【Storm篇】--Storm并发机制
一、前述
为了提高Storm的并行能力,通常需要设置并行。
二、具体原理
1. Storm并行分为几个方面:
Worker – 进程
一个Topology拓扑会包含一个或多个Worker(每个Worker进程只能从属于一个特定的Topology)
这些Worker进程会并行跑在集群中不同的服务器上,即一个Topology拓扑其实是由并行运行在Storm集群中多台服务器上的进程所组成
Executor – 线程
Executor是由Worker进程中生成的一个线程
每个Worker进程中会运行拓扑当中的一个或多个Executor线程
一个Executor线程中可以执行一个或多个Task任务(默认每个Executor只执行一个Task任务),但是这些Task任务都是对应着同一个组件(Spout、Bolt)。
Task
实际执行数据处理的最小单元
每个task即为一个Spout或者一个Bolt
注意:
Task数量在整个Topology生命周期中保持不变,Executor数量可以变化或手动调整
(默认情况下,Task数量和Executor是相同的,即每个Executor线程中默认运行一个Task任务)
2.在程序中具体设置:
设置Worker进程数
Config.setNumWorkers(int workers)
设置Executor线程数
TopologyBuilder.setSpout(String id, IRichSpout spout, Number parallelism_hint)
TopologyBuilder.setBolt(String id, IRichBolt bolt, Number parallelism_hint)
:其中, parallelism_hint即为executor线程数
设置Task数量
ComponentConfigurationDeclarer.setNumTasks(Number val)
例:
Config conf = new Config() ;
conf.setNumWorkers(2);//设置worker数
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("spout", new MySpout(), 1);//设置线程数
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)//设置总共的task数这个Bolt任务的
.shuffleGrouping("blue-spout);
3.案例详解
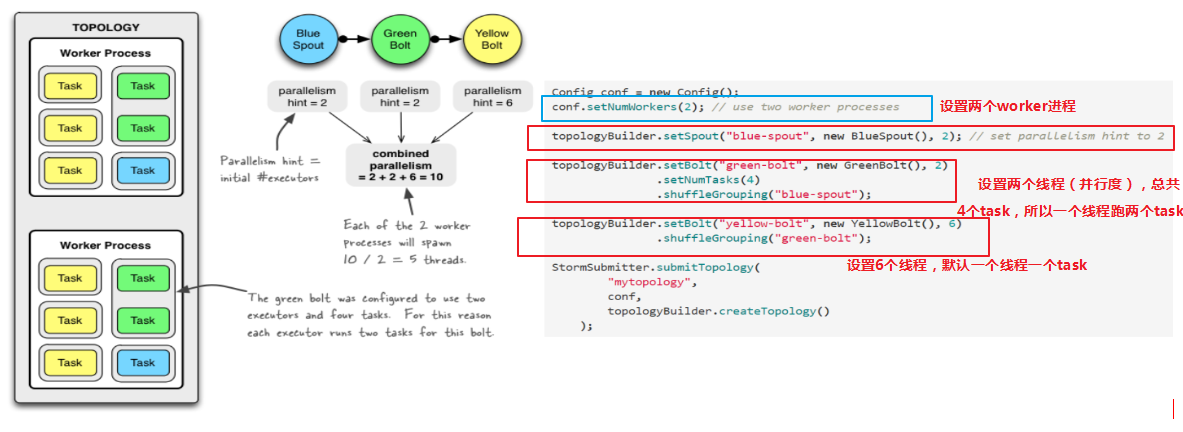
4.Rebalance – 再平衡
即,动态调整Topology拓扑的Worker进程数量、以及Executor线程数量
支持两种调整方式:
1、通过Storm UI
2、通过Storm CLI(一般用这个!!!)
通过Storm CLI动态调整:
例:storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
将mytopology拓扑worker进程数量调整为5个
“ blue-spout ” 所使用的线程数量调整为3个
“ yellow-bolt ”所使用的线程数量调整为10个
PS:当调整的task或者worker进程超过集群配置时,还是按集群最大配置运行。
【Storm篇】--Storm并发机制的更多相关文章
- Storm程序的并发机制(重点掌握)
概念 Workers (JVMs): 在一个物理节点上可以运行一个或多个独立的JVM 进程.一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上), 所以worker proc ...
- storm的并发机制
storm的并发机制 storm计算支持在多台机器上水平扩容,通过将计算切分为多个独立的tasks在集群上并发执行来实现. 一个task可以简单地理解:在集群某节点上运行的一个spout或者bolt实 ...
- Storm并发机制详解
本文可作为 <<Storm-分布式实时计算模式>>一书1.4节的读书笔记 在Storm中,一个task就可以理解为在集群中某个节点上运行的一个spout或者bolt实例. 记住 ...
- storm并发机制,通信机制,任务提交
一.storm的并发 (1)Workers(JVMs):在一个物理节点上可以运行一个或多个独立的JVM进程.一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上),所以work ...
- Storm内部的消息传递机制
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 一个Storm拓扑,就是一个复杂的多阶段的流式计算.Storm中的组件 ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- 【原】Storm 守护线程容错机制
Storm入门教程 1. Storm基础 Storm Storm主要特点 Storm基本概念 Storm调度器 Storm配置 Guaranteeing Message Processing(消息处理 ...
- Storm消息可靠处理机制
在很多应用场景中,分布式系统的可靠性保障尤其重要.比如电商平台中,客户的购买请求需要可靠处理,不能因为节点故障等原因丢失请求:比如告警系统中,产生的核心告警必须及时完整的知会监控人员,不能因为网络故障 ...
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- 【Storm篇】--Storm从初始到分布式搭建
一.前述 Storm是一个流式处理框架,相比较于SparkStreaming是一个微批处理框架,hadoop是一个批处理框架. 二 .搭建流程 1.集群规划 Nimbus Supervisor ...
随机推荐
- James Munkres Topology: Lemma 21.2 The sequence lemma
Lemma 21.2 (The sequence lemma) Let \(X\) be a topological space; let \(A \subset X\). If there is a ...
- 通过iis访问电脑文件
新公司没有开发环境,移动端项目,需要自己在手机上先进行查看效果,提供了一个方法iis,之前有听过,但是一直没有用过,今天来记录一下这个配置过程: 环境:win10 1.安装iis 控制面板——程序—— ...
- 打包ideaUI本地项目,以供本地使用
#首先我们要在本机进行一些配置 在本机配置环境变量(控制面板->高级系统设置->环境变量->) #用cmd检测是否配置成功 如果你在ideaUI里,配置好了之后.我们现在来打架包 # ...
- Pandas常用功能总结
1.读取.csv文件 df2 = pd.read_csv('beijingsale.csv', encoding='gb2312',index_col='id',sep='\t',header=Non ...
- Unreal 4 error 记录
1.打包出来的exe,黑屏 这种最大的可能是在“地图&模式中”将 Default Maps设置为自己的map,注意这里分为Editor Startup Map和Game Default Map ...
- 【ABP.Net】2.多数据库支持&&初始化数据库
abp默认连接的数据库是MSSQL,但是在开发过程中往往很多开发者不满足于mssql. 所以这里演示一下把mssql改成postgresql,来进行接下来的系统开发. abp的orm是用EF的.那么我 ...
- git 修改用户名和密码
初次运行 Git 前的配置 一般在新的系统上,我们都需要先配置下自己的 Git 工作环境.配置工作只需一次,以后升级时还会沿用现在的配置.当然,如果需要,你随时可以用相同的命令修改已有的配置. Git ...
- 如何让pandas表格直接转换为markdown表格
https://stackoverflow.com/questions/33181846/programmatically-convert-pandas-dataframe-to-markdown-t ...
- python中的矩阵、多维数组
2. 创建一般的多维数组 import numpy as np a = np.array([1,2,3], dtype=int) # 创建1*3维数组 array([1,2,3]) type(a ...
- connector for python实验
MySQL 是最流行的关系型数据库管理系统,如果你不熟悉 MySQL,可以阅读 MySQL 教程. 下面为大家介绍使用 mysql-connector 来连接使用 MySQL, mysql-conne ...