用KNN实现iris的4分类问题&测试精度
import matplotlib.pyplot as plt
from scipy import sparse
import numpy as np
import matplotlib as mt
import pandas as pd
from IPython.display import display
from sklearn.datasets import load_iris
import sklearn as sk
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier iris=load_iris()
#print(iris)
X_train,X_test,y_train,y_test = train_test_split(iris['data'],iris['target'],random_state=0)
iris_dataframe = pd.DataFrame(X_train,columns=iris.feature_names)
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
# KNeighborsClassifier(algorithm='auto',leaf_size=30,metric='minkowski',
# metric_params=None,n_jobs=1,n_neighbors=1,p=2,weights='uniform')
X_new = np.array([[5,2.9,1,0.2]])
print("X_new.shape:{}".format(X_new.shape))
prediction = knn.predict(X_new)
print("Prediction X_new:{}".format(prediction))
print("prediction X_new belong to {}".format(iris['target_names'][prediction])) #评估模型
#计算精度方法1
print("test score1:{:.2f}".format(knn.score(X_test,y_test)))
#计算精度方法2
y_pred = knn.predict(X_test)
print("test score2:{:.2f}".format(np.mean(y_pred == y_test)))
输出:
Prediction X_new:[0]
prediction X_new belong to ['setosa']
test score1:0.97
test score2:0.97
测试精度
knn的邻居设置会影响测试精度,举例说明:
import matplotlib.pyplot as plt
import mglearn
from scipy import sparse
import numpy as np
import matplotlib as mt
import pandas as pd
from IPython.display import display
from sklearn.datasets import load_breast_cancer
import sklearn as sk
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier cancer = load_breast_cancer()
X_train,X_test,y_train,y_test =train_test_split(cancer.data,cancer.target,stratify=cancer.target,random_state=66)
training_accuracy=[]
test_accuracy=[]
neighbors_settings = range(1,11)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train,y_train)
training_accuracy.append(clf.score(X_train,y_train))
test_accuracy.append(clf.score(X_test,y_test)) plt.plot(neighbors_settings,training_accuracy,label="training accuracy")
plt.plot(neighbors_settings,test_accuracy,label="test accuracy")
plt.xlabel("n_neighbors")
plt.ylabel("accuracy")
plt.legend()
plt.show()
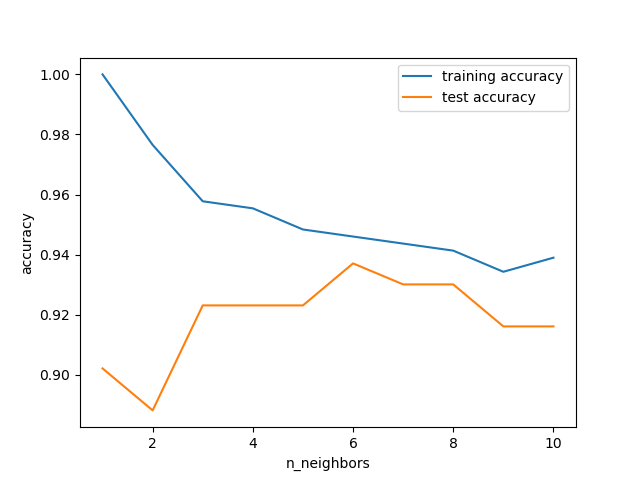
可以看出,6是最优。
KNN算法的优点是简单可解释性强,
缺点是:
- 样本大的时候性能不好
- 特征多(几百个+)的时候效果不好
- 稀疏数据集不适用
用KNN实现iris的4分类问题&测试精度的更多相关文章
- kNN(K-Nearest Neighbor)最近的分类规则
KNN最近的规则,主要的应用领域是未知的鉴定,这一推断未知的哪一类,这样做是为了推断.基于欧几里得定理,已知推断未知什么样的特点和最亲密的事情特性: K最近的邻居(k-Nearest Neighbor ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- kNN处理iris数据集-使用交叉验证方法确定最优 k 值
基本流程: 1.计算测试实例到所有训练集实例的距离: 2.对所有的距离进行排序,找到k个最近的邻居: 3.对k个近邻对应的结果进行合并,再排序,返回出现次数最多的那个结果. 交叉验证: 对每一个k,使 ...
- knn原理及借助电影分类实现knn算法
KNN最近邻算法原理 KNN英文全称K-nearst neighbor,中文名称为K近邻算法,它是由Cover和Hart在1968年提出来的 KNN算法原理: 1. 计算已知类别数据集中的点与当前点之 ...
- 85、使用TFLearn实现iris数据集的分类
''' Created on 2017年5月21日 @author: weizhen ''' #Tensorflow的另外一个高层封装TFLearn(集成在tf.contrib.learn里)对训练T ...
- 使用KNN对iris数据集进行分类——python
filename='g:\data\iris.csv' lines=fr.readlines()Mat=zeros((len(lines),4))irisLabels=[]index=0for lin ...
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- 最邻近规则分类(K-Nearest Neighbor)KNN算法
自写代码: # Author Chenglong Qian from numpy import * #科学计算模块 import operator #运算符模块 def createDaraSet( ...
- kNN(K-Nearest Neighbor)最邻近规则分类
KNN最邻近规则,主要应用领域是对未知事物的识别,即推断未知事物属于哪一类,推断思想是,基于欧几里得定理,推断未知事物的特征和哪一类已知事物的的特征最接近: K近期邻(k-Nearest Neighb ...
随机推荐
- NET Framework 的泛型
NET Framework 的泛型 泛型是具有占位符(类型参数)的类.结构.接口和方法,这些占位符是类.结构.接口和方法所存储或使用的一个或多个类型的占位符.泛型集合类可以将类型参数用作它所存储的对象 ...
- 学习Spring-Data-Jpa(四)---Naming命名策略,源码跟踪
1.首先在Entity实体中,命名方式有两种: 一种是显示命名,即通过@Table的name属性指定对应的数据库表名称,@Column的name属性指定实体字段对应数据库字段的名称. 另一种是隐式命名 ...
- php自定义函数之匿名函数
所谓匿名,就是没有名字. 匿名函数,也就是没有函数名的函数.直线电机参数 匿名函数的第一种用法,直接把赋数赋值给变量,调用变量即为调用函数. 匿名函数的写法比较灵活. 1.变量函数式的匿名函数 < ...
- 011——MATLAB清除工作控件变量
(一):参考文献:https://zhidao.baidu.com/question/234530287.html 清除当前工作空间全部变量:clear: 清除当前工作空间某些变量:clear 变量名 ...
- learning java java.time相关类
var clock = Clock.systemUTC(); System.out.println(clock.instant()); System.out.println(clock.millis( ...
- 通过map文件找程序崩溃的代码行
一,配置vs 二,程序崩溃界面 // ConsoleApplication1.cpp : 此文件包含 "main" 函数.程序执行将在此处开始并结束. // #include &l ...
- D. Vasya and Triangle(思维, 三角形)
传送门 题意: 给你 n, m, k, 问你是否存在一个三角形, 满足三角形的面积等于 n * m / k: 若存在, 输出YES, 且输出满足条件的三角形的三个坐标(答案有多种,则输出任意一种) ...
- Linux下安装Phalcon系统环境安装Phalcon 及 安装Phalcon Developer Tools
一.安装Phalcon Phalcon 需要用的的PHP扩展函数有如下: curl gettext gd2 (to use the Phalcon\Image\Adapter\Gd class) li ...
- Jmeter5.1 Plugins Manager配置dummy使用jp@gc - Dummy Sampler
背景和目的 最近想使用dummy进行mockserver服务器的模拟来实现正则表达式测试,但是发现在选项中没有Plugins Manager可供选择 如果本文对你有帮助,请关注我哦,一起进步.接下来看 ...
- [转] 修改sqlserver的数据库名、物理名称和逻辑文件名
转载: https://blog.csdn.net/dym0080/article/details/81017777