requests,lxml爬启信宝
首先,
添加requests模块:
然后,
添加lxml模块:
启信宝登录抓包:
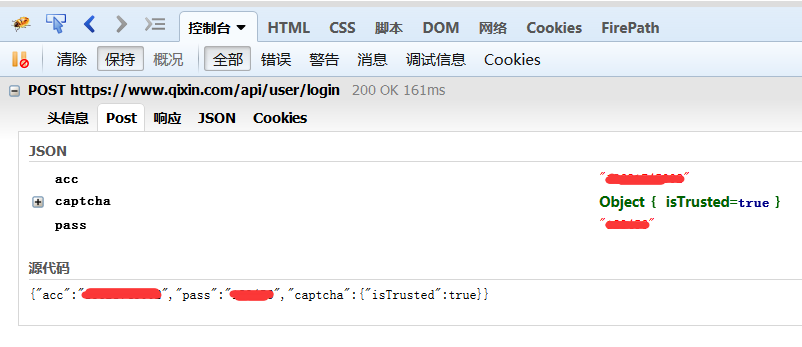
QiXinBao.py:
import requests
from lxml import etree loginUrl = "https://www.qixin.com/api/user/login"
# 启信宝登录接口
homePage = "https://www.qixin.com"
# 启信宝首页 headers = {"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Content-Length": "66",
"Content-Type": "application/json;charset=utf-8",
"Host": "www.qixin.com",
"Referer": "https://www.qixin.com/auth/login?return_url=%2Fnew-vip",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:52.0) Gecko/20100101 Firefox/52.0",
"X-Requested-With": "XMLHttpRequest",
"dc49417fe4f34f86b0fe": "44282ce68be84e73f8eb4d2a4d4b32c02e8e84970160b2d6829c6b8a5380483e50ec708bc38040dd715d283dfac3123cf422ecff2fe4977c8624e457c5046959"
}
# 请求头(伪装成浏览器)
parameter = {"acc": "13688888888", "pass": "000000", "captcha": {"isTrusted": True}}
# 请求体 session = requests.Session()
# 保持会话
response_1 = session.post(loginUrl, headers=headers, json=parameter, timeout=5)
# 登录
print(response_1.status_code)
# 打印响应码 response_2 = session.get(homePage).content
# 打开启信宝首页
page_2 = etree.HTML(response_2)
link = page_2.xpath("//html/body/div[1]/div[4]/div/div[2]/div/div[1]/div[1]/a//@href")
companyUrl = homePage+link[0]
# 获取第一家公司的URL response_3 = session.get(companyUrl).content
# 打开第一家公司
page_3 = etree.HTML(response_3)
companyName = page_3.xpath("//html/body/div[6]/div/div[2]/div/div/h4//text()")
# 获取公司名称
code_1 = page_3.xpath("//*[@id='icinfo']/table/tbody/tr[1]/td[2]//text()")
# 获取统一社会信用代码
code_2 = page_3.xpath("//*[@id='icinfo']/table/tbody/tr[2]/td[2]//text()")
# 获取注册号 print(companyName[0]+"\n"+code_1[0]+"\n"+code_2[0])
requests,lxml爬启信宝的更多相关文章
- selenium + ChromeDriver 实战系列之启信宝(一)
之前写了一篇selenium + ChromeDriver的一些入门的知识,这篇博客里面找了启信宝这个网站,简单的进行了一个实战练习.本篇博客的结构如下: 首先会给出一些使用seleniu ...
- requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html from lxml import etree #创建一个html对象 html=stree.HTML(text) result=etree.tostring(html,en ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- <day003>登录+爬取淘宝商品信息+字典用json存储
任务1:利用cookie可以免去登录的烦恼(验证码) ''' 只需要有登录后的cookie,就可以绕过验证码 登录后的cookie可以通过Selenium用第三方(微博)进行登录,不需要进行淘宝的滑动 ...
- [实战演练]python3使用requests模块爬取页面内容
本文摘要: 1.安装pip 2.安装requests模块 3.安装beautifulsoup4 4.requests模块浅析 + 发送请求 + 传递URL参数 + 响应内容 + 获取网页编码 + 获取 ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
随机推荐
- springmvc(3)注解
有疑问可以参考博主其他关于spring mvc的博文 此时直接进行代码的实现 一般的步骤: -加入jar包 -配置DispatcherServlet -加入Spring MVC配置文件 -编写请求的处 ...
- #20145238荆玉茗《网络对抗》-逆向及Bof进阶实践
20145238荆玉茗<网络对抗>-逆向及Bof进阶实践 实践目的:注入shellcode 准备一段shellcode代码 Shellcode实际是一段代码(也可以是填充数据),是用来发送 ...
- jQuery中append()、prepend()与after()、before()的区别
转载 未曾见海 https://www.cnblogs.com/afei-qwerty/p/6682963.html 在jQuery中,添加元素有append(),prepend() 和 after ...
- usb入门学习
1.学习资源: usb org.http://www.beyondlogic.org/usbnutshell/usb3.shtml http://wenku.baidu.com/view/028231 ...
- XML解析方式
两种解析方式概述 dom解析 (1)是W3C组织推荐的处理XML的一种解析方式. (2)将整个XML文档使用类似树的结构保存在内存中,在对其进行操作. (3)可以方便的对XML进行增删改查的操作 (4 ...
- ARM对异常的处理
所谓中断就是中断SoC的CPU核(异常可以引起CPU的中断) ARM对异常的处理 1.初始化: 1)设置中断源让它可以产生中断.如某个按键可以产生中断,那么可以设置它的GPIO引脚为中断引脚: 2)设 ...
- 【转载】决策树Decision Tree学习
本文转自:http://www.cnblogs.com/v-July-v/archive/2012/05/17/2539023.html 最近在研究规则引擎,需要学习决策树.决策表等算法.发现篇好文对 ...
- python多线程知识-实用实例
python多线程使用场景:IO操作,不适合CPU密集操作型任务 1.多个线程内存共享 2.线程同时修改同一份数据需要加锁,mutex互斥锁 3.递归锁:多把锁,锁中有锁 4.python多线程, ...
- 『ACM C++』 Codeforces | 1003C - Intense Heat
今日兴趣新闻: NASA 研制最强推进器,加速度可达每秒 40 公里,飞火星全靠它 链接:https://mbd.baidu.com/newspage/data/landingsuper?contex ...
- hashcode和equals区别
hashcode:对象的初始地址的整数表示 Java中的对象是JVM在管理,JVM会在她认为合适的时候对对象进行移动,比如,在某些需要整理内存碎片的GC算法下发生的GC.此时,对象的地址会变动,但ha ...