pandas -- DataFrame的级联以及合并操作
开发环境
- anaconda
- 集成环境:集成好了数据分析和机器学习中所需要的全部环境
- 安装目录不可以有中文和特殊符号
- jupyter
- anaconda提供的一个基于浏览器的可视化开发工具
import pandas as pd
import numpy as np
级联操作 -- 对应表格
- pd.concat
- pd.append
- pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
- objs
- axis=0
- keys
- join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
- ignore_index=False
匹配级联
df1 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C'])
df2 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C'])
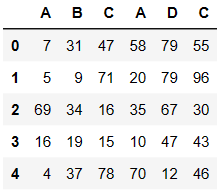
pd.concat((df1,df2),axis=1) # 行列索引都一致的级联叫做匹配级联
不匹配级联
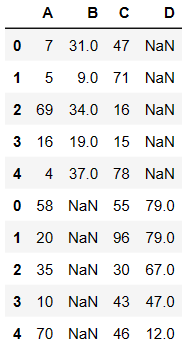
- 不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
- 有2种连接方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
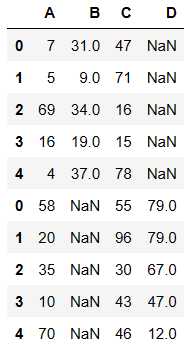
pd.concat((df1,df2),axis=0)
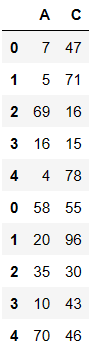
内连接
pd.concat((df1,df2),axis=0,join='inner') # inner直把可以级联的级联不能级联不处理
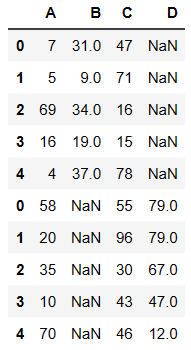
外连接
- 如果想要保留数据的完整性必须使用 outer(外连接)
pd.concat((df1,df2),axis=0,join='outer')
- append函数的使用
df1.append(df2)
合并操作 -- 对应数据
- merge与concat的区别在于,merge需要依据某一共同列来进行合并
- 使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 注意每一列元素的顺序不要求一致
一对一合并
from pandas import DataFrame
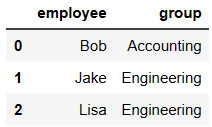
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
df1
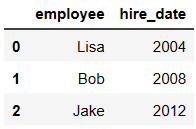
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})
df2
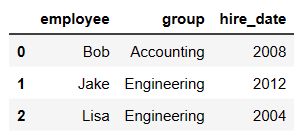
pd.merge(df1,df2,on='employee')
一对多合并
df3 = DataFrame({
'employee':['Lisa','Jake'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df3
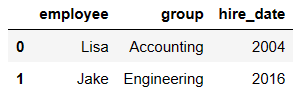
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
df4
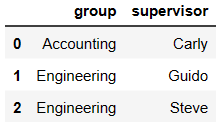
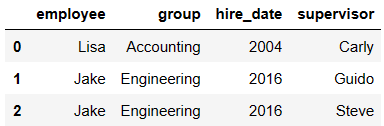
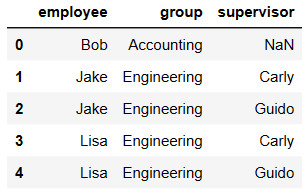
pd.merge(df3,df4) # on如果不写,默认情况下使用两表中公有的列作为合并条件
多对多合并
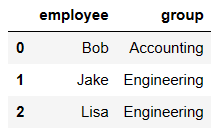
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df1
df5 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
df5
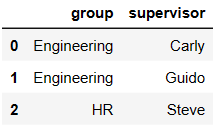
pd.merge(df1,df5,how='right')
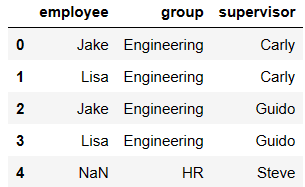
pd.merge(df1,df5,how='left')
key的规范化
- 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
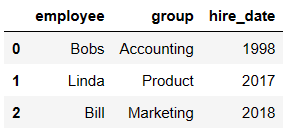
df1 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]})
df1
df5 = DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]})
df5
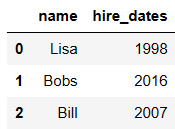
pd.merge(df1,df5,left_on='employee',right_on='name')
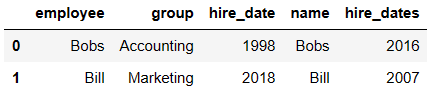
内合并与外合并
- outer取并集
- inner取交集
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
df6
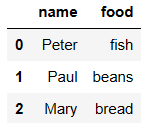
df7

pd.merge(df6,df7,how='outer')
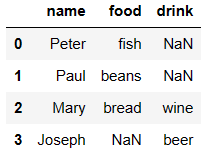
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
df6
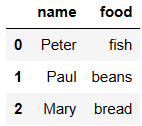
df7

pd.merge(df6,df7,how='inner')

pandas -- DataFrame的级联以及合并操作的更多相关文章
- 数据分析03 /基于pandas的数据清洗、级联、合并
数据分析03 /基于pandas的数据清洗.级联.合并 目录 数据分析03 /基于pandas的数据清洗.级联.合并 1. 处理丢失的数据 2. pandas处理空值操作 3. 数据清洗案例 4. 处 ...
- pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas 学习 第7篇:DataFrame - 数据处理(应用、操作索引、重命名、合并)
DataFrame的这些操作和Series很相似,这里简单介绍一下. 一,应用和应用映射 apply()函数对每个轴应用一个函数,applymap()函数对每个元素应用一个函数: DataFrame. ...
- Pandas | Dataframe的merge操作,像数据库一样尽情join
今天是pandas数据处理第8篇文章,我们一起来聊聊dataframe的合并. 常见的数据合并操作主要有两种,第一种是我们新生成了新的特征,想要把它和旧的特征合并在一起.第二种是我们新获取了一份数据集 ...
- pandas之合并操作
Pandas 提供的 merge() 函数能够进行高效的合并操作,这与 SQL 关系型数据库的 MERGE 用法非常相似.从字面意思上不难理解,merge 翻译为"合并",指的是将 ...
- pandas DataFrame 数据处理常用操作
Xgboost调参: https://wuhuhu800.github.io/2018/02/28/XGboost_param_share/ https://blog.csdn.net/hx2017/ ...
- Python pandas DataFrame操作
1. 从字典创建Dataframe >>> import pandas as pd >>> dict1 = {'col1':[1,2,5,7],'col2':['a ...
- Python时间处理,datetime中的strftime/strptime+pandas.DataFrame.pivot_table(像groupby之类 的操作)
python中datetime模块非常好用,提供了日期格式和字符串格式相互转化的函数strftime/strptime 1.由日期格式转化为字符串格式的函数为: datetime.datetime.s ...
- pandas.DataFrame的pivot()和unstack()实现行转列
示例: 有如下表需要进行行转列: 代码如下: # -*- coding:utf-8 -*- import pandas as pd import MySQLdb from warnings impor ...
- 如何迭代pandas dataframe的行
from:https://blog.csdn.net/tanzuozhev/article/details/76713387 How to iterate over rows in a DataFra ...
随机推荐
- 3. docker的实践玩法
1. docker的进程架构 docker服务进程:就是针对docker服务的命令,启动,重启 接口:通过参数指定容器的IP和端口,实现对容器的远程操作 客户端命令行:对docker的操作命令 最后学 ...
- 在Istio中,到底怎么获取 Envoy 访问日志?
Envoy 访问日志记录了通过 Envoy 进行请求 / 响应交互的相关记录,可以方便地了解具体通信过程和调试定位问题. 环境准备 部署 httpbin 服务: kubectl apply -f sa ...
- Jenkins部署前后端不分离springboot项目
背景 写这篇博客的时候我还是大学生,学校期末课程设计时要求使用Jenkins部署项目,所以使用windows,但是企业中都是使用linux,往往还会搭建一个gitlab.下面我介绍的是在window环 ...
- 洛谷 P5065 不归之人与望眼欲穿的人们
题意 一个长 \(n\) 的正整数序列 \(a\),支持单点修改数值,询问所有按位或值大于等于 \(k\) 的区间长度最短为多少. 数据范围:\(1\le n\le 50000, 0\le a_i, ...
- 详解同为4800W像素的相机传感器,三星GM1和索尼IMX586区别在哪里?
数字影像之父Bryce Bayer基于RGB模式,通过在感光元件前加上一个滤镜的方法终于实现了彩色照片.Bayer滤镜跨出了照片从黑白到彩色的一大步,但是对于挑剔的人眼来说,每个像素只有一个颜色是远远 ...
- pandas 根据内容匹配并获取索引
bool = ExcelDataStr.str.contains("Item No./Customer/Saler") # 初始位置:initial position, 终位置:e ...
- 零基础入门——从零开始学习PHP反序列化笔记(一)
靶场环境搭建 方法一:PHPstudy搭建 GitHub地址 https://github.com/mcc0624/php_ser_Class 方法二:Docker部署 pull镜像文件 docker ...
- CentOS安装ffmpeg并转码视频为mp4
前言 现需要将一批avi格式的视频转码为mp4,以下为操作步骤.系统版本为CentOS 7. 如果不安装x264,转码后只有声音,没有视频. 编译安装nasm wget https://www.nas ...
- WPF如何构建MVVM+模块化的桌面应用
为何模块化 模块化是一种分治思想,不仅可以分离复杂的业务逻辑,还可以进行不同任务的分工.模块与模块之间相互独立,从而构建一种松耦合的应用程序,便于开发和维护. 开发技术 .Net 6 + WPF + ...
- 【pytorch】目标检测:YOLO的基本原理与YOLO系列的网络结构
利用深度学习进行目标检测的算法可分为两类:two-stage和one-stage.two-stage类的算法,是基于Region Proposal的,它包括R-CNN,Fast R-CNN, Fast ...