Jmeter(十九)_ForEach控制器实现网页爬虫
一直以来,爬虫似乎都是写代码去实现的,今天像大家介绍一下Jmeter如何实现一个网页爬虫! 龙渊阁测试开发家园 317765580
Jmeter的爬虫原理其实很简单,就是对网页提交一个请求,然后把返回的所有href提取出来,利用ForEach控制器去实现url遍历。这样解释是不是很清晰?下面就来简单介绍一下如何操作。
首先我们需要对网页提交一个请求,就拿腾讯新闻网举例子吧!我们像腾讯新闻网发起一个请求,观察一下返回值可以发现中间有很多href标签+文字标题的url
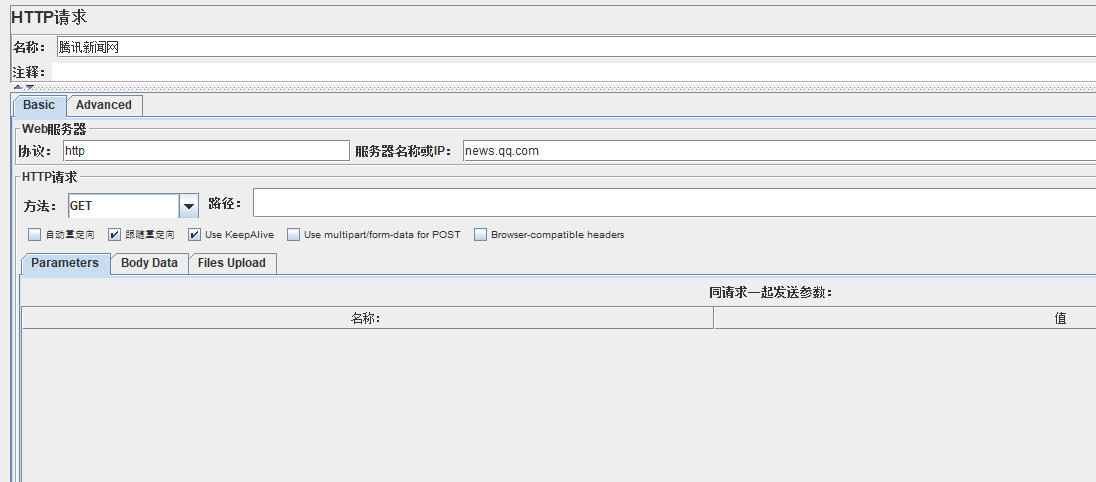

我们现在需要把这些url提取出来,利用强大的正则表达式!记得匹配数字填-1,意思就是把所有合适的url都取出来 龙渊阁测试开发家园 317765580
a target="_blank" class="linkto" href="http:// *(.*l)"

加一个debug查看一下是否真的取出来了 龙渊阁测试开发家园 317765580

又或者我们在结果里面直接利用正则匹配一下,可以看到很多网页链接都被取出来了 龙渊阁测试开发家园 317765580

接下来我们需要动用到ForEach控制器了,利用这个控制器对所有取出来的url进行遍历触发。记得在控制器里面填入变量名称,也就是刚刚正则表达式里面的变量名
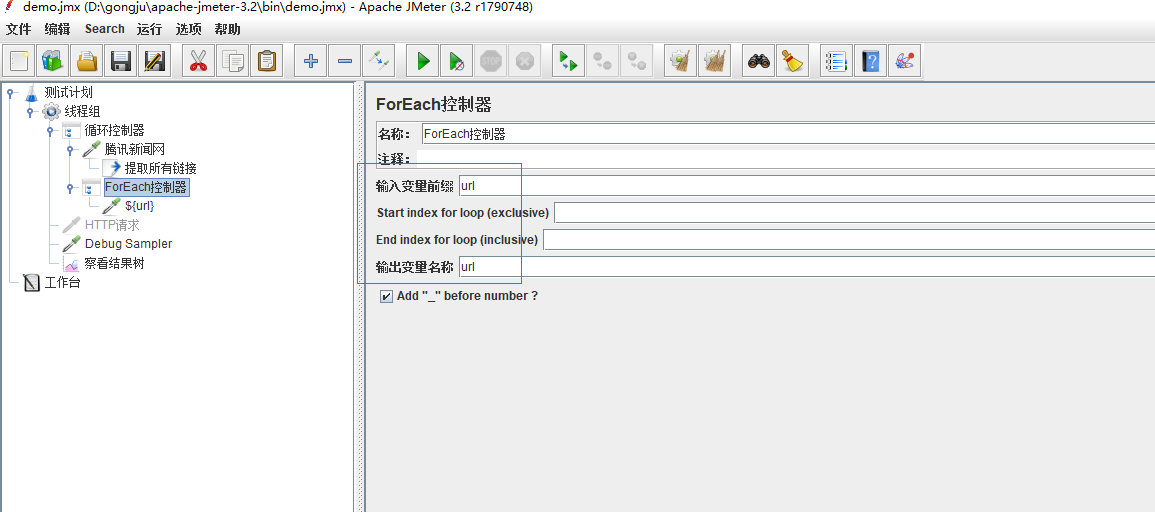
接下来在ForEach控制器下面再添加一个http请求,利用它去执行请求触发

下面我们可以观察结果了,见证奇迹的时候到了。观察结果我们发现所有匹配的url都被触发了! 龙渊阁测试开发家园 317765580

Jmeter(十九)_ForEach控制器实现网页爬虫的更多相关文章
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式 我们自定义一个main.py来作为启动文件 main.py #!/usr/bin/en ...
- Jmeter(三十五)_精确实现网页爬虫
Jmeter实现了一个网站文章的爬虫,可以把所有文章分类保存到本地文件中,并以文章标题命名 它原理就是对网页提交一个请求,然后把返回的所有值提取出来,利用ForEach控制器去实现遍历.下面来介绍一下 ...
- Jmeter_ForEach控制器实现网页爬虫
一直以来,爬虫似乎都是写代码去实现的,今天像大家介绍一下Jmeter如何实现一个网页爬虫! Jmeter的爬虫原理其实很简单,就是对网页提交一个请求,然后把返回的所有href提取出来,利用ForEac ...
- Jmeter(十九) - 从入门到精通 - JMeter监听器 -上篇(详解教程)
1.简介 监听器用来监听及显示JMeter取样器测试结果,能够以树.表及图形形式显示测试结果,也可以以文件方式保存测试结果,JMeter测试结果文件格式多样,比如XML格式.CSV格式.默认情况下,测 ...
- Jmeter(四十五) - 从入门到精通高级篇 - Jmeter之网页爬虫-上篇(详解教程)
1.简介 上大学的时候,第一次听同学说网页爬虫,当时比较幼稚和懵懂,觉得就是几只电子虫子爬在网页上在抓取东西.后来又听说写代码可以实现网页爬虫,宏哥感觉高大上,后来工作又听说,有的公司做爬虫被抓的新闻 ...
- Python之路【第十九篇】:爬虫
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
随机推荐
- C#读取AD域用户信息
private const string domainName = "本机IP地址或域名"; private const string adAdmin = "管理员帐号& ...
- How HashMap works in java 2
https://www.javacodegeeks.com/2014/03/how-hashmap-works-in-java.html Most common interview questio ...
- 64位Windows的Dos中取消了edit命令
前段时间在玩dos命令行的时候,用copy con创建了txt文件后想对其进行编辑,然后我又不想用记事本,所以去网上找命令行中对文本文件进行编辑的命令(纯属想装B),结果看到了edit命令. 一敲,就 ...
- Hadoop HBase概念学习系列之META表和ROOT表(六)
在 HBase里的HRegion 里,谈过,HRegion是按照表名+开始/结束主键,即表名+主键范围来区分的.由于主键范围是连续的,所以一般用开始主键就可以表示相应的HRegion了. 不过,因为我 ...
- November 16th, 2017 Week 46th Thursday
Don't you wonder sometimes, what might have happened if you tried. 有时候,你会不会想,如果当初试一试会怎么样? If I had t ...
- System.IO.Path文件路径类
Path类的静态属性和方法,此类操作不影响物料文件. 属性 char a = System.IO.Path.VolumeSeparatorChar;//: char b = System.IO.Pat ...
- 1.HBase In Action 第一章-HBase简介(后续翻译中)
This chapter covers ■ The origins of Hadoop, HBase, and NoSQL ■ Common use cases for HBase ■ A basic ...
- BZOJ5016:[SNOI2017]一个简单的询问(莫队)
Description 给你一个长度为N的序列ai,1≤i≤N和q组询问,每组询问读入l1,r1,l2,r2,需输出 get(l,r,x)表示计算区间[l,r]中,数字x出现了多少次. Input 第 ...
- Spark2.3文档翻阅的一点简略笔记(WaterMarking)
写本文原因是之前已经将官网文档阅读过几遍,但是后来工作接触spark机会较少所以没有跟进新特性,利用周末一点闲暇时间粗略阅读一篇,将自己之前遇见过的问题解决过的问题印象不深刻的问题做一下记录. 1关于 ...
- Spring 加载Controller逻辑的源码笔记
org.springframework.web.servlet.handler.AbstractHandlerMethodMapping#initHandlerMethods 进行加载Controll ...