoop/
[root@node1 hadoop210]# vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop210/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
2.3 修改hdfs-site.xml
[root@node1 hadoop]# cd /opt/bigdata/hadoop210/etc/hadoop/
[root@node1 hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
2.4 修改yarn-site.xml
[root@node1 hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
2.5 修改mapred-env.sh
[root@node1 hadoop]# vi mapred-env.sh
export JAVA_HOME=/opt/jdk8
2.6 修改mapred-site.xml
[root@node1 hadoop]# mv mapred-site.xml.template ./mapred-site.xml
[root@node1 hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
2.7 修改slaves
[root@node1 hadoop]# vi slaves
node1
node2
node3
2.8 配置Hadoop环境变量
[root@node1 hadoop]# vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop210
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$FINDBUGS_HOME/bin:$MAVEN_HOME/bin:$JAVA_HOME/bin:$PATH
[root@node1 hadoop]# source /etc/profile
2.9 分发安装包
[root@node1 hadoop210]# cd /opt/bigdata/hadoop210/
[root@node1 hadoop210]# scp -r hadoop210 node2:$PWD
[root@node1 hadoop210]# scp -r hadoop210 node3:$PWD
[root@node1 hadoop210]# scp /etc/profile node2:/etc/
[root@node1 hadoop210]# scp /etc/profile node3:/etc/
分别在node2,node3节点机器执行以下命令: 刷新加载/etc/profile
source /etc/profile
3, 启动集群
前提: 3台机器上安装好了zookeeper, 并启动
zkServer.sh start
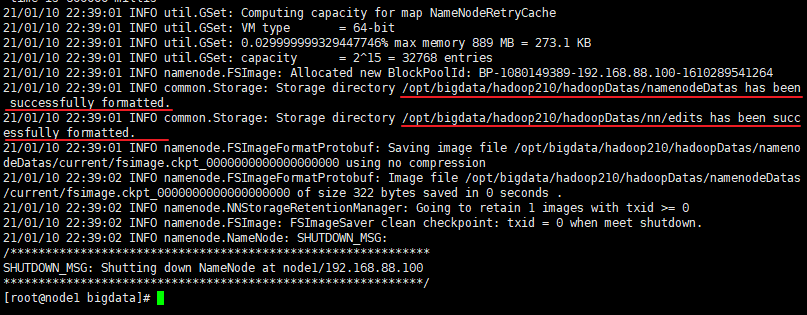
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。 注意: 首次启动 HDFS 时,必须对其进行格式化操作。 本质上是一些清理和 准备工作,因为此时的 HDFS 在物理上还是不存在的。
在node1节点机器执行以下命令
[root@node1 bigdata]# hdfs namenode -format
[root@node1 bigdata]# start-dfs.sh

[root@node1 bigdata]# start-yarn.sh

[root@node1 bigdata]# mr-jobhistory-daemon.sh start historyserver

启动完成之后, 可以通过jsp查看
大数据专栏 - 基础1 Hadoop安装配置的更多相关文章
- 大数据笔记13:Hadoop安装之Hadoop的配置安装
1.准备Linux环境 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据入门基础系列之Hadoop1.X、Hadoop2.X和Hadoop3.X的多维度区别详解(博主推荐)
不多说,直接上干货! 在前面的博文里,我已经介绍了 大数据入门基础系列之Linux操作系统简介与选择 大数据入门基础系列之虚拟机的下载.安装详解 大数据入门基础系列之Linux的安装详解 大数据入门基 ...
随机推荐
- [SUCTF 2019]Game
buuoj杂项复现 下载了之后给了我们一张图片了网站的源代码 图片简单分析了之后没有什么内容,先看源代码的index.html 里面有base32编码,解码 ON2WG5DGPNUECSDBNBQV6 ...
- [BJDCTF 2nd]假猪套天下第一 && [BJDCTF2020]Easy MD5
[BJDCTF 2nd]假猪套天下第一 假猪套是一个梗吗? 进入题目,是一个登录界面,输入admin的话会返回错误,登录不成功,其余用户可以正常登陆 以为是注入,简单测试了一下没有什么效果 抓包查看信 ...
- buucitf-[极客大挑战 2020]Roamphp1-Welcome
打开靶机,发现什么也没有,因为极客大挑战有hint.txt,里面说尝试换一种请求的方式,bp抓包,然后发送了POST请求,出现了下面的界面 这个还是挺简单的,因为是极客大挑战上的第一波题,关键是这个如 ...
- 【译】为什么Rust中的BTreeMap没有with_capacity()方法?
原文标题:Why doesn't Rust's BTreeMap have a with_capacity() method? 原文链接:https://www.nicolas-hahn.com/20 ...
- Tensorflow学习笔记No.11
图像定位 图像定位是指在图像中将我们需要识别的部分使用定位框进行定位标记,本次主要讲述如何使用tensorflow2.0实现简单的图像定位任务. 我所使用的定位方法是训练神经网络使它输出定位框的四个顶 ...
- STL——容器(List)List 的数据元素插入和删除操作
push_back(elem); //在容器尾部加入一个元素 1 #include <iostream> 2 #include <list> 3 4 using namespa ...
- 加快Linux上yum下载安装包的速度(以CentOS 7,安装gcc为例)
今天在学习Linux的过程中,学到了关于包的安装问题:rpm包管理和yum在线管理两种方式:这里因为我在实验yum安装gcc出现了网速超级慢的问题,于是搜索解决方案,重新配置repo得以解决,记录整个 ...
- js下 Day20、综合案例
一.购物车 效果图: 功能思路分析: 1. 面向对象框架 2. 模拟数据 1.多个店铺数组套对象 2.每个店铺多个商品,数组套对象
- 使用docker-maven-plugin打包
今天在部署的时候遇到点问题,总结一下,docker部署的步骤,如果对您有帮助,关注一下,就是对我最大的肯定, 谢谢! 微服务部署有两种方法: (1)手动部署:首先基于源码打包生成jar包(或war包) ...
- 转载:从输入 URL 到页面加载完的过程中都发生了什么事情?
原帖地址:http://www.guokr.com/question/554991/ 1)把URL分割成几个部分:协议.网络地址.资源路径.其中网络地址指示该连接网络上哪一台计算机,可以是域名或者IP ...