Spark系列-核心概念
一. Spark核心概念
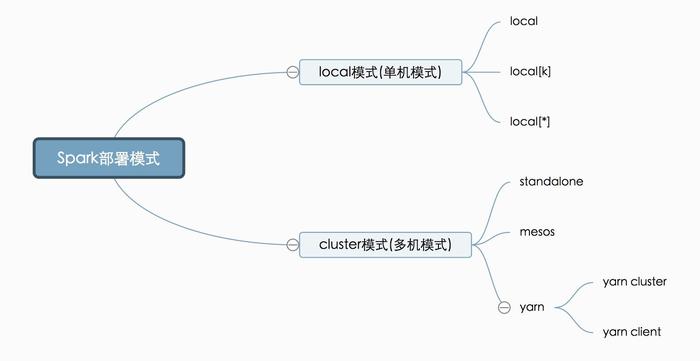
- Master,也就是架构图中的Cluster Manager。Spark的Master和Workder节点分别Hadoop的NameNode和DataNode相似,是一种主从结构。Master是集群的领导者,负责协调和管理集群内的所有资源(接收调度和向WorkerNode发送指令)。从大类上来分Master分为local和cluster两大类
- local:也就是本地模式,所有计算都在一台服务器上完成,通常用于本地开发调试。思维导图中
- local:表示启动一个线程,所有的计算都在这个线程中完成
- local[k]:启动k个worker线程
- local[*]:按照当前服务器的cpu核数来启动
- cluster:也就是集群模式,由多台服务器并行执行。
- standalone:spark自带的资源管理器
- mesos:由mesos来管理
- yarn:通常和MapReduce作业一样,资源共享,所以使用的最多。(yarn cluster:所有调度资源都在集群上运行,yarn client:出了spark driver和master进程,其余都在集群上)
- local:也就是本地模式,所有计算都在一台服务器上完成,通常用于本地开发调试。思维导图中
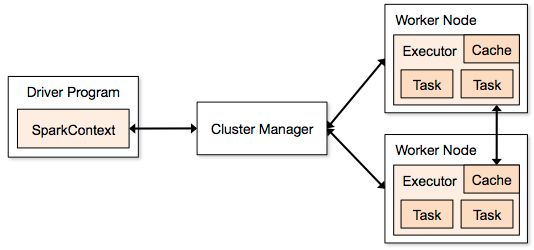
- Worker,也就是WorkderNode,负责执行Master所发送的指令,来具体分配资源并执行任务
- Driver:一个Spark job运行前会启动一个Driver进程,也就是作业的主进程,负责解析和生成各个Stage,并调度Task到Executor上
- Executer:负责执行作业。如图中所以,Executer是分步在各个Worker Node上,接收来自Driver的命令并加载Task
- SparkContext:程序运行调度的核心,高层调度去DAGScheduler划分程序的每个阶段,底层调度器TaskScheduler划分每个阶段具体任务
- DAGScheduler:负责高层调度,划分stage并生产DAG有向无环图
- TaskScheduler:负责具体stage内部的底层调度,具体task的调度和容错
- Job:每次Action都会触发一次Job,一个Job可能包含一个或多个stage
- Stage:用来计算中间结果的Tasksets。分为ShuffleMapStage和ResultStage,出了最后一个Stage是ResultStage外,其他都是ShuffleMapStage。ShuffleMapStage会产生中间结果,是以文件的方式保存在集群当中,以便能够在不同stage种重用
- Task:任务执行的工作单位,每个Task会被发送到一个节点上,每个Task对应RDD的一个partition.
- RDD:是以partition分片的不可变,Lazy级别数据集合
- 算子
- Transformation:由DAGScheduler划分到pipeline中,是Lazy级别的,不会触发任务的执行
- Action:会触发Job来执行pipeline中的运算
Spark系列-核心概念的更多相关文章
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...
- Spark系列-SparkSQL实战
Spark系列-初体验(数据准备篇) Spark系列-核心概念 Spark系列-SparkSQL 之前系统的计算大部分都是基于Kettle + Hive的方式,但是因为最近数据暴涨,很多Job的执行时 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
- ZooKeeper 系列(一)—— ZooKeeper核心概念详解
一.Zookeeper简介 二.Zookeeper设计目标 三.核心概念 3.1 集群角色 3.2 会话 3.3 数据节点 3.4 节点 ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- ZooKeeper系列(一)—— ZooKeeper 简介及核心概念
一.Zookeeper简介 Zookeeper 是一个开源的分布式协调服务,目前由 Apache 进行维护.Zookeeper 可以用于实现分布式系统中常见的发布/订阅.负载均衡.命令服务.分布式协调 ...
- Storm 系列(二)—— Storm 核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的 Storm 流处理程序被称为 Storm topology(拓扑).它是一个是由 Spouts 和 Bolts 通过 Stre ...
随机推荐
- 最长公共子序列(DP)
Description 一个给定序列的子序列是在该序列中删去若干元素后得到的序列.确切地说,若给定序列 X = { x1,x2,…,xm },则另一序列Z ={ z1,z2,…,zk },X 的子序列 ...
- Spring Boot学习笔记(六)mybatis配置多数据源
application.properties #数据库配置 #数据源类型 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource # ...
- 如何解决“There is no locally stored library”的问题
今天我在用pyCharm开发网页的时候,用cdn引入js文件,但是程序报错,说“there is no locally stored library”.于是我上网找到了解决方案,特整理如下: 在你报错 ...
- 序列化模块2 pickle
import pickle # dump的结果是bytes,dump用的f文件句柄需要以wb的形式打开,load所用的f是'rb'模式# 支持几乎所有对象的序列化# 对于对象的序列化需要这个对象对应的 ...
- bzoj P4825 [Hnoi2017]单旋——solution
Description H 国是一个热爱写代码的国家,那里的人们很小去学校学习写各种各样的数据结构.伸展树(splay)是一种数据 结构,因为代码好写,功能多,效率高,掌握这种数据结构成为了 H 国的 ...
- io流中read方法使用不当导致运行异常的一点
public class CopyMp3test { public static void main(String[] args) throws IOException { FileInputStre ...
- flutter控件之ListView滚动布局
ListView即滚动列表控件,能将子控件组成可滚动的列表.当你需要排列的子控件超出容器大小,就需要用到滚动块. import 'package:flutter/material.dart'; cla ...
- linux 用户配置文件及其相关目录
用户配置文件及其相关目录: /etc/passwd 用户信息文件/etc/shadow 影子文件/etc/group 组信息文件/etc/gshadow 组密码文件邮箱目录模板目录 /etc/pass ...
- Eclipse创建第一个Servlet(Dynamic Web Project方式)、第一个Web Fragment Project(web容器向jar中寻找class文件)
创建第一个Servlet(Dynamic Web Project方式) 注意:无论是以注解的方式还是xml的方式配置一个servlet,servlet的url-pattern一定要以一个"/ ...
- 【java8】慎用java8的foreach循环(作废)
+警告 这篇文章作废掉,是由一个错误的测试方法得到的一个错误结论,后续修正结果正在测试,将贴上. 准确测试已完成:http://www.cnblogs.com/yiwangzhibujian/p/69 ...