数据分析入门——pandas数据处理
1,处理重复数据
使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True:
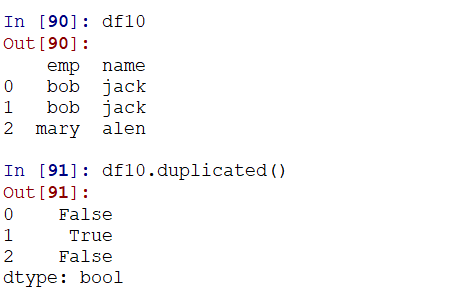
对应的,可以使用drop_duplicates来删除重复的行:

以上两个方法,都不能有重复的列!
2.map函数:列处理
map() 是一个Series的函数,DataFrame结构中没有map()。map()将一个自定义函数应用于Series结构中的每个元素(elements)。
传入一个拉姆达表达式:
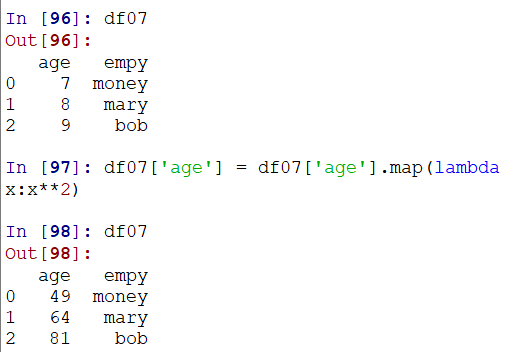
可以通过不存在的列名,利用map映射新增一列:(当然,此处map传入的可以是自定义函数,但不能是类似sum这样的UDTF聚合函数,而必须是UDF函数)

其他与apply、applymap等的区别,参考:https://blog.csdn.net/maymay_/article/details/80229053
3.rename函数:替换索引
使用renname函数替换行索引:(列索引通过columns控制同理,使用一个dict进行映射,包含映射的将会进行映射!)

更加简单粗暴的方法可以直接通过df.index = 赋值操作来进行!
4.异常值检测和过滤
通过describe查看统计性数值:count——数据量有几个数,mean是平均值,std表示标准差(波动),min/max最小/最大值,中间百分比则是取最小最大值之间的25%、50%等的值

通过std求每一列的标准差:(可以通过axis来控制轴)
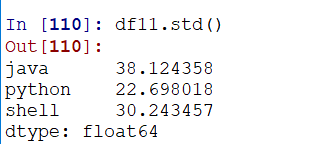
通过标准差,借助any()函数(any函数一真即真,有一个True则返回True)来实现过滤
例如检测大于两倍标准差的:(这里通过控制轴,来取得每个同学而不是每个科目的过滤值)
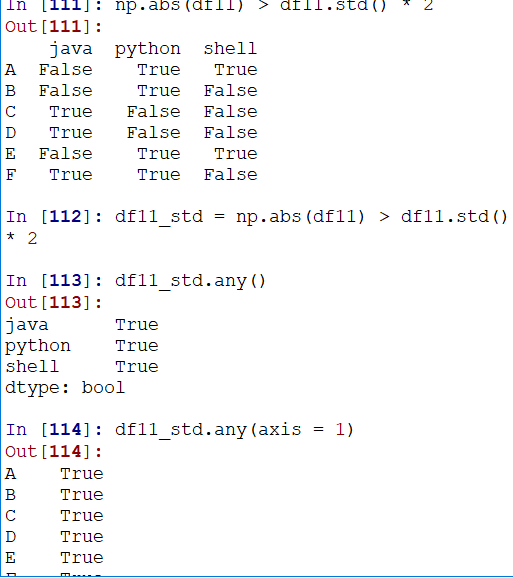
顺势,就可以过滤数据了:(通过boolean提取数据,参考:https://www.jianshu.com/p/b1be2eccd029)

5.排序抽样——take函数
利用随机生成的顺序,结合take取数据:

使用random.randint可以实现随机抽样的效果
6.数据聚合(重点)
数据聚合通常是数据处理的最后一步,一般是要使每个数组产生唯一的值:
通常分类涉及到的是:分组—>函数处理——>合并
使用groupby分组:

打印发现是一个GroupBy的对象,使用groups属性,可以查看分成了哪几个组:
GroupBy对象的更多操作,参考:https://www.jianshu.com/p/42f1d2909bb6

可以通过筛选的方式,快速求出平均值等操作:(返回的是一个Series)

通过merge,可以整合平均值到原df中去:
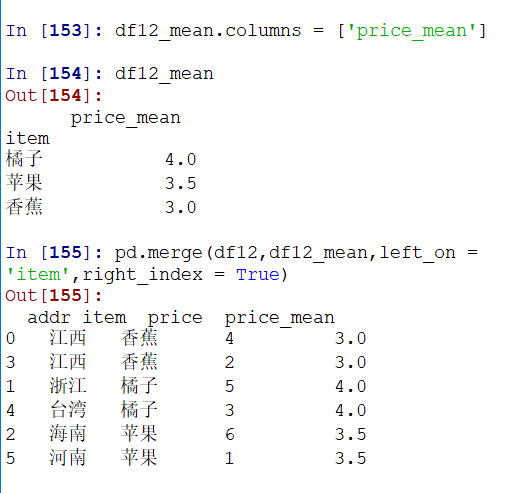
通过其他列分组,同理:(如果不选择列,则会对所有能操作的列进行操作,返回一个df结果)
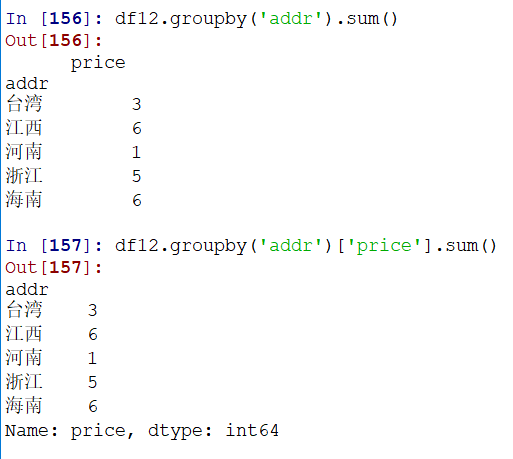
多列分组,同理:

7.高级数据聚合
可以通过transform和apply实现相同功能,并且,apply可以传入一个匿名函数
apply和map的区别,参考:https://blog.csdn.net/weixin_39791387/article/details/81487549
https://www.jianshu.com/p/c384ac86c4a6
map() 方法是pandas.series.map()方法, 对DF中的元素级别的操作, 可以对df的某列或某多列, 可以参考文档
apply(func) 是DF的属性, 对DF中的行数据或列数据应用func操作.
applymap(func) 也是DF的属性, 对整个DF所有元素应用func操作————————————————
版权声明:本文为CSDN博主「诸葛老刘」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_39791387/article/details/81487549

数据分析入门——pandas数据处理的更多相关文章
- 数据分析入门——pandas之Series
一.介绍 Pandas是一个开源的,BSD许可的库(基于numpy),为Python编程语言提供高性能,易于使用的数据结构和数据分析工具. 官方中文文档:https://www.pypandas.cn ...
- 数据分析入门——Pandas类库基础知识
使用python进行数据分析时,经常会用Pandas类库处理数据,将数据转换成我们需要的格式.Pandas中的有两个数据结构和处理数据相关,分别是Series和DataFrame. Series Se ...
- 数据分析入门——pandas之DataFrame基本概念
一.介绍 数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列. 可以看作是Series的二维拓展,但是df有行列索引:index.column 推荐参考:https://www. ...
- 数据分析入门——pandas之数据合并
主要分为:级联:pd.concat.pd.append 合并:pd.merge 一.numpy级联的回顾 详细参考numpy章节 https://www.cnblogs.com/jiangbei/p/ ...
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- 数据分析入门——pandas之DataFrame数据丢失
一.数据丢失分类 1)nd中分为两种:None和np.nan(NaN) 其中,None是python中的对象,是一个object:而nan是一个float类型 两种不同的类型,运算速度也是不同的 2) ...
- 数据分析入门——pandas之合并函数merge
merge有点类似SQL中的join,可以将不同数据集按照某些字段进行合并,得到新的数据集 1.参数一览表: 2.一对一连接:默认情况下,会按照相同字段的进行连接 例如有相同字段emp的两个df,m ...
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- 利用python进行数据分析之pandas入门
转自https://zhuanlan.zhihu.com/p/26100976 目录: 5.1 pandas 的数据结构介绍5.1.1 Series5.1.2 DataFrame5.1.3索引对象5. ...
随机推荐
- 【Java字节码】Idea中查看Java字节码的插件jclasslib Bytecode viewer
Idea插件搜索:jclasslib Bytecode viewer 安装完后,maven install你的项目(因为该插件会读取target下的class文件),然后选中某个java文件,按下图操 ...
- Linux命令——screen
参考:linux 技巧:使用 screen 管理你的远程会话 How to use GNU screen - the terminal multiplexer - linux
- [AI] 论文笔记 - U-Net 简单而又接近本质的分割网络
越简单越接近本质. 参考资料 U-Net: Convolutional Networks for Biomedical Image Segmentation Abstract & Introd ...
- springboot禁用内置Tomcat的不安全请求方法
起因:安全组针对接口测试提出的要求,需要关闭不安全的请求方法,例如put.delete等方法,防止服务端资源被恶意篡改. 用过springMvc都知道可以使用@PostMapping.@GetMapp ...
- http上传下载文件
curl_easy_setopt curl库的方式 调用 (c++中) 短连接 一次请求 一次响应
- Vue 项目中 ESlint 配置
前言 对于 ESlint 这一块一直存在一些疑问,今天看到一个文章内容挺好的,这里拿来了. 一.eslint 安装 1.全局安装 npm i -g eslint 全局安装的好处是,在任何项目我们都可以 ...
- object store in javascript
- wordpress调用缩略图/特色图url
调用缩略图的url <a href="<?php the_post_thumbnail_url( 'full' ); ?>"><?php the_po ...
- datediff(date1,date2) 函数的使用
版权声明:本文为博主原创文章,未经博主允许不得转载. 在MySQL中可以使用DATEDIFF()函数计算两个日期之间的天数 语法: datediff(date1,date2) 注:date1和date ...
- MySQL 为什么不用分区表(转载)
一分钟系列 潜在场景如何? 当MySQL单表的数据量过大时,数据库的访问速度会下降,“数据量大”问题的常见解决方案是“水平切分”. MySQL常见的水平切分方案有哪些? (1)分库分表: (2)分区表 ...