【Storm篇】--Storm中的同步服务DRPC
一、前述
Drpc(分布式远程过程调用)是一种同步服务实现的机制,在Storm中客户端提交数据请求之后,立刻取得计算结果并返回给客户端。同时充分利用Storm的计算能力实现高密度的并行实时计算。
二、具体原理
DRPC 是通过一个 DRPC 服务端(DRPC server)来实现分布式 RPC 功能的。
DRPC Server 负责接收 RPC 请求,并将该请求发送到 Storm中运行的 Topology,等待接收 Topology 发送的处理结果,并将该结果返回给发送请求的客户端。
(其实,从客户端的角度来说,DPRC 与普通的 RPC 调用并没有什么区别。)
DRPC设计目的是为了充分利用Storm的计算能力实现高密度的并行实时计算。
(Storm接收若干个数据流输入,数据在Topology当中运行完成,然后通过DRPC将结果进行输出。)
流程图如下: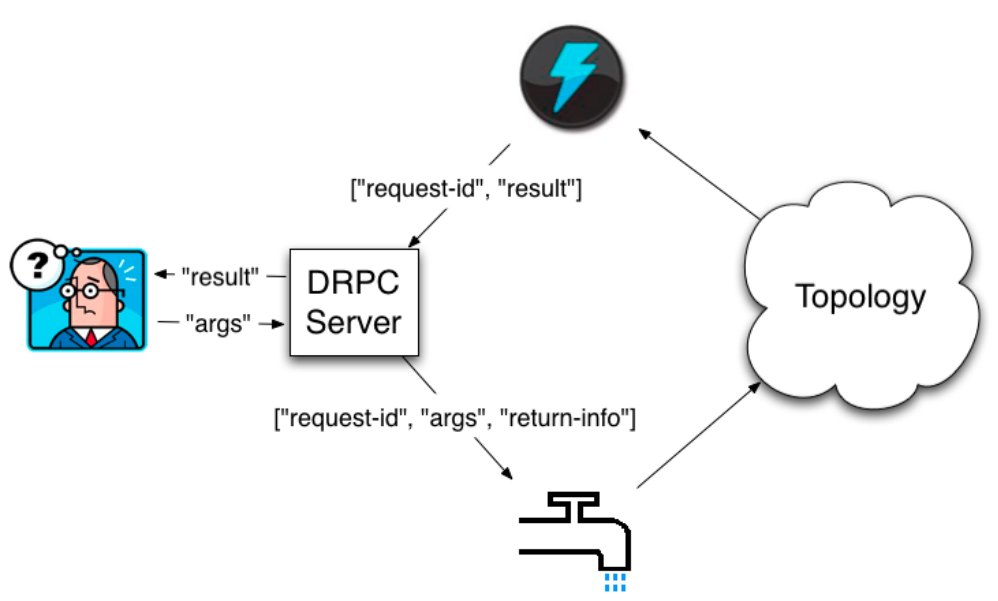
解释:
客户端通过向 DRPC 服务器发送待执行函数的名称以及该函数的参数来获取处理结果。实现该函数的拓扑使用一个DRPCSpout 从 DRPC 服务器中接收一个函数调用流。DRPC 服务器会为每个函数调用都标记了一个唯一的 id。随后拓扑会执行函数来计算结果,并在拓扑的最后使JoinResult的Bolt实现数据的聚合, ReturnResults 的 bolt 连接到 DRPC 服务器,根据函数调用的 id 来将函数调用的结果返回。
三、实现方式
方法1.
通过LinearDRPCTopologyBuilder (该方法也过期,不建议使用)
该方法会自动为我们设定Spout、将结果返回给DRPC Server等,我们只需要将Topology实现
package com.sxt.storm.drpc; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.StormSubmitter;
import backtype.storm.drpc.LinearDRPCTopologyBuilder;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class BasicDRPCTopology {
public static class ExclaimBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String input = tuple.getString(1);
collector.emit(new Values(tuple.getValue(0), input + "!"));
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "result"));
} } public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");//通过LinearDRPCTopologyBuilder 定义拓扑 //exclamation是函数名称
builder.addBolt(new ExclaimBolt(), 3); Config conf = new Config(); if (args == null || args.length == 0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster(); cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));//这是拓扑名称 for (String word : new String[] { "hello", "goodbye" }) {
System.err.println("Result for \"" + word + "\": " + drpc.execute("exclamation", word));
} cluster.shutdown();
drpc.shutdown();
} else {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createRemoteTopology());
}
}
}
方法2:
直接通过普通的拓扑构造方法TopologyBuilder来创建DRPC拓扑
需要手动设定好开始的DRPCSpout以及结束的ReturnResults
package com.sxt.storm.drpc; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.drpc.DRPCSpout;
import backtype.storm.drpc.ReturnResults;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class ManualDRPC {
public static class ExclamationBolt extends BaseBasicBolt { @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("result", "return-info"));
} @Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String arg = tuple.getString(0);
Object retInfo = tuple.getValue(1);
collector.emit(new Values(arg + "!!!", retInfo));
} } public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
LocalDRPC drpc = new LocalDRPC(); DRPCSpout spout = new DRPCSpout("exclamation", drpc);//自定义drpc spout
builder.setSpout("drpc", spout);
builder.setBolt("exclaim", new ExclamationBolt(), 3).shuffleGrouping("drpc");
builder.setBolt("return", new ReturnResults(), 3).shuffleGrouping("exclaim");//自定义结束的ReturnResults
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
cluster.submitTopology("exclaim", conf, builder.createTopology()); System.err.println(drpc.execute("exclamation", "aaa"));
System.err.println(drpc.execute("exclamation", "bbb")); }
}
四、Storm运行模式
1、本地模式
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
LocalDRPC drpc = new LocalDRPC();
DRPCSpout spout = new DRPCSpout("exclamation", drpc);
builder.setSpout("drpc", spout);
builder.setBolt("exclaim", new ExclamationBolt(), 3).shuffleGrouping("drpc");
builder.setBolt("return", new ReturnResults(), 3).shuffleGrouping("exclaim");
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
cluster.submitTopology("exclaim", conf, builder.createTopology());
System.err.println(drpc.execute("exclamation", "aaa"));
System.err.println(drpc.execute("exclamation", "bbb"));
}
2.远程模式(集群模式)
修改配置文件conf/storm.yaml
drpc.servers:
- "node1“
启动DRPC Server
bin/storm drpc &
通过StormSubmitter.submitTopology提交拓扑
public static void main(String[] args) {
DRPCClient client = new DRPCClient("node1", 3772);//通信端口
try {
String result = client.execute("exclamation", "11,22");
System.out.println(result);
} catch (TException e) {
e.printStackTrace();
} catch (DRPCExecutionException e) {
e.printStackTrace();
}
总结:Drpc分布式远程调用帮我们
1、 实现了drpcSpout用来向后发送数据,我们只需要传参即可。
2、 实现了最后的JoinResult用来汇合结果,ReturnResult用来将结果返回客户端。从而达到实时的目的。
3.、我们可以修改并行度,使集群的并行计算能力达到最优,主要实现并行计算。
【Storm篇】--Storm中的同步服务DRPC的更多相关文章
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- 【Storm篇】--Storm从初始到分布式搭建
一.前述 Storm是一个流式处理框架,相比较于SparkStreaming是一个微批处理框架,hadoop是一个批处理框架. 二 .搭建流程 1.集群规划 Nimbus Supervisor ...
- 《ArcGIS Runtime SDK for Android开发笔记》——数据制作篇:发布具有同步能力的FeatureService服务
1.前言 从ArcGIS 10.2.1开始推出离在线一体化技术之后,数据的离在线一体化编辑一直是大家所关注的一个热点.数据存储在企业级地理数据库中,通过ArcGIS桌面软件加载后配图处理,并发布到Ar ...
- 基于Storm的工程中使用log4j
最近使用Storm开发,发现log4j死活打不出debug级别的日志,网上搜到的关于log4j配置的方法都试过了,均无效. 最终发现问题是这样的:最新的storm使用的日志系统已经从log4j切换到了 ...
- storm - 使用过程中的一点思考
引子 这几天为了优化原有的数据处理框架,比较系统的学习了storm的一些内容,整理一下心得 1. storm提供的是一种数据处理思想,它不提供具体的解决方案 storm的核心是topo的定义,而top ...
- 【Storm篇】--Storm并发机制
一.前述 为了提高Storm的并行能力,通常需要设置并行. 二.具体原理 1. Storm并行分为几个方面: Worker – 进程一个Topology拓扑会包含一个或多个Worker(每个Worke ...
- 第五篇:CUDA 并行程序中的同步
前言 在并发,多线程环境下,同步是一个很重要的环节.同步即是指进程/线程之间的执行顺序约定. 本文将介绍如何通过共享内存机制实现块内多线程之间的同步. 至于块之间的同步,需要使用到 global me ...
- 分布式流式处理框架:storm简介 + Storm术语解释
简介: Storm是一个免费开源.分布式.高容错的实时计算系统.它与其他大数据解决方案的不同之处在于它的处理方式.Hadoop 在本质上是一个批处理系统,数据被引入 Hadoop 文件系统 (HDFS ...
随机推荐
- redis安装使用
Redis是一个开源的使用ANSI C语言编写.遵守BSD协议.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API. 它通常被称为数据结构服务器,因为值(valu ...
- c/c++再学习:排序算法了解
1.冒泡排序 冒泡排序是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成. ...
- JMeter3.0启动日志报错WARN - org.jmeterplugins.repository.Plugin: Unable to load class解决方法
解决方法: 通过sh find-in-jars 'HlsSampler' -d /data/apache-jmeter-3.0/lib/ext/确定这个class文件在哪个jar包 由于find-in ...
- IDEA和eclipse快捷键
软件通用的快捷键: * 保存:Ctrl + S * 剪切:Ctrl + X * 粘贴:Ctrl + V * 复制:Ctrl + C * 全选:Ctlr + A * 撤销:Ctrl + Z * 反撤销: ...
- Chrome 无法自动填充密码
问题: chrome 同步一切正常,在密码管理器https://passwords.google.com 也能看到自己保存的密码 但是在 设置 - 密码中看不到保存的密码,只能看到 “一律不保存” 的 ...
- ConcurrentHashmap详解以及在JDK1.8的更新
因为hashmap本身是非线程安全的,如果多线程对hashmap进行put操作的话,就会导致死循环等现象.ConcurrentHashMap主要就是为了应对hashmap在并发环境下不安全而诞生的,C ...
- npm 安装cnpm淘宝镜像时报错解决
详细报错 D:\workspace\es61> npm install -g cnpm --registry=https://registry.npm.taobao.org npm WARN d ...
- Exp4 恶意代码分析 20164302 王一帆
1.实践目标 1.1监控自己系统的运行状态,看有没有可疑的程序在运行. 1.2分析一个恶意软件,就分析Exp2或Exp3中生成后门软件:分析工具尽量使用原生指令或sysinternals,systra ...
- 百度TTS的来由
#### https://home-assistant.io/components/tts.baidu/#### https://github.com/charleyzhu/HomeAssistant ...
- css3 图片阴影
box-shadow:1px 2px 4px #999999; 效果: