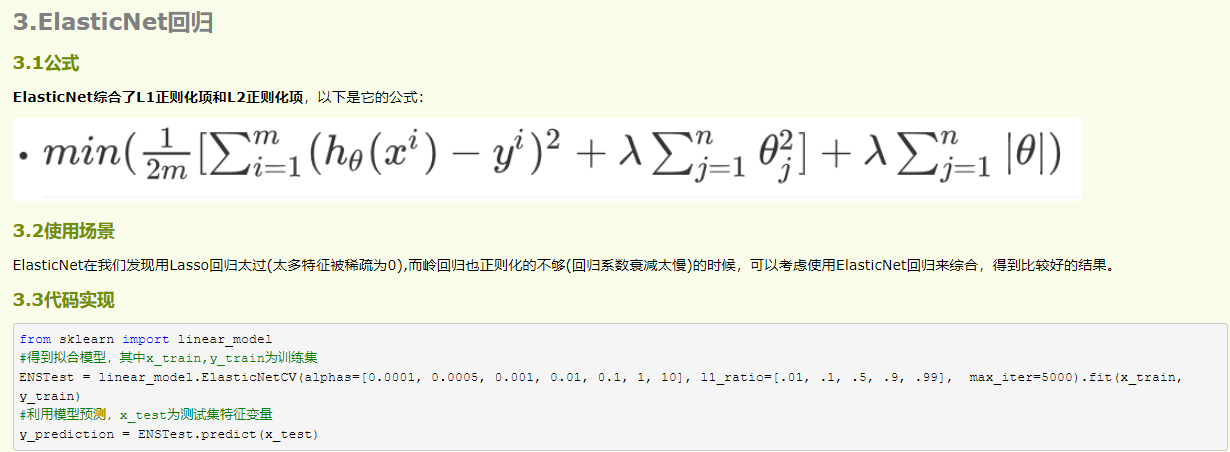
L1 L2正则化
范数
0范数
\(L_0\)范数表示为向量中非0元素的个数
\]
1范数
向量中元素绝对值的和,也就是\(x\)与0之间的曼哈顿距离
\]
2范数
\(x\)与0之间的欧式范数, 也就是向量中的每个数的平方之和
\]
p范数
\]
正则化的来源
正则化主要是用来控制模型的复杂度, 从而控制过拟合
做法:一般在损失函数中加入惩罚项
\]
\(w\)显然, 是参数, \(\alpha\)控制正则化的强弱, 是一个常数
从下图讲解:
- 准确率: 右>左
- 模型复杂度: 右>左
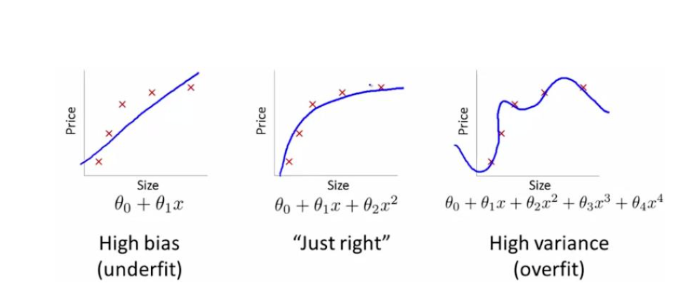
但是在测试的时候, 会出现过拟合的模型, 泛化效果变差的现象
为什么\(L_1\)和\(L_2\)能减小过拟合?
ML的目的是获得做好的参数\(w\), 并让模型的泛化能力更好
当模型复杂的时候, 相应的\(w\)也变多, 于是产生可过拟合现象, 为了降低模型的复杂度, 可以考虑适当的减少参数,代价就是准确率会适当的下降
如何减小参数?: 让\(w\)中的部分元素为0,也就是限制\(w\)中非0元素的个数
那么非0个数如何表示--> \(L_0\)范数, 于是我们有优化问题:
\min L(w,x,y) \\
||w||_0 \leq C
\end{cases}
\]
最小化损失, 并且约束是 非0元素的个数, 小于一定的值, 但是这个约束, 不好优化
于是有了\(L_1,L_2\)
初衷是限制w元素0的个数, 但可不可以这样?: 让\(w\)中的某些元素, 尽可能的趋近于0
\(||w|| \leq C\) 或者 \(||w||_2 \leq C\)
那么就可以发现, 刚好, 这是1 2 范数
那么可以得到优化问题
\min L(w,x,y) \\
||w||_1 \leq C
\end{cases}
\begin{cases}
\min L(w,x,y) \\
||w||_{2}\leq C
\end{cases}
\]
然后开始解优化问题, 一般具有约束的优化问题, 可以用拉格朗日函数
L(w,\alpha) = L(w,x,y)+\alpha(||w||_2-C) \\
\]
上式也可写成
L(w,\alpha) = L(w,x,y)+\alpha ||w||_2- \alpha C
\]
然后按没有正则化时的计算方式一样, 求偏导,令其为0,求\(w\)就可以了, 这样的化, 和\(\alpha C\)就没有关系了
树形结合
我们继续看对\(w\)的约束项
\(L_1\) 正则
\]
从2维平面的角度来看, \(L_1\)为:
\]
从数学的角度, 相当于时是一个菱形
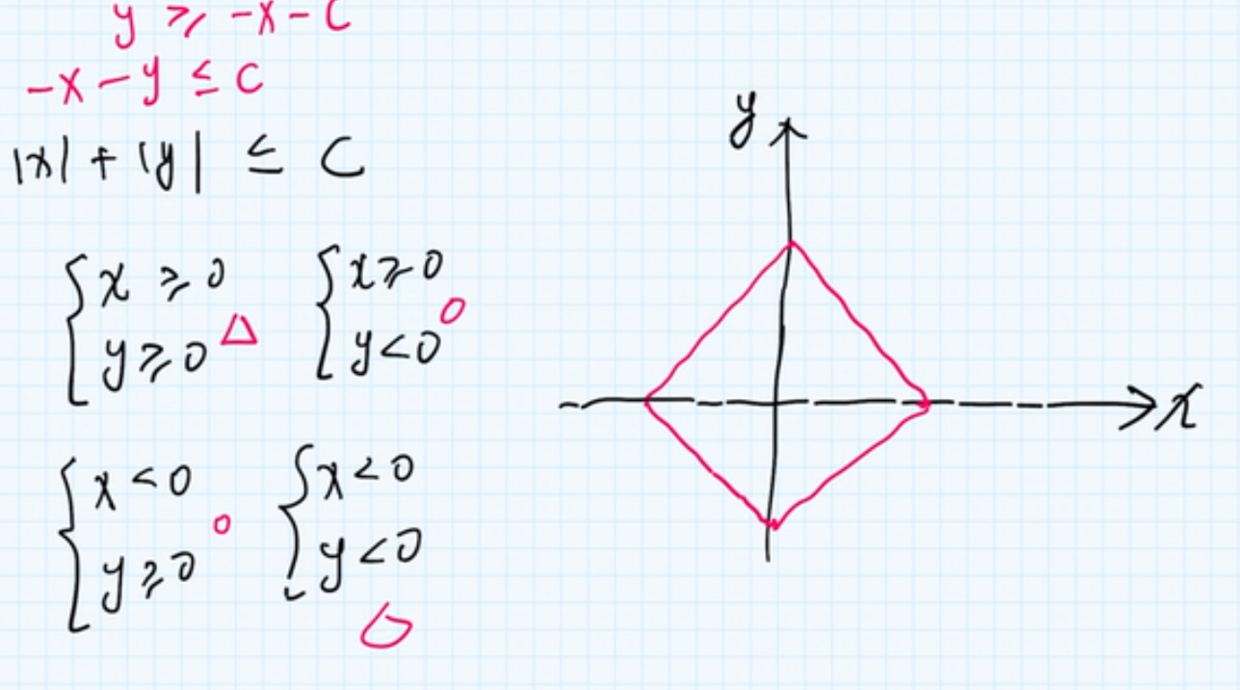
回到问题上, 损失函数是一个等高线图:
那么. 带惩罚项的损失函数的解, 就是 正则项与损失的交点
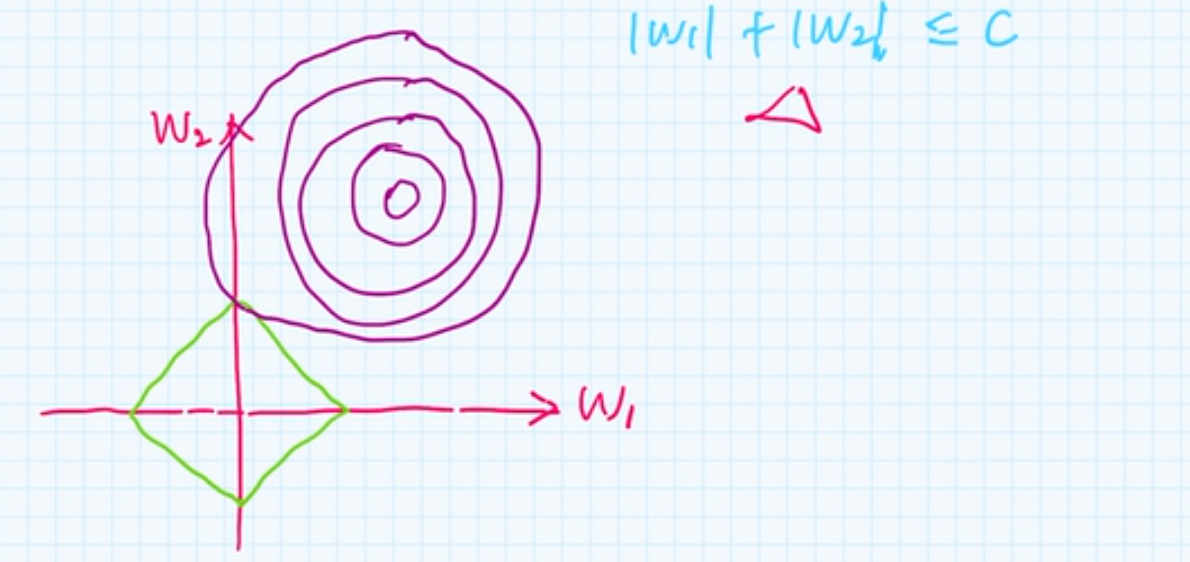
我们可以看到, 交点位置, \(w_1\)为0, 所以也得出一个结论
\(L_1\)正则可以产生稀疏向量,也就是,然某些权重元素为0, 在高维的时候, 交点越多, 也就越稀疏
\(L_2\)正则
\]
本质上,这是半径为\(C\)的圆的公式
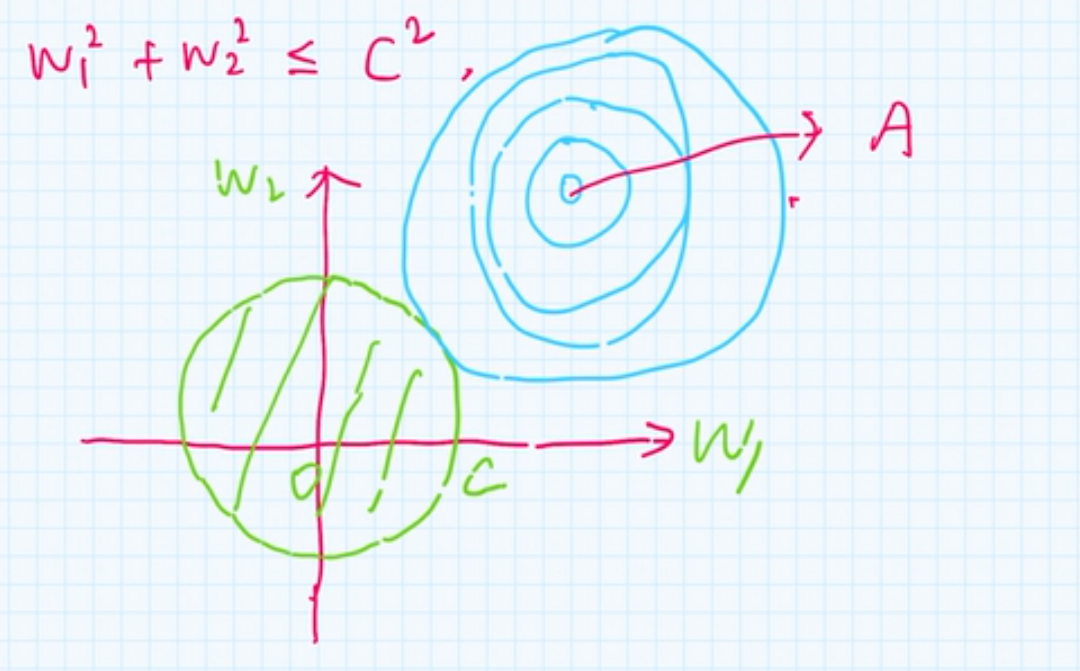
同样最优解在交点处, 且\(w_1,w_2\)不容易为0
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
L1不可导如何解决?
1. 为什么不可导?
不可导得条件是:
- 函数在该点不连续
- 即使连续,函数的左右导数不等
L1表示: y=|x|, 虽然连续,但是在0的位置, 左导数=-1 右导数等于1,不可导
2. 如何解决?
使用坐标下降法
坐标轴下降法和梯度下降法具有同样的思想,都是沿着某个方向不断迭代,但是梯度下降法是沿着当前点的负梯度方向进行参数更新,而坐标轴下降法是沿着坐标轴的方向。
先初始化参数, 然后每一轮迭代, 选择一个参数经行优化, 其他参数保持固定
https://blog.csdn.net/xiaocong1990/article/details/83039802Proximal Algorithms 近端梯度下降

L1&L2一起作用也是可以的
L1 L2正则化的更多相关文章
- 防止过拟合:L1/L2正则化
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- L0,L1,L2正则化浅析
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结. 1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数 ...
- L1,L2正则化代码
# L1正则 import numpy as np from sklearn.linear_model import Lasso from sklearn.linear_model import SG ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
随机推荐
- C++ STL 容器-string类型
C++ STL 第一部分-容器 STL的介绍 C++的STL分为六大部分 容器分为 容器的概念 容器内元素的条件 1.必须可以复制copy或者搬移move,包括条件是在拷贝和搬移的过程中不存在副作用. ...
- 面试官问我会ES么,我说不会,抓紧学起【ES(一)聚合分析篇】
ES聚合分析 1.metric(指标)聚合 1.1 单值分析 min 求指定字段的最小值 # 求价格的最小值 { "size":0, "aggs":{ &quo ...
- 基于STM32F407MAC与DP83848实现以太网通讯三(STM32F407MAC配置以及数据收发)
本章实现了基于STM32F407MAC的数据收发功能,通过开发板的RJ45接口连接网线到电脑,电脑使用Wiershark工具抓包验证,工程源码.资料和软件见文末. 参考文档: DP83848IV英文 ...
- vue-cli-plugin-electron-builder
https://nklayman.github.io/vue-cli-plugin-electron-builder/guide/#installation 用cnpm安装 cnpm install ...
- leaflet 领图 一个本地的类似百度地图工具-不连外网
官网:https://leafletjs.com/ 二次开发手册-中文:http://112.91.146.167:9090/api/ 领图(一款给力的开源离线地图解决方案) https://blog ...
- if (ctx.ifTo(ctx.property, next)) return
if (ctx.ifTo(ctx.property, next)) return if (ctx.ifGoto(ctx.property, 'functionName')) return 试试 a & ...
- C#获取Description特性的扩展类
C#中Description特性主要用于枚举和属性,方法比较简单,记录一下以便后期使用. 扩展类DescriptionExtension代码如下: using System; using System ...
- Mysql导出导入操作
安装mysql客户端 # 在终端上下载mysql源 wget https://dev.mysql.com/get/mysql80-community-release-el7-7.noarch.rpm ...
- 【个人笔记】2023年搭建基于webpack5与typescript的react项目
写在前面 由于我在另外的一些文章所讨论或分析的内容可能基于一个已经初始化好的项目,为了避免每一个文章都重复的描述如何搭建项目,我在本文会统一记录下来,今后相关的文章直接引用文本,方便读者阅读.此文主要 ...
- 深度观察2024中国系统架构师大会(SACC)
今年的中国系统架构师大会(SACC)在我所在的城市广州举办,很荣幸受邀参加.这次能接触到国内最优秀的架构师,学习他们的架构思想和行业经验.对我而言非常有意义. 大会分为上下午共4场,我参加了上午的多云 ...