简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页

这是简易数据分析系列的第 12 篇文章。
前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据、点击“更多按钮“加载数据和下拉自动加载数据。今天我们说说一种更常见的翻页类型——分页器。
本来想解释一下啥叫分页器,翻了一堆定义觉得很繁琐,大家也不是第一年上网了,看张图就知道了。我找了个功能最全的例子,支持数字页码调整,上一页下一页和指定页数跳转。

今天我们就学学,Web Scraper 怎么对付这种类型的网页翻页。
其实我们在本教程的第一个例子,抓取豆瓣电影 TOP 排行榜中,豆瓣的这个电影榜单就是用分页器分割数据的:

但当时我们是找网页链接规律抓取的,没有利用分页器去抓取。因为当一个网页的链接变化规律时,控制链接参数抓取是实现成本最低的;如果这个网页进可以翻页,但是链接的变化不是规律的,就得去会一会这个分页器了。
说这些理论有些枯燥,我们举个翻页链接不规律的例子。
8 月 2 日是蔡徐坤的生日,为了表达庆祝,在微博上粉丝们给坤坤刷了 300W 的转发量,微博的转发数据正好是用分页器分割的,我们就分析一下微博的转发信息页面,看看这类数据怎么用 Web Scraper 抓取。

这条微博的直达链接是:
https://weibo.com/1776448504/I0gyT8aeQ?type=repost
看了他那么多的视频,为了表达感激,我们可以点进去出为坤坤加一份阅读量。
首先我们看看第 1 页转发的链接,长这个样子:
第 2 页长这个样子,注意到多了个 #_rnd1568563840036 参数:
https://weibo.com/1776448504/I0gyT8aeQ?type=repost#_rnd1568563840036
第 3 页参数为 #_rnd1568563861839
https://weibo.com/1776448504/I0gyT8aeQ?type=repost#_rnd1568563861839
第 4 页参数为 #_rnd1568563882276:
https://weibo.com/1776448504/I0gyT8aeQ?type=repost#_rnd1568563882276
多看几个链接你就可以发现,这个转发网页的网址毫无规律可言,所以只能通过分页器去翻页加载数据。下面就开始我们的实战教学环节。
1.创建 SiteMap
我们首先创建一个 SiteMap,这次取名为 cxk,起始链接为 https://weibo.com/1776448504/I0gyT8aeQ?type=repost。
2.创建容器的 selector
因为我们要点击分页器,外面的容器的类型我们选为 Element Click,具体的参数解释可以看下图,我们之前在简易数据分析 08详细解释过一次,这里就不多言了。
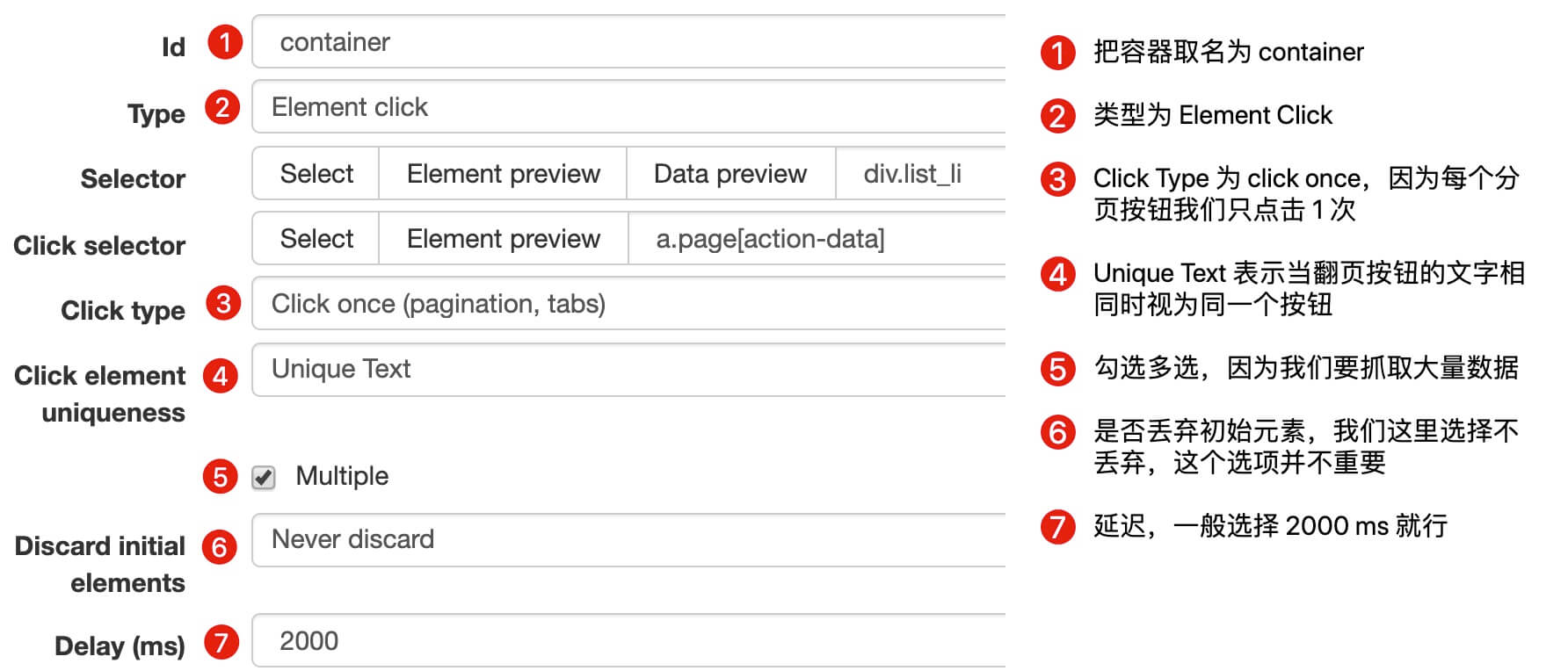
container 的预览是下图的样子:

分页器选择的过程可以参看下图:

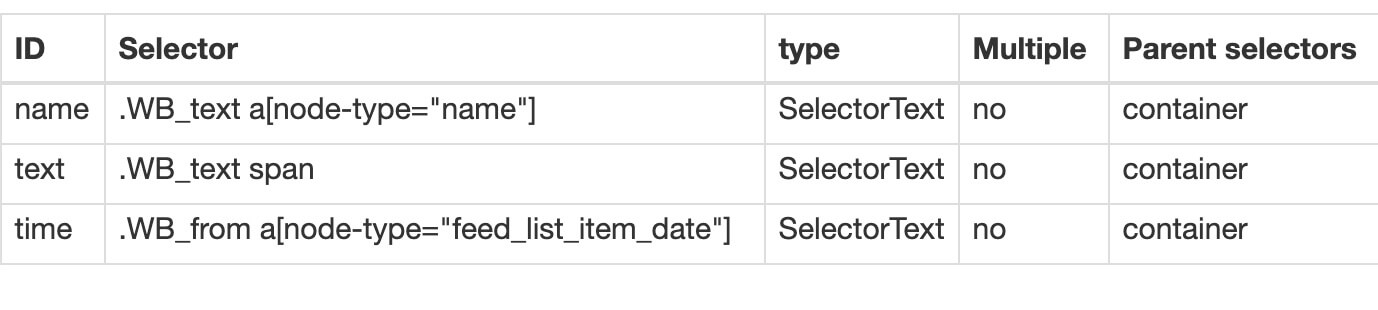
3.创建子选择器
这几个子选择器都比较简单,类型都是文字选择器,我们选择了评论用户名,评论内容和评论时间三种类型的内容。
4.抓取数据
按照 Sitemap cxk -> Scrape 的操作路径就可以抓取数据了。
5.一些问题
如果你看了我上面的教程立马去爬数据,可能遇到的第一个问题就是,300w 的数据,难道我全部爬下来吗?
听上去也不太现实,毕竟 Web Scraper 针对的数据量都是相对比较小的,几万数据都算多的了,数据再大你就得考虑爬取时间是否太长,数据如何存储,如何应对网址的反爬虫系统(比如说冷不丁的跳出一个验证码,这个 Web Scraper 是无能为力的)。
考虑到这个问题,前面的自动控制抓取数量的教程你又看过的话,可能想着用 :nth-of-type(-n+N) 控制抓取 N 条数据。如果你尝试了,就会发现这个方法根本没用。
失效的原因其实涉及到一点点网页的知识了,感兴趣的话可以看看下面的解释,不感兴趣可以直接看最后的结论。
像我前面介绍的点击更多加载型网页和下拉加载型网页,他们新加载的数据,是在当前页面追加的,你一直下拉,数据一直加载,同时网页的滚动条会越来越短,这意味着所有的数据都在同一个页面。
当我们用 :nth-of-type(-n+N) 控制加载数量时,其实相当于在这个网页设立一个计数器,当数据一直累加到我们想要的数量时,就会停止抓取。
但是对于使用翻页器的网页,每次的翻页相当于刷新当前网页,这样每次都会设立一个计数器。
比如说你想抓取 1000 条数据,但是第 1 页网页只有 20 条数据,抓到最后一条了,还差 980 条;然后一翻页,又设立一个新的计数器,抓完第 2 页的最后一条数据,还差 980,一翻页计数器就重置,又变成 1000 了......所以这个控制数量的方法就失效了。
所以结论就是,如果翻页器类型的网页想提前结束抓取,只有断网的这种方法。当然,如果你有更好的方案,可以在评论里回复我,我们可以互相讨论一下。
6.总结
分页器是一种很常见的网页分页方法,我们可以通过 Web Scraper 中的 Element click 处理这种类型的网页,并通过断网的方法结束抓取。
7.推荐阅读
简易数据分析 05 | Web Scraper 翻页——控制链接批量抓取数据
简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器

简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页的更多相关文章
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16
这是简易数据分析系列的第 16 篇文章. 这期课程我们讲一个用的较少的 Web Scraper 功能--抓取属性信息. 网页在展示信息的时候,除了我们看到的内容,其实还有很多隐藏的信息.我们拿豆瓣电影 ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
随机推荐
- ZooKeeper系列(一)—— ZooKeeper 简介及核心概念
一.Zookeeper简介 Zookeeper 是一个开源的分布式协调服务,目前由 Apache 进行维护.Zookeeper 可以用于实现分布式系统中常见的发布/订阅.负载均衡.命令服务.分布式协调 ...
- 自定义GroupBox
public partial class mGroupBox : GroupBox { private Color _TitleBackColor = Color.Black; private Fon ...
- 使用 .NET CORE 创建 项目模板,模板项目,Template
场景:日常工作中,你可能会碰到需要新建一个全新的解决方案的情况(如公司新起了一个新项目,需要有全新配套的后台程序),如果公司内部基础框架较多.解决方案需要DDD模式等,那么从新起项目到各种依赖引用到能 ...
- 关于selenium自动化对窗口句柄的处理
首先什么是句柄?句柄就是你点击一个页面,跳转了一个新的窗口.你要操作的元素可能在原窗口上,也有可能在新窗口上. 看下图句柄1 句柄2 由这2张图可知,url不一样,证明他们是处于不同的界面,我要操作的 ...
- 从无到有构建vue实战项目(七)
十四.Vuex的使用 Vuex是什么? Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化.Vu ...
- Codeforces 337D
题意略. 思路: 本题着重考察树的直径.如果我们将这些标记点相连,将会得到大树中的一个子树.我之前只知道树内的点到直径上两端点的距离是最远的,其实,在 整个大树中,这个性质同样适用,也即大树上任意一点 ...
- 持续集成高级篇之Jenkins Pipeline git拉取
系列目录 PipeLine中拉取远程git仓库 前面讲自由式任务的时候,我们可以看到通过自由式job里提供的图形界面配置git拉取非常方便的,实际上使用PipeLine也并不复杂.这一节我们展示一下如 ...
- Mysql分区实战
一,什么是数据库分区 前段时间写过一篇关于MySQL分表的的文章,下面来说一下什么是数据库分区,以mysql为例.mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面 ...
- 【基准测试】JMH 简单入门
JMH 简单入门 什么是 JMH JMH 是 Java Microbenchmark Harness 的缩写.中文意思大致是 "JAVA 微基准测试套件".首先先明白什么是&quo ...
- Educational Codeforces Round 43 E&976E. Well played! 贪心
传送门:http://codeforces.com/contest/976/problem/E 参考:https://www.cnblogs.com/void-f/p/8978658.html 题意: ...