大数据学习——采集文件到HDFS
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
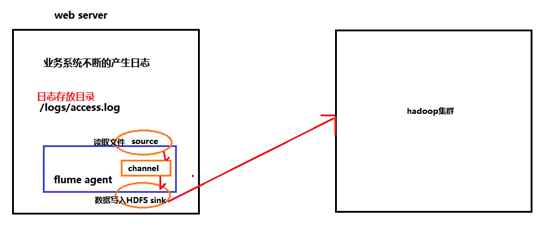
根据需求,首先定义以下3大要素
l 采集源,即source——监控文件内容更新 : exec ‘tail -F file’
l 下沉目标,即sink——HDFS文件系统 : hdfs sink
l Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
vi exec-hdfs-sink.conf
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure tail -F source1
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /root/logs/access_log
agent1.sources.source1.channels = channel1
#configure host for source
agent1.sources.source1.interceptors = i1 i2
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#agent1.sources.source1.interceptors.i1.useIP=true 表示使用ip地址或者主机名
agent1.sources.source1.interceptors.i1.useIP=false
agent1.sources.source1.interceptors.i2.type = timestamp
# Describe sink1
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
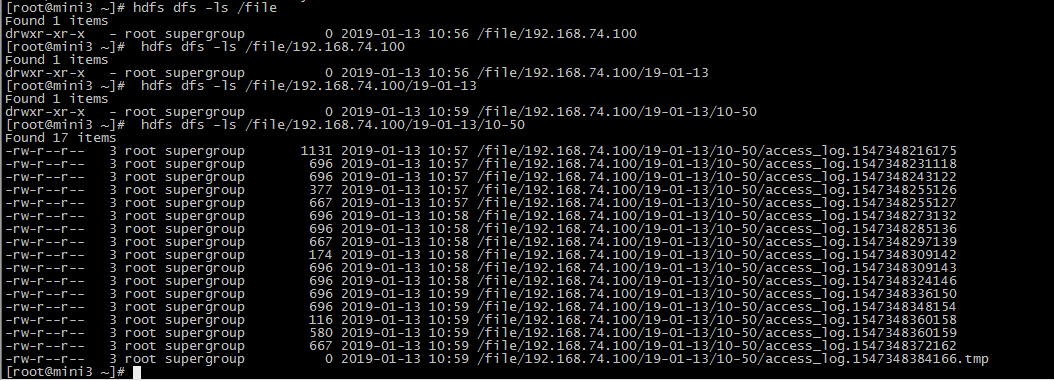
agent1.sinks.sink1.hdfs.path=hdfs://mini1:9000/file/%{hostname}/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 10240
agent1.sinks.sink1.hdfs.rollCount = 1000
模拟数据
mkdir logs
cd logs
while true; do date >>access_log ;sleep 0.5s; done

启动
bin/flume-ng agent -c conf -f conf/exec-hdfs-sink.conf -n agent1 -Dflume.root.logger=INFO,console
查看结果
大数据学习——采集文件到HDFS的更多相关文章
- 大数据学习——采集目录到HDFS
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去 根据需求,首先定义以下3大要素 l 采集源,即source——监控文件目录 : spoold ...
- 大数据学习(一)-------- HDFS
需要精通java开发,有一定linux基础. 1.简介 大数据就是对海量数据进行数据挖掘. 已经有了很多框架方便使用,常用的有hadoop,storm,spark,flink等,辅助框架hive,ka ...
- 大数据学习之旅1——HDFS版本演化
最近开始学习大数据,发现大数据有很多很多组件,我现在负责的是HDFS(Hadoop分布式储存系统)的学习,整理了一下HDFS的版本情况.因为HDFS是Hadoop的重要组成部分,所以有关HDFS的版本 ...
- 大数据学习(02)——HDFS入门
Hadoop模块 提到大数据,Hadoop是一个绕不开的话题,我们来看看Hadoop本身包含哪些模块. Common是基础模块,这个是必须用的.剩下常用的就是HDFS和YARN. MapReduce现 ...
- 大数据学习第二章、HDFS相关概念
1.HDFS核心概念: 块 (1)为了分摊磁盘读写开销也就是大量数据间分摊磁盘寻址开销 (2)HDFS块比普通的文件块大很多,HDFS默认块大小为64MB,普通的只有几千kb 原因:1.支持面向大规模 ...
- 大数据学习(03)——HDFS的高可用
高可用架构图 先上一张搜索来的图. 如上图,HDFS的高可用其实就是NameNode的高可用. 上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameN ...
- 大数据学习(2)HDFS文件管理
命令行管理HDFS [root@server1 bin]# hadoop fs Usage: hadoop fs [generic options] [-appendToFile <locals ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- 转:从《The C Programming Language》中学到的那些编程风格和设计思想
这儿有一篇写的很好的读后感:http://www.cnblogs.com/xkfz007/articles/2566424.html 读书不是目的,关键在于思考. 很早就在水木上看到有人推荐& ...
- CentOS 7.4安装mariadb,启动报错
[root@iZ25b6alxstZ ~]# systemctl start mariadb Job for mariadb.service failed because the control pr ...
- MonoBehaviour生命周期
MonoBehaviour生命周期 上图中重要的信息点很多,需要特别注意的是所有脚本的Awake方法都执行完才会执行Start,但是如果在Awake 中开启了一个协程这个协程中每一帧执行一些操作然后等 ...
- Lumia 刷机(强刷)Message send failed解决办法
强刷可以救砖,不需要验证地区code,可以跨刷其它国家/地区的固件,但不是所有机型都可以这样,Lumia 620是支持跨刷的. 看本文你首先要知道使用Nokia Care Suite强刷的步骤,参考从 ...
- linux小白成长之路12————Docker部署Nginx
[内容指引] Docker安装Nginx: 简单启动: 准备配置文件: 一.Docker安装Nginx 指令:docker pull nginx 二.简单启动 指令:docker run --name ...
- codevs 2046 孪生素数 3 (水题日常)
时间限制: 1 s 空间限制: 32000 KB 题目等级 : 黄金 Gold 题目描述 Description 在质数的大家庭中,大小之差不超过2的两个质数称它俩为一对孪生素数,如2和3.3和5 ...
- 怎么用eclipse生成jar文件?eclipse导出jar介绍
1 .我们先要增加jar需要的配置文件,选中项目的src目录,鼠标右键,选择 [New] -选择 [Folder] . 2. 输入META-INF 作为目录名称,点击[Finish] . 3. 选中刚 ...
- 如何修改站点url
1.config目录下的config_global.php 文件,修改:$_config['cookie']['cookiedomain'] = '.xxxxx.com';2.config目录下的co ...
- Android系统固件定制方式
target_product.mkAndroid系统在构建关于某种产品的固件时,一般会根据特定于该产品的具体target_product.mk来配置生成整个Android系统./target_prod ...
- Python3基础教程(十八)—— 测试
编写测试检验应用程序所有不同的功能.每一个测试集中在一个关注点上验证结果是不是期望的.定期执行测试确保应用程序按预期的工作.当测试覆盖很大的时候,通过运行测试你就有自信确保修改点和新增点不会影响应用程 ...