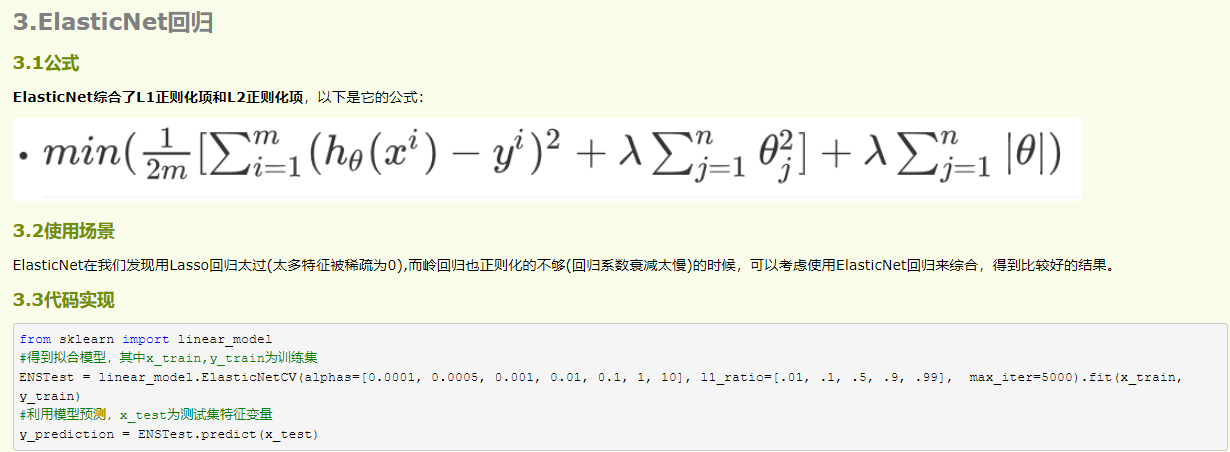
L1 L2正则化
范数
0范数
\(L_0\)范数表示为向量中非0元素的个数
\]
1范数
向量中元素绝对值的和,也就是\(x\)与0之间的曼哈顿距离
\]
2范数
\(x\)与0之间的欧式范数, 也就是向量中的每个数的平方之和
\]
p范数
\]
正则化的来源
正则化主要是用来控制模型的复杂度, 从而控制过拟合
做法:一般在损失函数中加入惩罚项
\]
\(w\)显然, 是参数, \(\alpha\)控制正则化的强弱, 是一个常数
从下图讲解:
- 准确率: 右>左
- 模型复杂度: 右>左
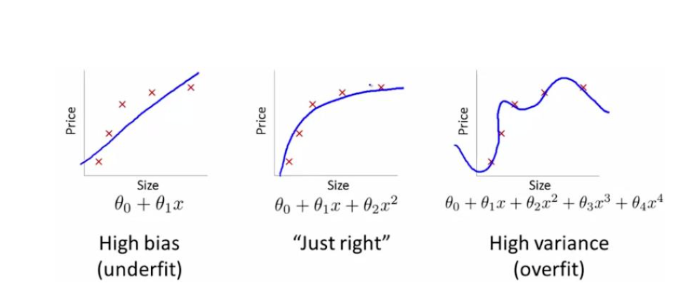
但是在测试的时候, 会出现过拟合的模型, 泛化效果变差的现象
为什么\(L_1\)和\(L_2\)能减小过拟合?
ML的目的是获得做好的参数\(w\), 并让模型的泛化能力更好
当模型复杂的时候, 相应的\(w\)也变多, 于是产生可过拟合现象, 为了降低模型的复杂度, 可以考虑适当的减少参数,代价就是准确率会适当的下降
如何减小参数?: 让\(w\)中的部分元素为0,也就是限制\(w\)中非0元素的个数
那么非0个数如何表示--> \(L_0\)范数, 于是我们有优化问题:
\min L(w,x,y) \\
||w||_0 \leq C
\end{cases}
\]
最小化损失, 并且约束是 非0元素的个数, 小于一定的值, 但是这个约束, 不好优化
于是有了\(L_1,L_2\)
初衷是限制w元素0的个数, 但可不可以这样?: 让\(w\)中的某些元素, 尽可能的趋近于0
\(||w|| \leq C\) 或者 \(||w||_2 \leq C\)
那么就可以发现, 刚好, 这是1 2 范数
那么可以得到优化问题
\min L(w,x,y) \\
||w||_1 \leq C
\end{cases}
\begin{cases}
\min L(w,x,y) \\
||w||_{2}\leq C
\end{cases}
\]
然后开始解优化问题, 一般具有约束的优化问题, 可以用拉格朗日函数
L(w,\alpha) = L(w,x,y)+\alpha(||w||_2-C) \\
\]
上式也可写成
L(w,\alpha) = L(w,x,y)+\alpha ||w||_2- \alpha C
\]
然后按没有正则化时的计算方式一样, 求偏导,令其为0,求\(w\)就可以了, 这样的化, 和\(\alpha C\)就没有关系了
树形结合
我们继续看对\(w\)的约束项
\(L_1\) 正则
\]
从2维平面的角度来看, \(L_1\)为:
\]
从数学的角度, 相当于时是一个菱形
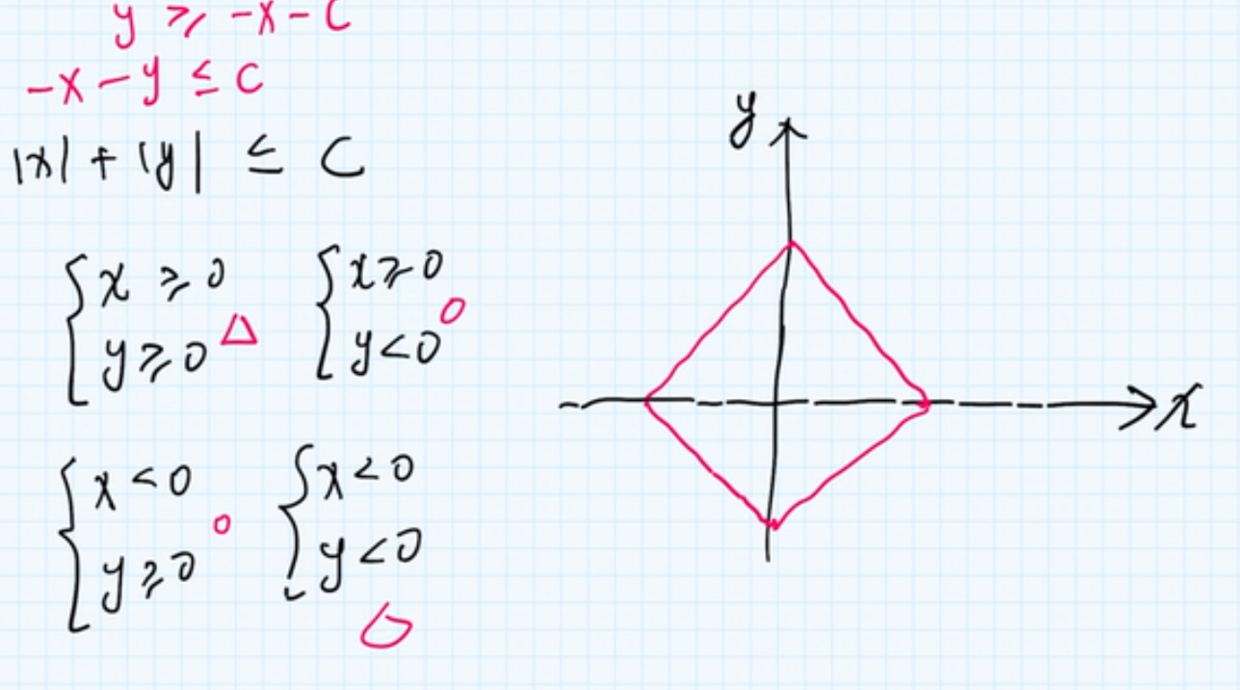
回到问题上, 损失函数是一个等高线图:
那么. 带惩罚项的损失函数的解, 就是 正则项与损失的交点
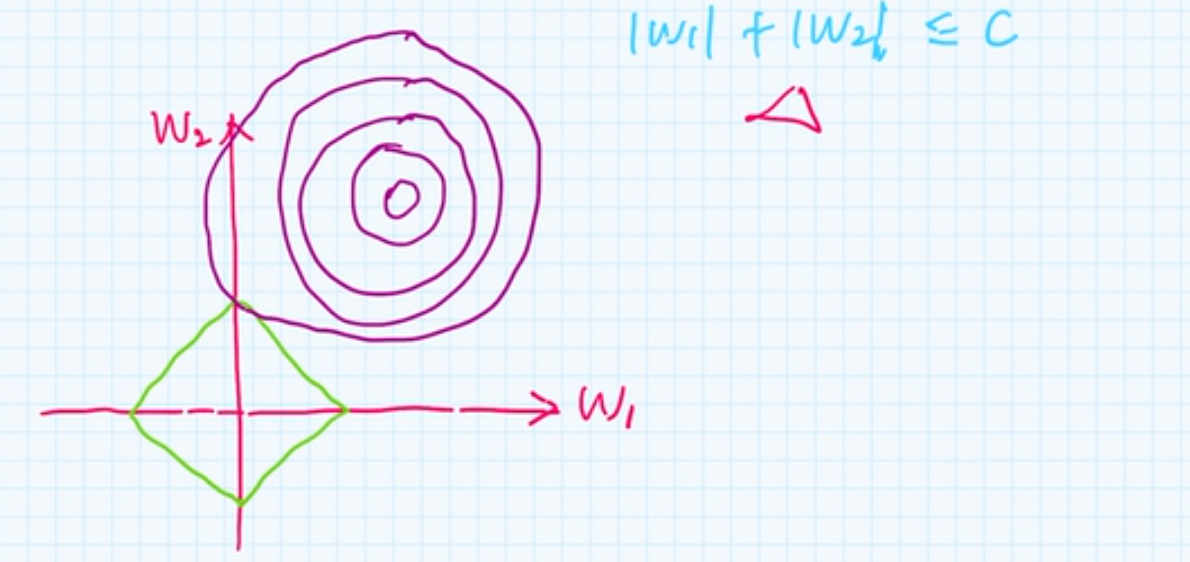
我们可以看到, 交点位置, \(w_1\)为0, 所以也得出一个结论
\(L_1\)正则可以产生稀疏向量,也就是,然某些权重元素为0, 在高维的时候, 交点越多, 也就越稀疏
\(L_2\)正则
\]
本质上,这是半径为\(C\)的圆的公式
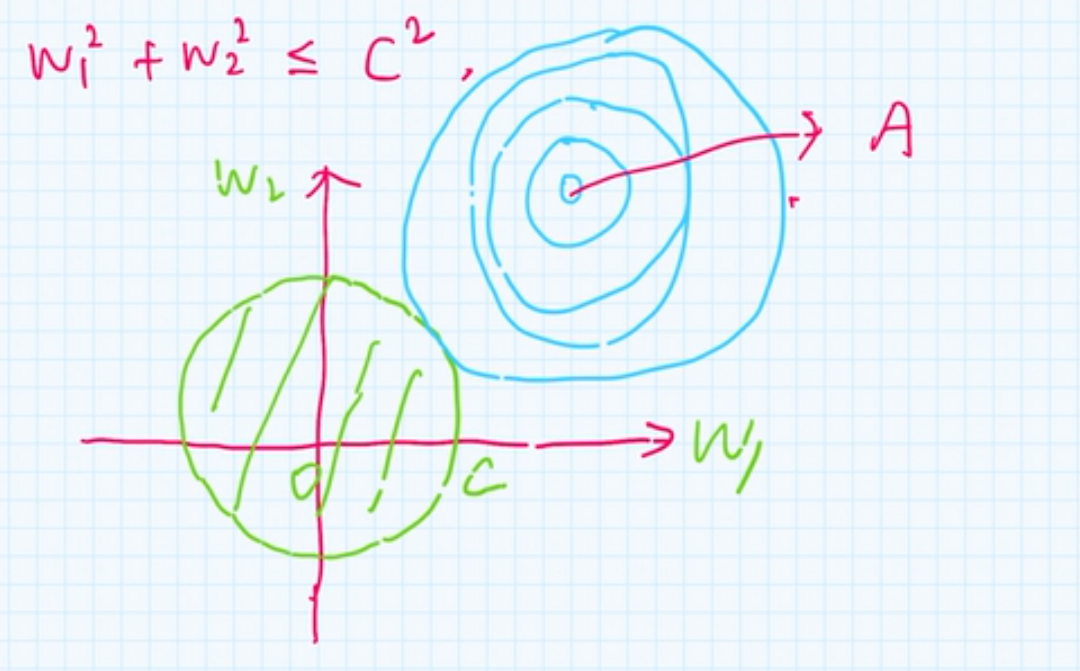
同样最优解在交点处, 且\(w_1,w_2\)不容易为0
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
L1不可导如何解决?
1. 为什么不可导?
不可导得条件是:
- 函数在该点不连续
- 即使连续,函数的左右导数不等
L1表示: y=|x|, 虽然连续,但是在0的位置, 左导数=-1 右导数等于1,不可导
2. 如何解决?
使用坐标下降法
坐标轴下降法和梯度下降法具有同样的思想,都是沿着某个方向不断迭代,但是梯度下降法是沿着当前点的负梯度方向进行参数更新,而坐标轴下降法是沿着坐标轴的方向。
先初始化参数, 然后每一轮迭代, 选择一个参数经行优化, 其他参数保持固定
https://blog.csdn.net/xiaocong1990/article/details/83039802Proximal Algorithms 近端梯度下降

L1&L2一起作用也是可以的
L1 L2正则化的更多相关文章
- 防止过拟合:L1/L2正则化
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- L0,L1,L2正则化浅析
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结. 1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数 ...
- L1,L2正则化代码
# L1正则 import numpy as np from sklearn.linear_model import Lasso from sklearn.linear_model import SG ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
随机推荐
- BIM+物联网,打开数字孪生世界之门
建筑行业一直在寻求创新和提高效率的方法,以满足日益复杂和迫切的建筑需求.近年来,数字孪生和物联网等新兴技术的崛起为建筑信息模型(BIM)应用带来了全新的可能性.数字孪生技术通过将实体建筑与其虚拟模型连 ...
- WireShark学习笔记(一)
1.从WireShark分析网络层协议的传输 下面是网络接口层协议,从图中可以看到两个相邻设备的MAC地址,因此该网络包才能以接力的方式传送到目的地址. 下面是网络层,在这个包中,主要的任务是把TCP ...
- Spring事务(六)-只读事务
@Transactional(readOnly=true)就可以把事务方法设置成只读事务.设置了只读事务,事务从开始到结束,将看不见其他事务所提交的数据.这在某种程度上解决了事务并发的问题.一个方法内 ...
- vetur 和 volar 不要一起装 - vscode插件 已解决
vetur 和 volar 不要一起装 - vscode插件 会有各种稀奇古怪的问题. 解决方案 利用 vscode 工作区 新建工作区 然后全局 将 volar 禁用工作区,起一个新的vue3项目, ...
- 一个简单的spdlog使用示例
目录 引用源码 封装Log头文件 使用方法 spdlog是一个开源.跨平台.无依赖.只有头文件的C++11日志库,网上介绍的文章有很多这里就不过多的介绍了,GitHub链接:https://githu ...
- k8s是如何保障滚动升级时下线的pod不被访问
Kubernetes (k8s) 通过一系列机制保障在滚动升级时,下线的 Pod 不再被访问.以下是一些主要的保障措施: Service 抽象:在 Kubernetes 中,Pod 通常不是直接暴露给 ...
- 基于python源码的啸叫抑制算法解析
一 原理解析 从下图一中可以看出,该算法的原理也是先检测出来啸叫,然后通过陷波器来进行啸叫抑制的,和笔者以前分析的所用方法基本耦合. 二 源码分析 函数PAPR:计算峰值功率和平均功率的比 ...
- Java使用Steam流对数组进行排序
原文地址:Java使用Steam流对数组进行排序 - Stars-One的杂货小窝 简单记下笔记,不是啥难的东西 sorted()方法里传了一个比较器的接口 File file = new File( ...
- 海量数据去重的Hash与BloomFilter
今天我们谈论一下散列表,我之前的两个博文写的都是关于平衡二叉树的 平衡二叉树 增删改查时间复杂度为log2n 平衡的目的是增删改以后,保证下次搜索能稳定排除一半的数据: 总结:通过比较保证有序,通过每 ...
- CentOS 同时安装多个版本的Python3
1.背景 已安装了 Python3.6.4,需要再安装 Python3.9 版本 2.操作步骤 (1)寻找当前 Python3.9 版本最新稳定版的子版本 通过官网查找,目前为 3.9.18,下载到本 ...