(五)Lucene——中文分词器
1. 什么是中文分词器
对于英文,是安装空格、标点符号进行分词
对于中文,应该安装具体的词来分,中文分词就是将词,切分成一个个有意义的词。
比如:“我的中国人”,分词:我、的、中国、中国人、国人。
2. Lucene自带的中文分词器
- StandardAnalyzer:
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
- CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上边两个分词器无法满足需求。
3. 第三方中文分词器
- paoding: 庖丁解牛最新版在 https://code.google.com/p/paoding/ 中最多支持Lucene 3.0,且最新提交的代码在 2008-06-03,在svn中最新也是2010年提交,已经过时,不予考虑。
- mmseg4j:最新版已从 https://code.google.com/p/mmseg4j/ 移至 https://github.com/chenlb/mmseg4j-solr,支持Lucene 4.10,且在github中最新提交代码是2014年6月,从09年~14年一共有:18个版本,也就是一年几乎有3个大小版本,有较大的活跃度,用了mmseg算法。
- IK-analyzer: 最新版在https://code.google.com/p/ik-analyzer/上,支持Lucene 4.10从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 但是也就是2012年12月后没有在更新。
- ansj_seg:最新版本在 https://github.com/NLPchina/ansj_seg tags仅有1.1版本,从2012年到2014年更新了大小6次,但是作者本人在2014年10月10日说明:“可能我以后没有精力来维护ansj_seg了”,现在由”nlp_china”管理。2014年11月有更新。并未说明是否支持Lucene,是一个由CRF(条件随机场)算法所做的分词算法。
- imdict-chinese-analyzer:最新版在 https://code.google.com/p/imdict-chinese-analyzer/ , 最新更新也在2009年5月,下载源码,不支持Lucene 4.10 。是利用HMM(隐马尔科夫链)算法。
- Jcseg:最新版本在git.oschina.net/lionsoul/jcseg,支持Lucene 4.10,作者有较高的活跃度。利用mmseg算法。
4. Ikanalyzer的使用
4.1 将jar包拷贝到项目路径下并发布
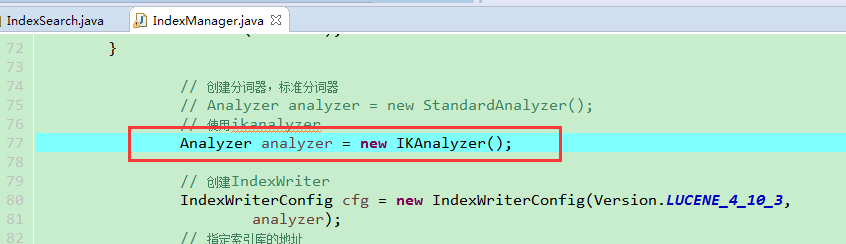
4.2 代码中使用Ikanalyzer替换标准分词器
4.3 扩展中文词库
config文件夹下创建以下文件(扩展词文件和停用词文件的编码要是utf-8。注意:不要用记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。)

IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
4.4 使用luke来查询中文分词效果
step1:将ikanalyzer的jar包,拷贝到luke工具的目录

step2:使用命令打开luke工具
java -Djava.ext.dirs=. -jar lukeall-4.10.3.jar
(五)Lucene——中文分词器的更多相关文章
- 11大Java开源中文分词器的使用方法和分词效果对比,当前几个主要的Lucene中文分词器的比较
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- Lucene的中文分词器IKAnalyzer
分词器对英文的支持是非常好的. 一般分词经过的流程: 1)切分关键词 2)去除停用词 3)把英文单词转为小写 但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好. 国人林良益写的IK Ana ...
- Lucene全文检索_分词_复杂搜索_中文分词器
1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 1.1.1 定义 全文检索就是先分词创建索引,再执行搜索的过 ...
- Lucene索引库维护、搜索、中文分词器
删除索引(文档) 需求 某些图书不再出版销售了,我们需要从索引库中移除该图书. 1 @Test 2 public void deleteIndex() throws Exception { 3 // ...
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
注意:基于lucene5.5.x版本 一.简单介绍下IK Analyzer IK Analyzer是linliangyi2007的作品,再此表示感谢,他的博客地址:http://linliangyi2 ...
- Lucene的中文分词器
1 什么是中文分词器 学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开. 而中文的语义比较特殊,很难像英文那样,一个汉字一个汉字来划分. 所以需要一个能自动识别中文语义的分 ...
- Lucene 03 - 什么是分词器 + 使用IK中文分词器
目录 1 分词器概述 1.1 分词器简介 1.2 分词器的使用 1.3 中文分词器 1.3.1 中文分词器简介 1.3.2 Lucene提供的中文分词器 1.3.3 第三方中文分词器 2 IK分词器的 ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
随机推荐
- java中ThreadLocal类的使用
ThreadLocal是解决线程安全问题一个很好的思路,ThreadLocal类中有一个Map,用于存储每一个线程的变量副本,Map中元素的键为线程对象,而值对应线程的变量副本,由于Key值不可重复, ...
- 2017 ACM-ICPC ECFINAL过山车体验
这次采用domjudge判题,算是比较好玩的啦.外榜地址:http://board.acmicpc.cn/ 然后我们很可惜地止步于192名QAQ,没看出C是个傻逼题,没读懂B..我得背锅,亏我还打了那 ...
- BZOJ 2120 数颜色(带修改莫队)
[题目链接] http://www.lydsy.com/JudgeOnline/problem.php?id=2120 [题目大意] 给出一颜色序列,每次可以修改一个位置的颜色或者询问一个区间不同颜色 ...
- 网络编程之tcp五层模型
网络编程 1.客户端与服务端架构:C/S B/S 架构 client <-------基于网络通信-------->server brower<-------基于网络通信--- ...
- Android Studio 导出APK
(1)Android Studio菜单Build->Generate Signed APK (2)弹出窗口 (3)创建密钥库及密钥,创建后会自动选择刚创建的密钥库和密钥(已拥有密 ...
- Android Studio初级介绍
Android Studio原来不咋地,但是现在可以尝试抛弃eclipse转用它了, 亲儿子到底是亲儿子,现在的Android Studio已经今非昔比,用了一段时间,简直爱不释手,我觉得,It's ...
- BZOJ 4028: [HEOI2015]公约数数列 分块
4028: [HEOI2015]公约数数列 题目连接: http://www.lydsy.com/JudgeOnline/problem.php?id=4028 Description 设计一个数据结 ...
- opencv中keypoint数据结构分析
分析opencv中keypoint数据结构的相关信息,找到opencv的document(http://docs.opencv.org/java/org/opencv/features2d/KeyPo ...
- 在u-boot中添加命令
转:http://www.embedu.org/Column/Column464.htm 作者:曾宏安,华清远见嵌入式学院讲师. u-boot是嵌入式系统中广泛使用的一种bootloader.它不仅支 ...
- Http和Https网络同步请求httpclient和异步请求async-http-client
原文:https://blog.csdn.net/fengshizty/article/details/53100694 Http和https网络请求 主要总结一下使用到的网络请求框架,一种是同步网络 ...