requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html
from lxml import etree
#创建一个html对象
html=stree.HTML(text)
result=etree.tostring(html,encoding="utf-8").decode("utf-8")
requests+lxml+xpath实现豆瓣电影爬虫
import requests
from lxml import etree
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
}
原始界面:
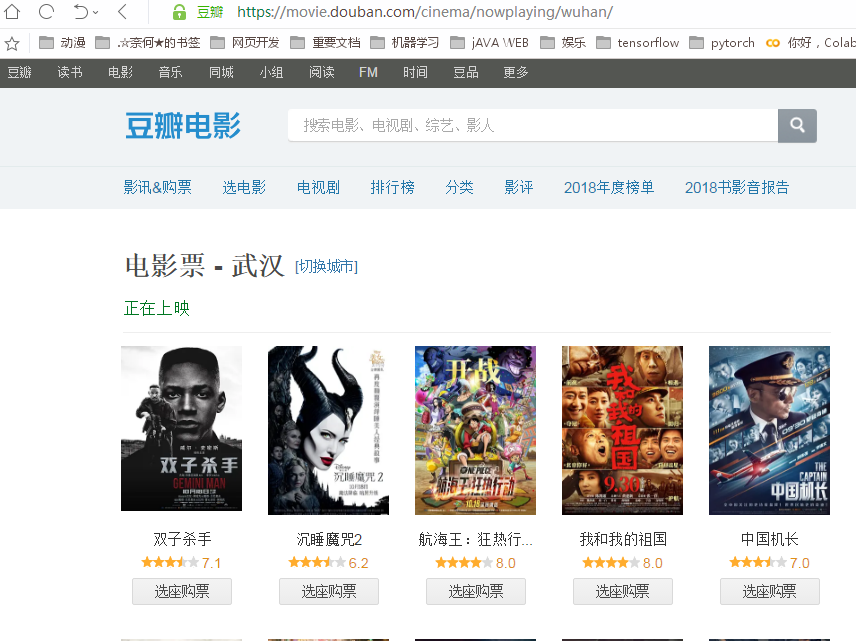
url="https://movie.douban.com/cinema/nowplaying/wuhan/"
response=request.get(url,headers=headers)
text=response.text
html=etree.HTML(text)
我们会得到一个html对象

转换成字符串看下结果
result=etree.tostring(html,encoding="utf-8").decode("utf-8")
部分结果如下:

然后进行xpath解析:
我们对准其中一部电影点击鼠标右键--检查,得到如下视图:

我们发现,上映电影的信息都在带有属性lists的ul中,我们可以对此进行xpath解析,(我们解析的是html对象,而不是转成字符串的结果):
uls=html.xpath("//ul[@class='lists']")[0]
我们在转成字符串查看一下结果:
res=etree.tostring(uls,encoding="utf-8").decode("utf-8")
print(res)

正是我们想要的,我们接着解析里面的内容:
首先获取所有的li:
#这句的意思是获取当前uls下的所有直接li
lis=uls.xpath("./li)
结果是一系列的li对象:

我们再分别进行解析:
movies=[]
for li in lis:
name=li.xpath("@data-title")[0]
score=li.xpath("@data-score")[0]
country=li.xpath("@data-region")[0]
director=li.xpath("@data-director")[0]
actors=li.xpath("@data-actors")[0]
category=li.xpath("@data-category")[0]
movie={
"name":name,
"score":score,
"country":country,
"director":director,
"actors":actors,
"category":category
}
movies.append(movie)
print(movies)
部分结果如下:

在json中格式化结果如下:

至此,一个初步的爬虫就完成了。
requests+lxml+xpath爬取豆瓣电影的更多相关文章
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- requests+lxml+xpath爬取电影天堂
1.导入相应的包 import requests from lxml import etree 2.原始ur url="https://www.dytt8.net/html/gndy/dyz ...
- requests结合xpath爬取豆瓣最新上映电影
# -*- coding: utf-8 -*- """ 豆瓣最新上映电影爬取 # ul = etree.tostring(ul, encoding="utf-8 ...
- python3+requests+BeautifulSoup+mysql爬取豆瓣电影top250
基础页面:https://movie.douban.com/top250 代码: from time import sleep from requests import get from bs4 im ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
随机推荐
- 基于计算机操作系统的Linux的进程管理
一.实验目的 1.熟悉和理解进程和进程树的概念,掌握有关进程的管理机制. 2.了解进程与程序.并行与串行执行的区别. 3.掌握使用Linux命令管理和操作进程的方法 二.实验内容 1. 用ps命令观察 ...
- layui-table 对表格数据进行处理之后的排序问题
使用layui table过程中,将某一列的数据格式进行转换,或者将0/1状态改为是/否,或者将数字改为星星评分显示的时候都会遇到一个问题,我的表格数据转换成其他形式,同时设置了sort:true,此 ...
- 序列标注(BiLSTM-CRF/Lattice LSTM)
前言 在三大特征提取器中,我们已经接触了LSTM/CNN/Transormer三种特征提取器,这一节我们将介绍如何使用BiLSTM实现序列标注中的命名实体识别任务,以及Lattice-LSTM的模型原 ...
- python 处理excel踩过的坑——data_only,公式全部丢失
用openpyxl读取excel的load_workbook有个data_only参数. yb_wb = load_workbook(u"D:\\Desktop\\xxx.xlsx" ...
- Video/audio标签的一些基础使用心得
常用方法 .play():用于音频视频的播放 .pause():用于音频视频的暂停 常用属性 <audio src="Batmobile Battle Mode Reveal Musi ...
- Springboot + Mysql8实现读写分离
在实际的生产环境中,为了确保数据库的稳定性,我们一般会给数据库配置双机热备机制,这样在master数据库崩溃后,slave数据库可以立即切换成主数据库,通过主从复制的方式将数据从主库同步至从库,在业务 ...
- IOS上传到App Store出现证书未安装问题
今天在提交自己的APP到苹果商店去审核的时候,编译成功后.upload过程中,提示 XXX Select the certificates you wish to include in this pr ...
- Apache Kylin 概述
1 Kylin是什么 今天,随着移动互联网.物联网.AI等技术的快速兴起,数据成为了所有这些技术背后最重要,也是最有价值的"资产".如何从数据中获得有价值的信息?这个问题驱动了相关 ...
- 利用C++实现模块隐藏(R3层断链)
一.模块隐藏的实现原理 普通API查找模块实现思路:其通过查询在R3中的PEB(Process Environment Block 进程环境块)与TEB(Thread Environment Bloc ...
- Linux入门(历史与现状)
Linux 入门之 历史与现状 Linux是一个计算机的操作系统,与windows类似,是一款系统软件.操作系统首先是一个计算机程序,使用计算机语言开发,比如C语言.VC语言.是计算机硬件和应用软 ...